 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's Holding Back Latent Visual Reasoning?
May 19, 2026Humans can approach complex visual problems by mentally simulating intermediate visual steps, rather than reasoning through language alone. Inspired by this, several works on Vision-Language Models have recently explored chain-of-thought reasoning with continuous latent tokens as intermediate visual imagination steps. In this work, we investigate how recent models leverage such latent tokens. Surprisingly, we find that model accuracy is unaffected when latent tokens are replaced by uninformative dummy tokens. This indicates that latent tokens play a minimal causal role in the model's final prediction. To better understand this phenomenon, we analyze both the training signal provided by oracle latent representations and the quality of the latent tokens generated at inference time. Our experiments reveal two crucial issues holding back latent visual reasoning: First, in most existing datasets, oracle latent tokens provide limited additional information beyond the original image and do not substantially simplify the task, leading models to ignore them during training and effectively bypassing them at inference time. When fine-tuned on a diagnostic dataset, in which latent tokens provide sufficient support for the final prediction, we show that models can causally rely on them. Second, the latent tokens produced at inference time deviate from their corresponding oracle representations, collapsing to a narrow region and preventing benefits even when the model relies on them. Overall, our findings suggest that future progress in latent visual reasoning depends on two key pillars: high-quality datasets with informative intermediate steps and more precise latent token prediction.
LanteRn: Latent Visual Structured Reasoning
Mar 26, 2026While language reasoning models excel in many tasks, visual reasoning remains challenging for current large multimodal models (LMMs). As a result, most LMMs default to verbalizing perceptual content into text, a strong limitation for tasks requiring fine-grained spatial and visual understanding. While recent approaches take steps toward thinking with images by invoking tools or generating intermediate images, they either rely on external modules, or incur unnecessary computation by reasoning directly in pixel space. In this paper, we introduce LanteRn, a framework that enables LMMs to interleave language with compact latent visual representations, allowing visual reasoning to occur directly in latent space. LanteRn augments a vision-language transformer with the ability to generate and attend to continuous visual thought embeddings during inference. We train the model in two stages: supervised fine-tuning to ground visual features in latent states, followed by reinforcement learning to align latent reasoning with task-level utility. We evaluate LanteRn on three perception-centric benchmarks (VisCoT, V*, and Blink), observing consistent improvements in visual grounding and fine-grained reasoning. These results suggest that internal latent representations provide a promising direction for more efficient multimodal reasoning.
Language Agents Meet Causality -- Bridging LLMs and Causal World Models
Oct 25, 2024Large Language Models (LLMs) have recently shown great promise in planning and reasoning applications. These tasks demand robust systems, which arguably require a causal understanding of the environment. While LLMs can acquire and reflect common sense causal knowledge from their pretraining data, this information is often incomplete, incorrect, or inapplicable to a specific environment. In contrast, causal representation learning (CRL) focuses on identifying the underlying causal structure within a given environment. We propose a framework that integrates CRLs with LLMs to enable causally-aware reasoning and planning. This framework learns a causal world model, with causal variables linked to natural language expressions. This mapping provides LLMs with a flexible interface to process and generate descriptions of actions and states in text form. Effectively, the causal world model acts as a simulator that the LLM can query and interact with. We evaluate the framework on causal inference and planning tasks across temporal scales and environmental complexities. Our experiments demonstrate the effectiveness of the approach, with the causally-aware method outperforming LLM-based reasoners, especially for longer planning horizons.
Strengthening Structural Inductive Biases by Pre-training to Perform Syntactic Transformations
Jul 05, 2024Models need appropriate inductive biases to effectively learn from small amounts of data and generalize systematically outside of the training distribution. While Transformers are highly versatile and powerful, they can still benefit from enhanced structural inductive biases for seq2seq tasks, especially those involving syntactic transformations, such as converting active to passive voice or semantic parsing. In this paper, we propose to strengthen the structural inductive bias of a Transformer by intermediate pre-training to perform synthetically generated syntactic transformations of dependency trees given a description of the transformation. Our experiments confirm that this helps with few-shot learning of syntactic tasks such as chunking, and also improves structural generalization for semantic parsing. Our analysis shows that the intermediate pre-training leads to attention heads that keep track of which syntactic transformation needs to be applied to which token, and that the model can leverage these attention heads on downstream tasks.
Cache & Distil: Optimising API Calls to Large Language Models
Oct 20, 2023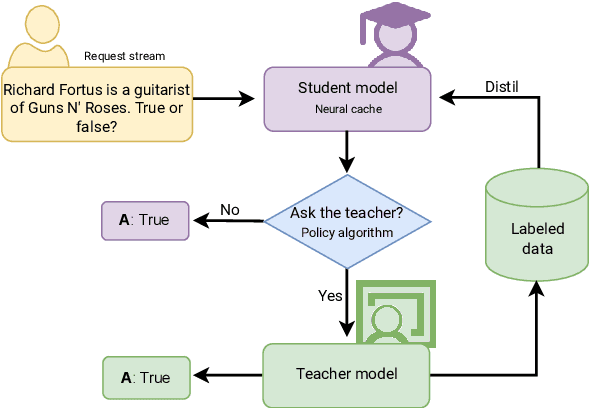
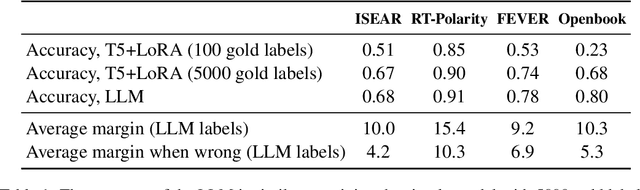


Large-scale deployment of generative AI tools often depends on costly API calls to a Large Language Model (LLM) to fulfil user queries. To curtail the frequency of these calls, one can employ a smaller language model -- a student -- which is continuously trained on the responses of the LLM. This student gradually gains proficiency in independently handling an increasing number of user requests, a process we term neural caching. The crucial element in neural caching is a policy that decides which requests should be processed by the student alone and which should be redirected to the LLM, subsequently aiding the student's learning. In this study, we focus on classification tasks, and we consider a range of classic active learning-based selection criteria as the policy. Our experiments suggest that Margin Sampling and Query by Committee bring consistent benefits across tasks and budgets.
Injecting a Structural Inductive Bias into a Seq2Seq Model by Simulation
Oct 01, 2023Strong inductive biases enable learning from little data and help generalization outside of the training distribution. Popular neural architectures such as Transformers lack strong structural inductive biases for seq2seq NLP tasks on their own. Consequently, they struggle with systematic generalization beyond the training distribution, e.g. with extrapolating to longer inputs, even when pre-trained on large amounts of text. We show how a structural inductive bias can be injected into a seq2seq model by pre-training it to simulate structural transformations on synthetic data. Specifically, we inject an inductive bias towards Finite State Transducers (FSTs) into a Transformer by pre-training it to simulate FSTs given their descriptions. Our experiments show that our method imparts the desired inductive bias, resulting in improved systematic generalization and better few-shot learning for FST-like tasks.
Compositional Generalization without Trees using Multiset Tagging and Latent Permutations
May 26, 2023Seq2seq models have been shown to struggle with compositional generalization in semantic parsing, i.e. generalizing to unseen compositions of phenomena that the model handles correctly in isolation. We phrase semantic parsing as a two-step process: we first tag each input token with a multiset of output tokens. Then we arrange the tokens into an output sequence using a new way of parameterizing and predicting permutations. We formulate predicting a permutation as solving a regularized linear program and we backpropagate through the solver. In contrast to prior work, our approach does not place a priori restrictions on possible permutations, making it very expressive. Our model outperforms pretrained seq2seq models and prior work on realistic semantic parsing tasks that require generalization to longer examples. We also outperform non-tree-based models on structural generalization on the COGS benchmark. For the first time, we show that a model without an inductive bias provided by trees achieves high accuracy on generalization to deeper recursion.
Compositional Generalisation with Structured Reordering and Fertility Layers
Oct 06, 2022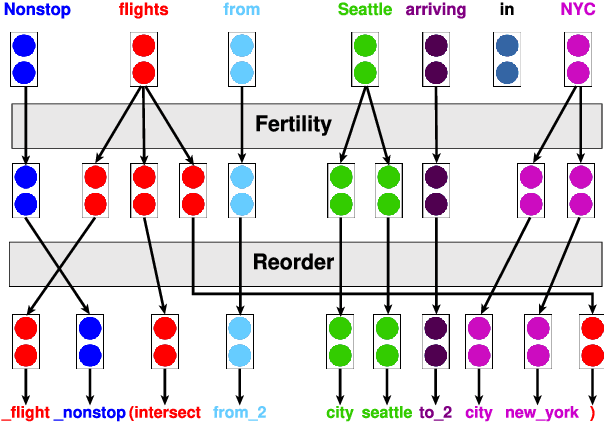

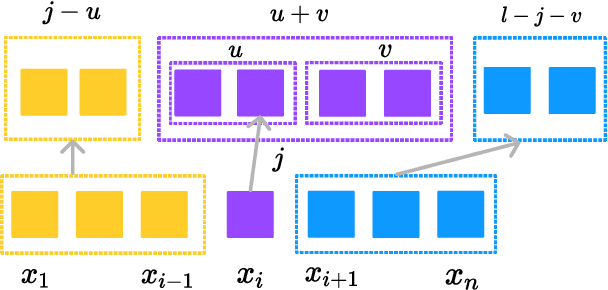

Seq2seq models have been shown to struggle with compositional generalisation, i.e. generalising to new and potentially more complex structures than seen during training. Taking inspiration from grammar-based models that excel at compositional generalisation, we present a flexible end-to-end differentiable neural model that composes two structural operations: a fertility step, which we introduce in this work, and a reordering step based on previous work (Wang et al., 2021). Our model outperforms seq2seq models by a wide margin on challenging compositional splits of realistic semantic parsing tasks that require generalisation to longer examples. It also compares favourably to other models targeting compositional generalisation.
Fast semantic parsing with well-typedness guarantees
Oct 06, 2020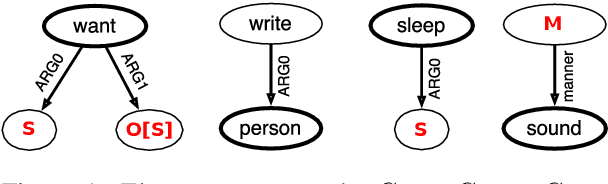
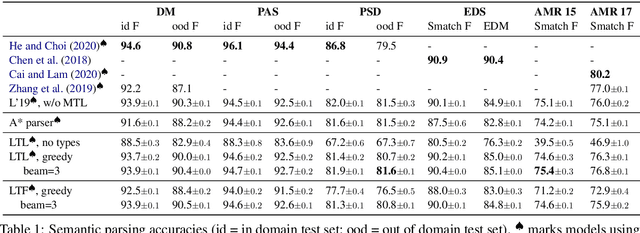


AM dependency parsing is a linguistically principled method for neural semantic parsing with high accuracy across multiple graphbanks. It relies on a type system that models semantic valency but makes existing parsers slow. We describe an A* parser and a transition-based parser for AM dependency parsing which guarantee well-typedness and improve parsing speed by up to 3 orders of magnitude, while maintaining or improving accuracy.
Normalizing Compositional Structures Across Graphbanks
Apr 30, 2020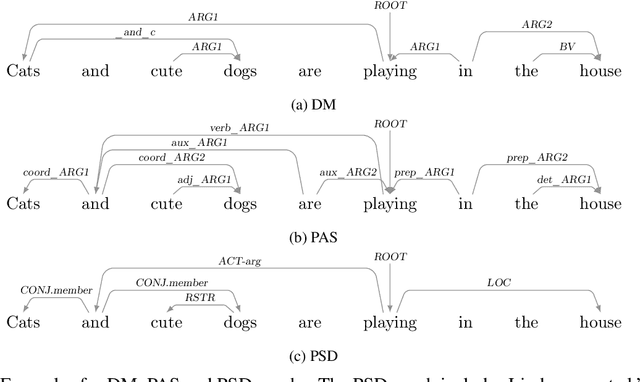
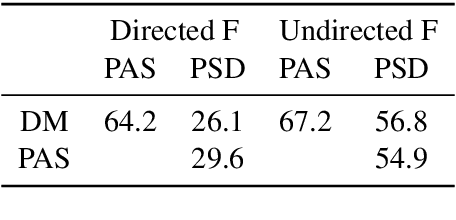

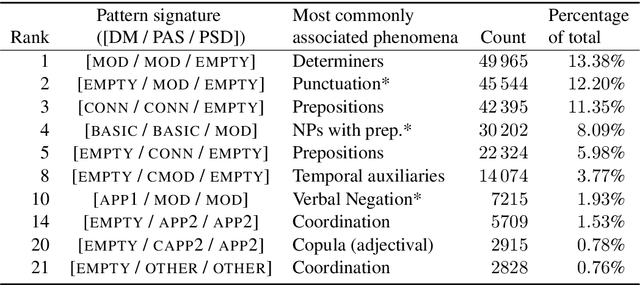
The emergence of a variety of graph-based meaning representations (MRs) has sparked an important conversation about how to adequately represent semantic structure. These MRs exhibit structural differences that reflect different theoretical and design considerations, presenting challenges to uniform linguistic analysis and cross-framework semantic parsing. Here, we ask the question of which design differences between MRs are meaningful and semantically-rooted, and which are superficial. We present a methodology for normalizing discrepancies between MRs at the compositional level (Lindemann et al., 2019), finding that we can normalize the majority of divergent phenomena using linguistically-grounded rules. Our work significantly increases the match in compositional structure between MRs and improves multi-task learning (MTL) in a low-resource setting, demonstrating the usefulness of careful MR design analysis and comparison.