 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInRanker: Distilled Rankers for Zero-shot Information Retrieval
Jan 12, 2024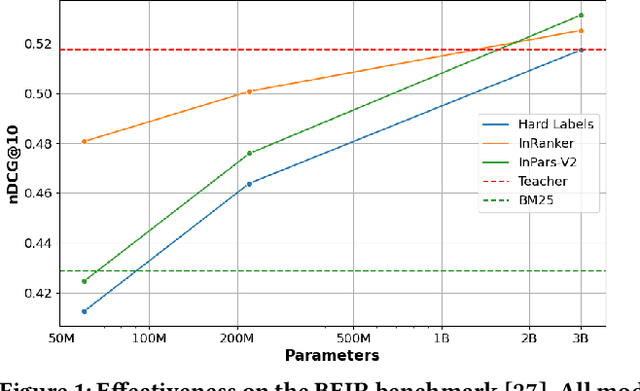
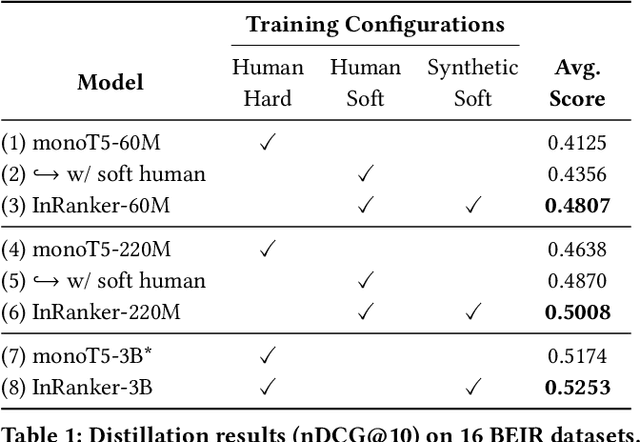
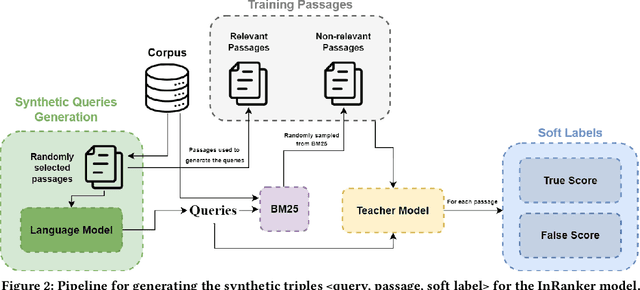
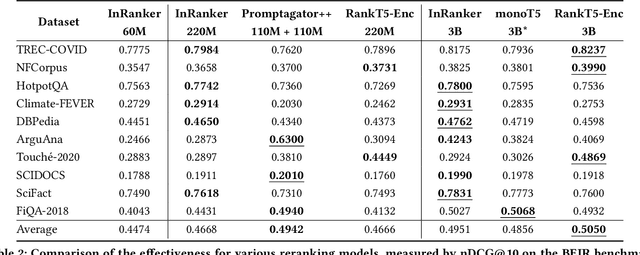
Despite multi-billion parameter neural rankers being common components of state-of-the-art information retrieval pipelines, they are rarely used in production due to the enormous amount of compute required for inference. In this work, we propose a new method for distilling large rankers into their smaller versions focusing on out-of-domain effectiveness. We introduce InRanker, a version of monoT5 distilled from monoT5-3B with increased effectiveness on out-of-domain scenarios. Our key insight is to use language models and rerankers to generate as much as possible synthetic "in-domain" training data, i.e., data that closely resembles the data that will be seen at retrieval time. The pipeline consists of two distillation phases that do not require additional user queries or manual annotations: (1) training on existing supervised soft teacher labels, and (2) training on teacher soft labels for synthetic queries generated using a large language model. Consequently, models like monoT5-60M and monoT5-220M improved their effectiveness by using the teacher's knowledge, despite being 50x and 13x smaller, respectively. Models and code are available at https://github.com/unicamp-dl/InRanker.
Probing LLMs for Joint Encoding of Linguistic Categories
Oct 28, 2023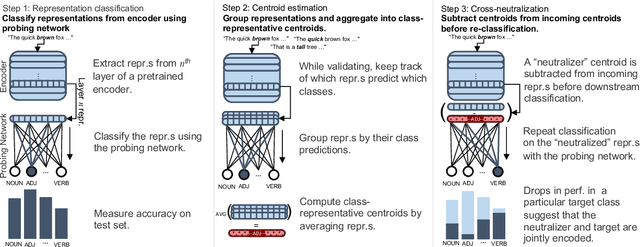


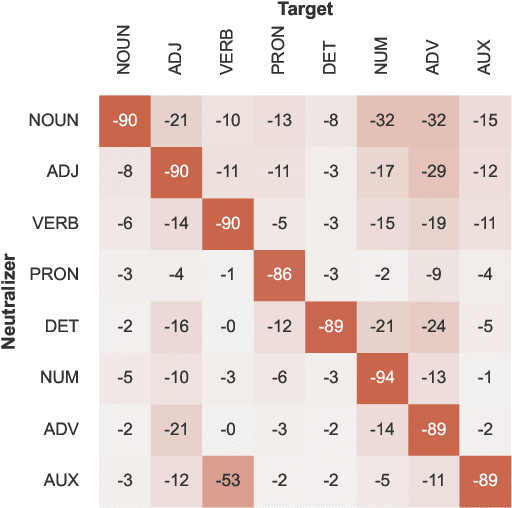
Large Language Models (LLMs) exhibit impressive performance on a range of NLP tasks, due to the general-purpose linguistic knowledge acquired during pretraining. Existing model interpretability research (Tenney et al., 2019) suggests that a linguistic hierarchy emerges in the LLM layers, with lower layers better suited to solving syntactic tasks and higher layers employed for semantic processing. Yet, little is known about how encodings of different linguistic phenomena interact within the models and to what extent processing of linguistically-related categories relies on the same, shared model representations. In this paper, we propose a framework for testing the joint encoding of linguistic categories in LLMs. Focusing on syntax, we find evidence of joint encoding both at the same (related part-of-speech (POS) classes) and different (POS classes and related syntactic dependency relations) levels of linguistic hierarchy. Our cross-lingual experiments show that the same patterns hold across languages in multilingual LLMs.
Model Analysis & Evaluation for Ambiguous Question Answering
May 21, 2023Ambiguous questions are a challenge for Question Answering models, as they require answers that cover multiple interpretations of the original query. To this end, these models are required to generate long-form answers that often combine conflicting pieces of information. Although recent advances in the field have shown strong capabilities in generating fluent responses, certain research questions remain unanswered. Does model/data scaling improve the answers' quality? Do automated metrics align with human judgment? To what extent do these models ground their answers in evidence? In this study, we aim to thoroughly investigate these aspects, and provide valuable insights into the limitations of the current approaches. To aid in reproducibility and further extension of our work, we open-source our code at https://github.com/din0s/ambig_lfqa.
VISION DIFFMASK: Faithful Interpretation of Vision Transformers with Differentiable Patch Masking
Apr 13, 2023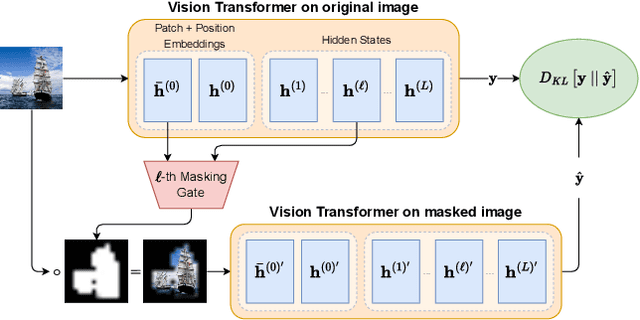
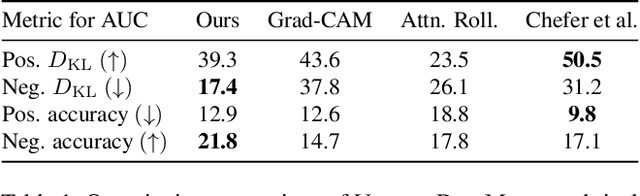


The lack of interpretability of the Vision Transformer may hinder its use in critical real-world applications despite its effectiveness. To overcome this issue, we propose a post-hoc interpretability method called VISION DIFFMASK, which uses the activations of the model's hidden layers to predict the relevant parts of the input that contribute to its final predictions. Our approach uses a gating mechanism to identify the minimal subset of the original input that preserves the predicted distribution over classes. We demonstrate the faithfulness of our method, by introducing a faithfulness task, and comparing it to other state-of-the-art attribution methods on CIFAR-10 and ImageNet-1K, achieving compelling results. To aid reproducibility and further extension of our work, we open source our implementation: https://github.com/AngelosNal/Vision-DiffMask