 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClarification as Supervision: Reinforcement Learning for Vision-Language Interfaces
Sep 30, 2025
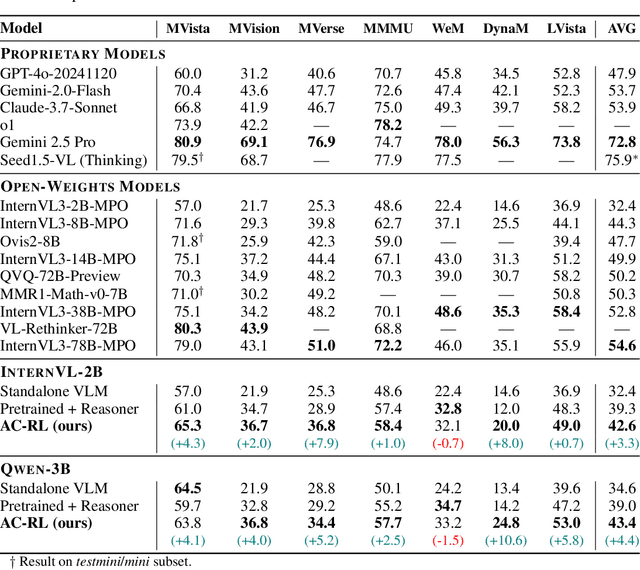

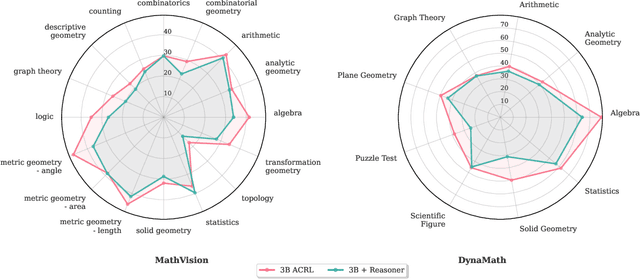
Recent text-only models demonstrate remarkable mathematical reasoning capabilities. Extending these to visual domains requires vision-language models to translate images into text descriptions. However, current models, trained to produce captions for human readers, often omit the precise details that reasoning systems require. This creates an interface mismatch: reasoners often fail not due to reasoning limitations but because they lack access to critical visual information. We propose Adaptive-Clarification Reinforcement Learning (AC-RL), which teaches vision models what information reasoners need through interaction. Our key insight is that clarification requests during training reveal information gaps; by penalizing success that requires clarification, we create pressure for comprehensive initial captions that enable the reasoner to solve the problem in a single pass. AC-RL improves average accuracy by 4.4 points over pretrained baselines across seven visual mathematical reasoning benchmarks, and analysis shows it would cut clarification requests by up to 39% if those were allowed. By treating clarification as a form of implicit supervision, AC-RL demonstrates that vision-language interfaces can be effectively learned through interaction alone, without requiring explicit annotations.
Language Agents Meet Causality -- Bridging LLMs and Causal World Models
Oct 25, 2024Large Language Models (LLMs) have recently shown great promise in planning and reasoning applications. These tasks demand robust systems, which arguably require a causal understanding of the environment. While LLMs can acquire and reflect common sense causal knowledge from their pretraining data, this information is often incomplete, incorrect, or inapplicable to a specific environment. In contrast, causal representation learning (CRL) focuses on identifying the underlying causal structure within a given environment. We propose a framework that integrates CRLs with LLMs to enable causally-aware reasoning and planning. This framework learns a causal world model, with causal variables linked to natural language expressions. This mapping provides LLMs with a flexible interface to process and generate descriptions of actions and states in text form. Effectively, the causal world model acts as a simulator that the LLM can query and interact with. We evaluate the framework on causal inference and planning tasks across temporal scales and environmental complexities. Our experiments demonstrate the effectiveness of the approach, with the causally-aware method outperforming LLM-based reasoners, especially for longer planning horizons.
INT2.1: Towards Fine-Tunable Quantized Large Language Models with Error Correction through Low-Rank Adaptation
Jun 13, 2023



We introduce a method that dramatically reduces fine-tuning VRAM requirements and rectifies quantization errors in quantized Large Language Models. First, we develop an extremely memory-efficient fine-tuning (EMEF) method for quantized models using Low-Rank Adaptation (LoRA), and drawing upon it, we construct an error-correcting algorithm designed to minimize errors induced by the quantization process. Our method reduces the memory requirements by up to 5.6 times, which enables fine-tuning a 7 billion parameter Large Language Model (LLM) on consumer laptops. At the same time, we propose a Low-Rank Error Correction (LREC) method that exploits the added LoRA layers to ameliorate the gap between the quantized model and its float point counterpart. Our error correction framework leads to a fully functional INT2 quantized LLM with the capacity to generate coherent English text. To the best of our knowledge, this is the first INT2 Large Language Model that has been able to reach such a performance. The overhead of our method is merely a 1.05 times increase in model size, which translates to an effective precision of INT2.1. Also, our method readily generalizes to other quantization standards, such as INT3, INT4, and INT8, restoring their lost performance, which marks a significant milestone in the field of model quantization. The strategies delineated in this paper hold promising implications for the future development and optimization of quantized models, marking a pivotal shift in the landscape of low-resource machine learning computations.
VISION DIFFMASK: Faithful Interpretation of Vision Transformers with Differentiable Patch Masking
Apr 13, 2023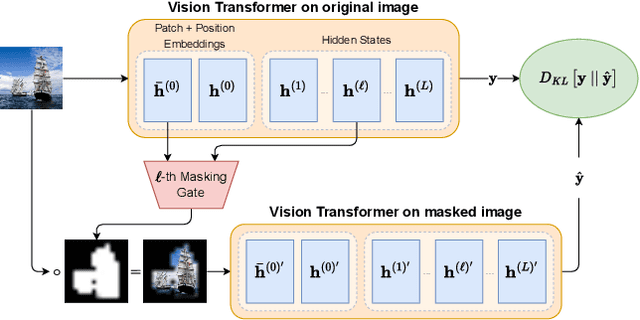
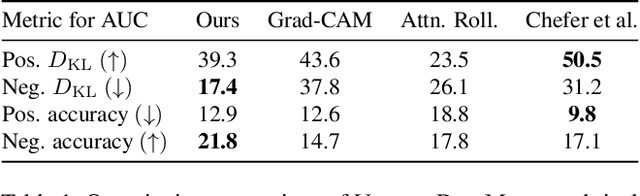


The lack of interpretability of the Vision Transformer may hinder its use in critical real-world applications despite its effectiveness. To overcome this issue, we propose a post-hoc interpretability method called VISION DIFFMASK, which uses the activations of the model's hidden layers to predict the relevant parts of the input that contribute to its final predictions. Our approach uses a gating mechanism to identify the minimal subset of the original input that preserves the predicted distribution over classes. We demonstrate the faithfulness of our method, by introducing a faithfulness task, and comparing it to other state-of-the-art attribution methods on CIFAR-10 and ImageNet-1K, achieving compelling results. To aid reproducibility and further extension of our work, we open source our implementation: https://github.com/AngelosNal/Vision-DiffMask