 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing LLMs for Joint Encoding of Linguistic Categories
Oct 28, 2023


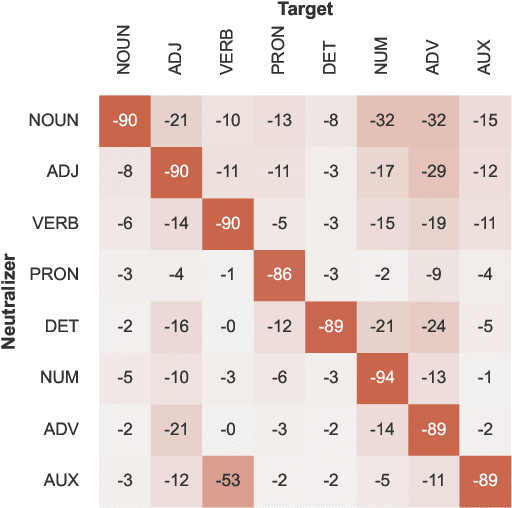
Large Language Models (LLMs) exhibit impressive performance on a range of NLP tasks, due to the general-purpose linguistic knowledge acquired during pretraining. Existing model interpretability research (Tenney et al., 2019) suggests that a linguistic hierarchy emerges in the LLM layers, with lower layers better suited to solving syntactic tasks and higher layers employed for semantic processing. Yet, little is known about how encodings of different linguistic phenomena interact within the models and to what extent processing of linguistically-related categories relies on the same, shared model representations. In this paper, we propose a framework for testing the joint encoding of linguistic categories in LLMs. Focusing on syntax, we find evidence of joint encoding both at the same (related part-of-speech (POS) classes) and different (POS classes and related syntactic dependency relations) levels of linguistic hierarchy. Our cross-lingual experiments show that the same patterns hold across languages in multilingual LLMs.
VISION DIFFMASK: Faithful Interpretation of Vision Transformers with Differentiable Patch Masking
Apr 13, 2023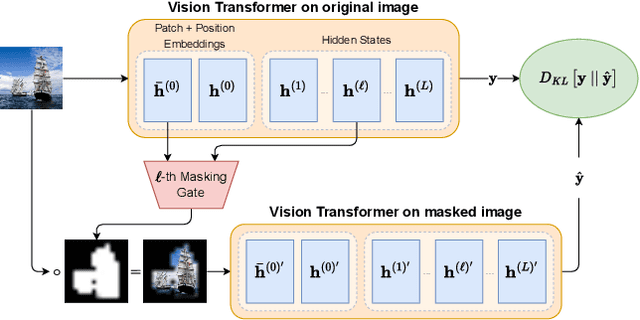
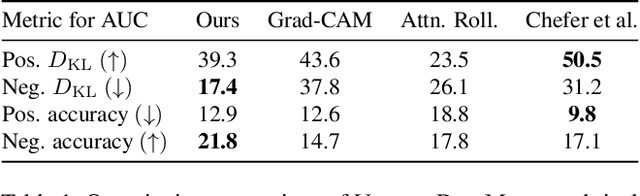


The lack of interpretability of the Vision Transformer may hinder its use in critical real-world applications despite its effectiveness. To overcome this issue, we propose a post-hoc interpretability method called VISION DIFFMASK, which uses the activations of the model's hidden layers to predict the relevant parts of the input that contribute to its final predictions. Our approach uses a gating mechanism to identify the minimal subset of the original input that preserves the predicted distribution over classes. We demonstrate the faithfulness of our method, by introducing a faithfulness task, and comparing it to other state-of-the-art attribution methods on CIFAR-10 and ImageNet-1K, achieving compelling results. To aid reproducibility and further extension of our work, we open source our implementation: https://github.com/AngelosNal/Vision-DiffMask
Leveraging Selective Prediction for Reliable Image Geolocation
Nov 23, 2021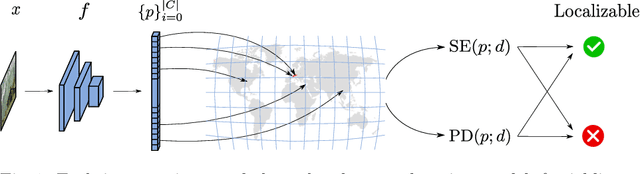
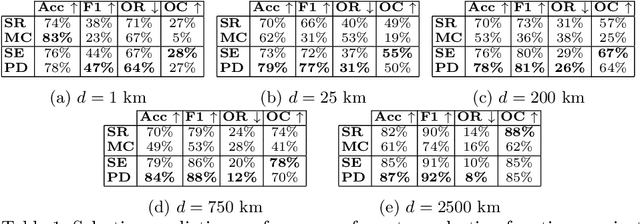

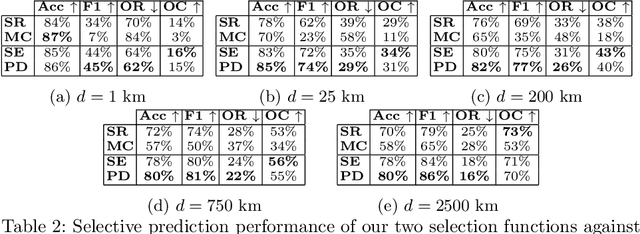
Reliable image geolocation is crucial for several applications, ranging from social media geo-tagging to fake news detection. State-of-the-art geolocation methods surpass human performance on the task of geolocation estimation from images. However, no method assesses the suitability of an image for this task, which results in unreliable and erroneous estimations for images containing no geolocation clues. In this paper, we define the task of image localizability, i.e. suitability of an image for geolocation, and propose a selective prediction methodology to address the task. In particular, we propose two novel selection functions that leverage the output probability distributions of geolocation models to infer localizability at different scales. Our selection functions are benchmarked against the most widely used selective prediction baselines, outperforming them in all cases. By abstaining from predicting non-localizable images, we improve geolocation accuracy from 27.8% to 70.5% at the city-scale, and thus make current geolocation models reliable for real-world applications.