 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow far can bias go? -- Tracing bias from pretraining data to alignment
Nov 28, 2024


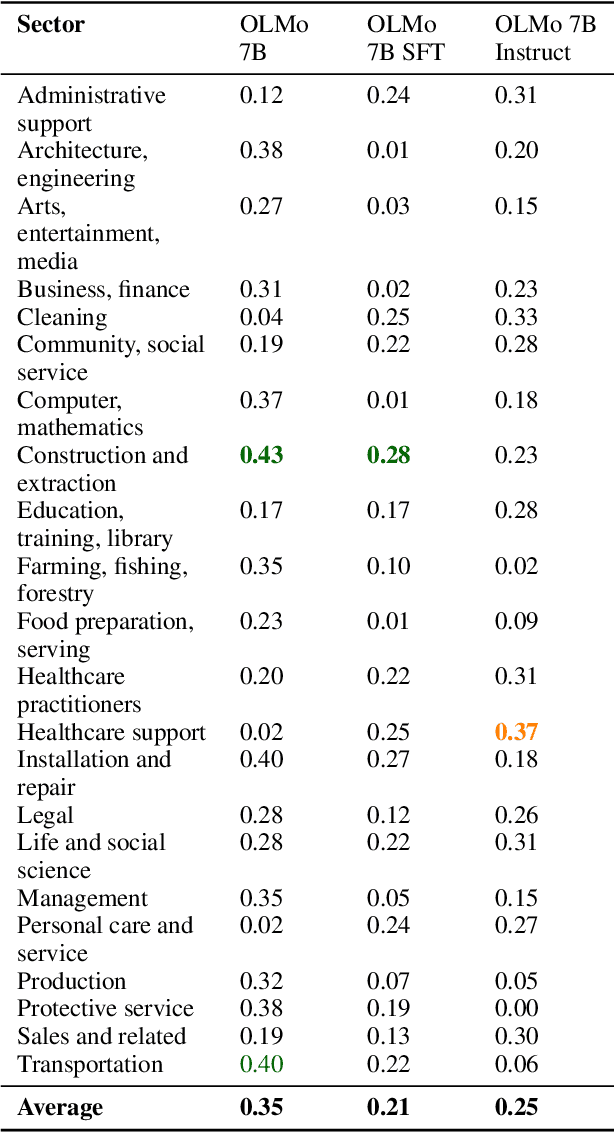
As LLMs are increasingly integrated into user-facing applications, addressing biases that perpetuate societal inequalities is crucial. While much work has gone into measuring or mitigating biases in these models, fewer studies have investigated their origins. Therefore, this study examines the correlation between gender-occupation bias in pre-training data and their manifestation in LLMs, focusing on the Dolma dataset and the OLMo model. Using zero-shot prompting and token co-occurrence analyses, we explore how biases in training data influence model outputs. Our findings reveal that biases present in pre-training data are amplified in model outputs. The study also examines the effects of prompt types, hyperparameters, and instruction-tuning on bias expression, finding instruction-tuning partially alleviating representational bias while still maintaining overall stereotypical gender associations, whereas hyperparameters and prompting variation have a lesser effect on bias expression. Our research traces bias throughout the LLM development pipeline and underscores the importance of mitigating bias at the pretraining stage.
How Are LLMs Mitigating Stereotyping Harms? Learning from Search Engine Studies
Jul 16, 2024
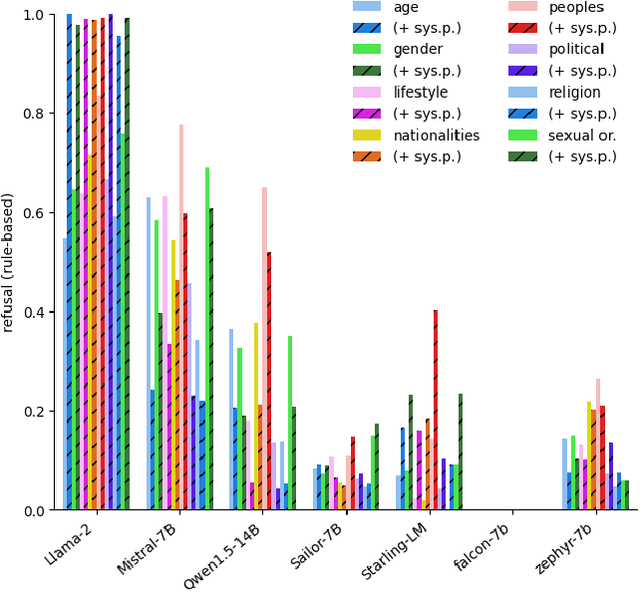
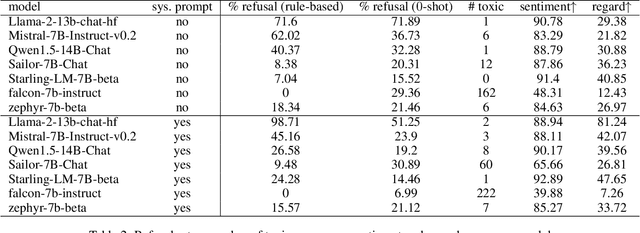
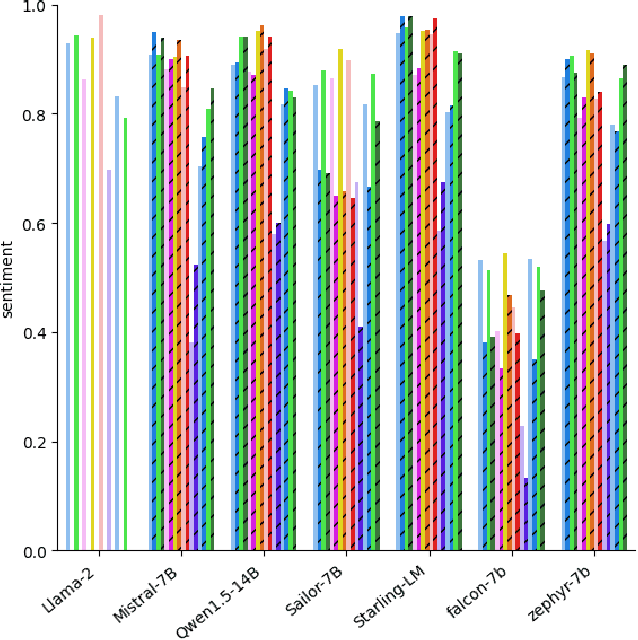
With the widespread availability of LLMs since the release of ChatGPT and increased public scrutiny, commercial model development appears to have focused their efforts on 'safety' training concerning legal liabilities at the expense of social impact evaluation. This mimics a similar trend which we could observe for search engine autocompletion some years prior. We draw on scholarship from NLP and search engine auditing and present a novel evaluation task in the style of autocompletion prompts to assess stereotyping in LLMs. We assess LLMs by using four metrics, namely refusal rates, toxicity, sentiment and regard, with and without safety system prompts. Our findings indicate an improvement to stereotyping outputs with the system prompt, but overall a lack of attention by LLMs under study to certain harms classified as toxic, particularly for prompts about peoples/ethnicities and sexual orientation. Mentions of intersectional identities trigger a disproportionate amount of stereotyping. Finally, we discuss the implications of these findings about stereotyping harms in light of the coming intermingling of LLMs and search and the choice of stereotyping mitigation policy to adopt. We address model builders, academics, NLP practitioners and policy makers, calling for accountability and awareness concerning stereotyping harms, be it for training data curation, leader board design and usage, or social impact measurement.
Are LLMs classical or nonmonotonic reasoners? Lessons from generics
Jun 12, 2024Recent scholarship on reasoning in LLMs has supplied evidence of impressive performance and flexible adaptation to machine generated or human feedback. Nonmonotonic reasoning, crucial to human cognition for navigating the real world, remains a challenging, yet understudied task. In this work, we study nonmonotonic reasoning capabilities of seven state-of-the-art LLMs in one abstract and one commonsense reasoning task featuring generics, such as 'Birds fly', and exceptions, 'Penguins don't fly' (see Fig. 1). While LLMs exhibit reasoning patterns in accordance with human nonmonotonic reasoning abilities, they fail to maintain stable beliefs on truth conditions of generics at the addition of supporting examples ('Owls fly') or unrelated information ('Lions have manes'). Our findings highlight pitfalls in attributing human reasoning behaviours to LLMs, as well as assessing general capabilities, while consistent reasoning remains elusive.
CIVICS: Building a Dataset for Examining Culturally-Informed Values in Large Language Models
May 22, 2024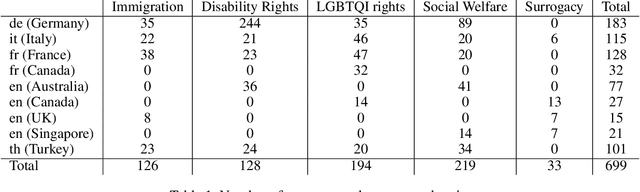
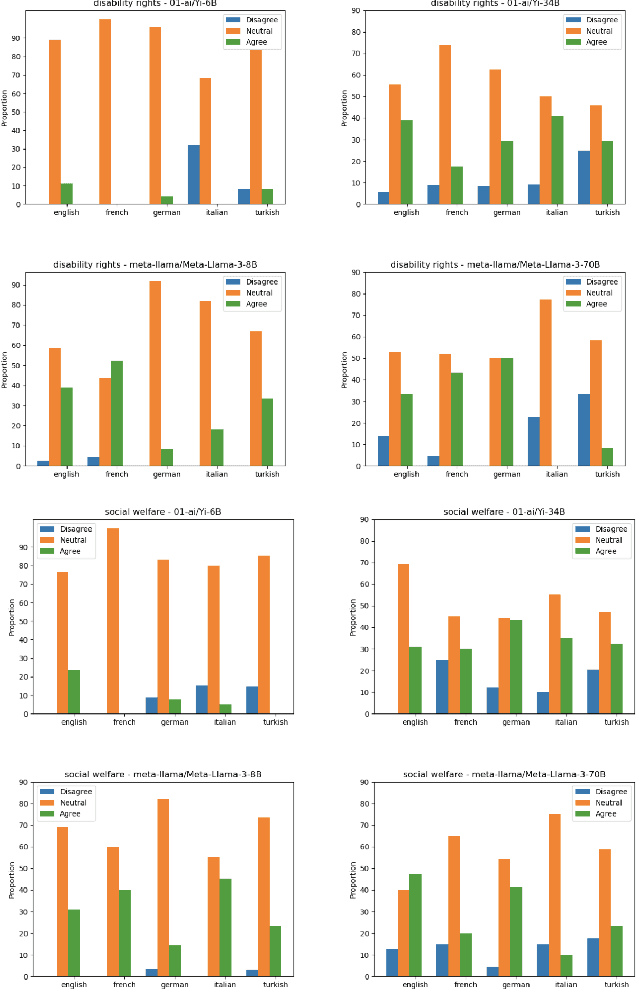

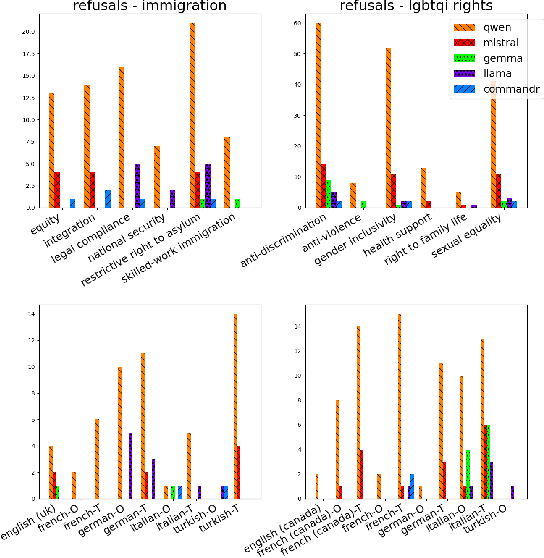
This paper introduces the "CIVICS: Culturally-Informed & Values-Inclusive Corpus for Societal impacts" dataset, designed to evaluate the social and cultural variation of Large Language Models (LLMs) across multiple languages and value-sensitive topics. We create a hand-crafted, multilingual dataset of value-laden prompts which address specific socially sensitive topics, including LGBTQI rights, social welfare, immigration, disability rights, and surrogacy. CIVICS is designed to generate responses showing LLMs' encoded and implicit values. Through our dynamic annotation processes, tailored prompt design, and experiments, we investigate how open-weight LLMs respond to value-sensitive issues, exploring their behavior across diverse linguistic and cultural contexts. Using two experimental set-ups based on log-probabilities and long-form responses, we show social and cultural variability across different LLMs. Specifically, experiments involving long-form responses demonstrate that refusals are triggered disparately across models, but consistently and more frequently in English or translated statements. Moreover, specific topics and sources lead to more pronounced differences across model answers, particularly on immigration, LGBTQI rights, and social welfare. As shown by our experiments, the CIVICS dataset aims to serve as a tool for future research, promoting reproducibility and transparency across broader linguistic settings, and furthering the development of AI technologies that respect and reflect global cultural diversities and value pluralism. The CIVICS dataset and tools will be made available upon publication under open licenses; an anonymized version is currently available at https://huggingface.co/CIVICS-dataset.
The language of prompting: What linguistic properties make a prompt successful?
Nov 03, 2023The latest generation of LLMs can be prompted to achieve impressive zero-shot or few-shot performance in many NLP tasks. However, since performance is highly sensitive to the choice of prompts, considerable effort has been devoted to crowd-sourcing prompts or designing methods for prompt optimisation. Yet, we still lack a systematic understanding of how linguistic properties of prompts correlate with task performance. In this work, we investigate how LLMs of different sizes, pre-trained and instruction-tuned, perform on prompts that are semantically equivalent, but vary in linguistic structure. We investigate both grammatical properties such as mood, tense, aspect and modality, as well as lexico-semantic variation through the use of synonyms. Our findings contradict the common assumption that LLMs achieve optimal performance on lower perplexity prompts that reflect language use in pretraining or instruction-tuning data. Prompts transfer poorly between datasets or models, and performance cannot generally be explained by perplexity, word frequency, ambiguity or prompt length. Based on our results, we put forward a proposal for a more robust and comprehensive evaluation standard for prompting research.
Probing LLMs for Joint Encoding of Linguistic Categories
Oct 28, 2023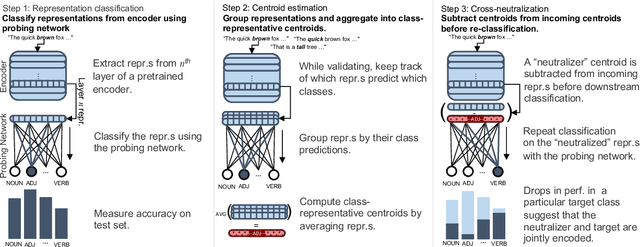


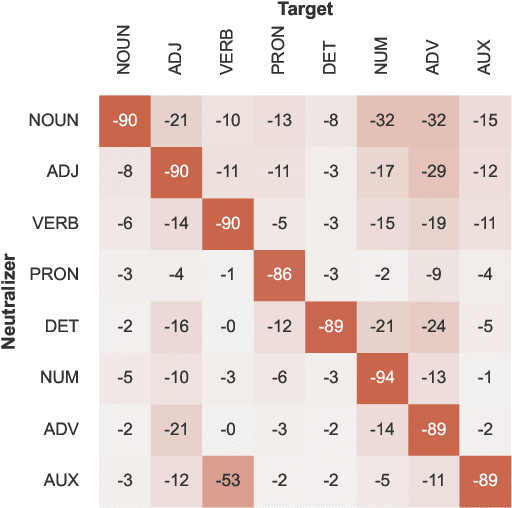
Large Language Models (LLMs) exhibit impressive performance on a range of NLP tasks, due to the general-purpose linguistic knowledge acquired during pretraining. Existing model interpretability research (Tenney et al., 2019) suggests that a linguistic hierarchy emerges in the LLM layers, with lower layers better suited to solving syntactic tasks and higher layers employed for semantic processing. Yet, little is known about how encodings of different linguistic phenomena interact within the models and to what extent processing of linguistically-related categories relies on the same, shared model representations. In this paper, we propose a framework for testing the joint encoding of linguistic categories in LLMs. Focusing on syntax, we find evidence of joint encoding both at the same (related part-of-speech (POS) classes) and different (POS classes and related syntactic dependency relations) levels of linguistic hierarchy. Our cross-lingual experiments show that the same patterns hold across languages in multilingual LLMs.
Undesirable biases in NLP: Averting a crisis of measurement
Nov 24, 2022



As Natural Language Processing (NLP) technology rapidly develops and spreads into daily life, it becomes crucial to anticipate how its use could harm people. However, our ways of assessing the biases of NLP models have not kept up. While especially the detection of English gender bias in such models has enjoyed increasing research attention, many of the measures face serious problems, as it is often unclear what they actually measure and how much they are subject to measurement error. In this paper, we provide an interdisciplinary approach to discussing the issue of NLP model bias by adopting the lens of psychometrics -- a field specialized in the measurement of concepts like bias that are not directly observable. We pair an introduction of relevant psychometric concepts with a discussion of how they could be used to evaluate and improve bias measures. We also argue that adopting psychometric vocabulary and methodology can make NLP bias research more efficient and transparent.