 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Attention by Overlap Interference: Predicting Sequences from Classical and Many-Body Quantum Data
Feb 06, 2026We propose a variational quantum implementation of self-attention (QSA), the core operation in transformers and large language models, which predicts future elements of a sequence by forming overlap-weighted combinations of past data. At variance with previous approaches, our QSA realizes the required nonlinearity through interference of state overlaps and returns a Renyi-1/2 cross-entropy loss directly as the expectation value of an observable, avoiding the need to decode amplitude-encoded predictions into classical logits. Furthermore, QSA naturally accommodates a constrained, trainable data-embedding that ties quantum state overlaps to data-level similarities. We find a gate complexity dominant scaling O(T d^2) for QSA, versus O(T^2 d) classically, suggesting an advantage in the practical regime where the sequence length T dominates the embedding size d. In simulations, we show that our QSA-based quantum transformer learns sequence prediction on classical data and on many-body transverse-field Ising quantum trajectories, establishing trainable attention as a practical primitive for quantum dynamical modeling.
Probing LLMs for Joint Encoding of Linguistic Categories
Oct 28, 2023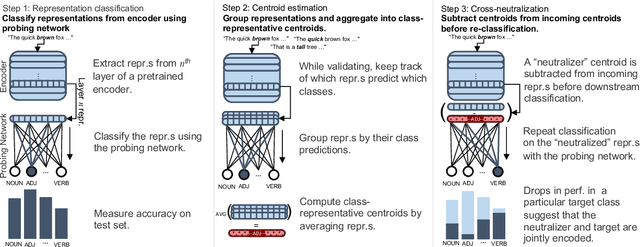


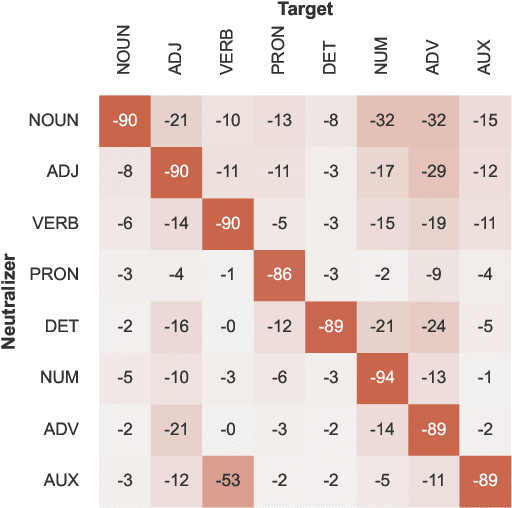
Large Language Models (LLMs) exhibit impressive performance on a range of NLP tasks, due to the general-purpose linguistic knowledge acquired during pretraining. Existing model interpretability research (Tenney et al., 2019) suggests that a linguistic hierarchy emerges in the LLM layers, with lower layers better suited to solving syntactic tasks and higher layers employed for semantic processing. Yet, little is known about how encodings of different linguistic phenomena interact within the models and to what extent processing of linguistically-related categories relies on the same, shared model representations. In this paper, we propose a framework for testing the joint encoding of linguistic categories in LLMs. Focusing on syntax, we find evidence of joint encoding both at the same (related part-of-speech (POS) classes) and different (POS classes and related syntactic dependency relations) levels of linguistic hierarchy. Our cross-lingual experiments show that the same patterns hold across languages in multilingual LLMs.
A learning theory for quantum photonic processors and beyond
Sep 07, 2022
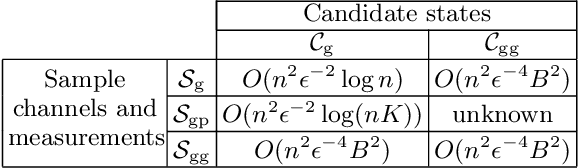
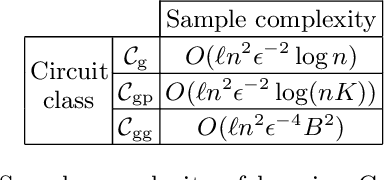
We consider the tasks of learning quantum states, measurements and channels generated by continuous-variable (CV) quantum circuits. This family of circuits is suited to describe optical quantum technologies and in particular it includes state-of-the-art photonic processors capable of showing quantum advantage. We define classes of functions that map classical variables, encoded into the CV circuit parameters, to outcome probabilities evaluated on those circuits. We then establish efficient learnability guarantees for such classes, by computing bounds on their pseudo-dimension or covering numbers, showing that CV quantum circuits can be learned with a sample complexity that scales polynomially with the circuit's size, i.e., the number of modes. Our results establish that CV circuits can be trained efficiently using a number of training samples that, unlike their finite-dimensional counterpart, does not scale with the circuit depth.
[Re] Badder Seeds: Reproducing the Evaluation of Lexical Methods for Bias Measurement
Jun 03, 2022![Figure 1 for [Re] Badder Seeds: Reproducing the Evaluation of Lexical Methods for Bias Measurement](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F10dc8987b46b59843b3b68e04c1346bd1fa8bde0%2F6-Figure1-1.png&w=640&q=75)
![Figure 2 for [Re] Badder Seeds: Reproducing the Evaluation of Lexical Methods for Bias Measurement](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F10dc8987b46b59843b3b68e04c1346bd1fa8bde0%2F6-Figure2-1.png&w=640&q=75)
![Figure 3 for [Re] Badder Seeds: Reproducing the Evaluation of Lexical Methods for Bias Measurement](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F10dc8987b46b59843b3b68e04c1346bd1fa8bde0%2F7-Figure3-1.png&w=640&q=75)
![Figure 4 for [Re] Badder Seeds: Reproducing the Evaluation of Lexical Methods for Bias Measurement](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F10dc8987b46b59843b3b68e04c1346bd1fa8bde0%2F7-Figure4-1.png&w=640&q=75)
Combating bias in NLP requires bias measurement. Bias measurement is almost always achieved by using lexicons of seed terms, i.e. sets of words specifying stereotypes or dimensions of interest. This reproducibility study focuses on the original authors' main claim that the rationale for the construction of these lexicons needs thorough checking before usage, as the seeds used for bias measurement can themselves exhibit biases. The study aims to evaluate the reproducibility of the quantitative and qualitative results presented in the paper and the conclusions drawn thereof. We reproduce most of the results supporting the original authors' general claim: seed sets often suffer from biases that affect their performance as a baseline for bias metrics. Generally, our results mirror the original paper's. They are slightly different on select occasions, but not in ways that undermine the paper's general intent to show the fragility of seed sets.
* 15 pages, 7 figures
Reinforcement-learning calibration of coherent-state receivers on variable-loss optical channels
Mar 18, 2022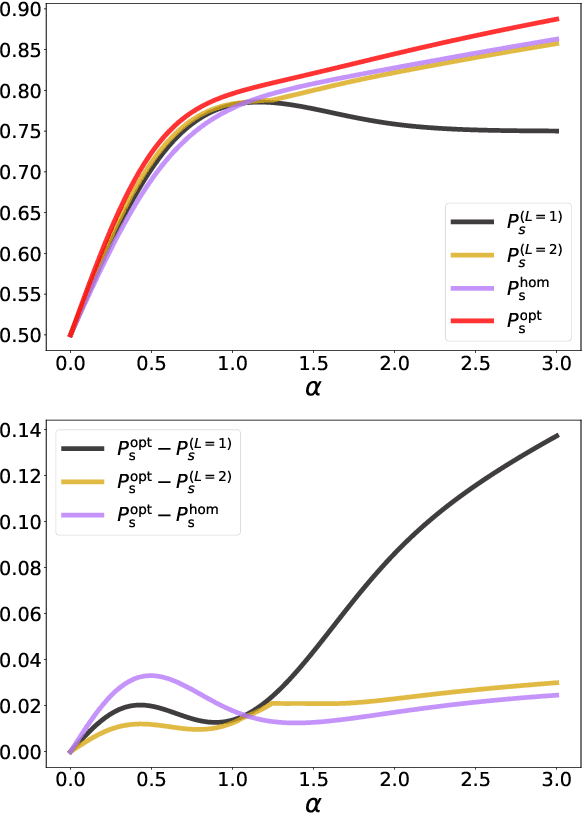
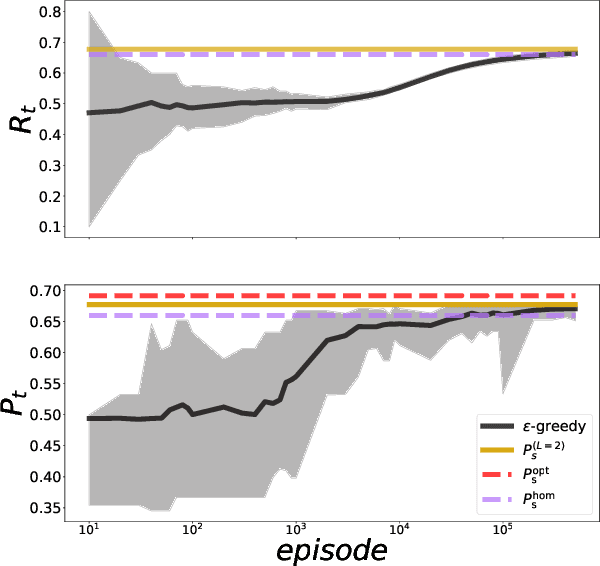
We study the problem of calibrating a quantum receiver for optical coherent states when transmitted on a quantum optical channel with variable transmissivity, a common model for long-distance optical-fiber and free/deep-space optical communication. We optimize the error probability of legacy adaptive receivers, such as Kennedy's and Dolinar's, on average with respect to the channel transmissivity distribution. We then compare our results with the ultimate error probability attainable by a general quantum device, computing the Helstrom bound for mixtures of coherent-state hypotheses, for the first time to our knowledge, and with homodyne measurements. With these tools, we first analyze the simplest case of two different transmissivity values; we find that the strategies adopted by adaptive receivers exhibit strikingly new features as the difference between the two transmissivities increases. Finally, we employ a recently introduced library of shallow reinforcement learning methods, demonstrating that an intelligent agent can learn the optimal receiver setup from scratch by training on repeated communication episodes on the channel with variable transmissivity and receiving rewards if the coherent-state message is correctly identified.