 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiled Flash Linear Attention: More Efficient Linear RNN and xLSTM Kernels
Mar 18, 2025Linear RNNs with gating recently demonstrated competitive performance compared to Transformers in language modeling. Although their linear compute scaling in sequence length offers theoretical runtime advantages over Transformers, realizing these benefits in practice requires optimized custom kernels, as Transformers rely on the highly efficient Flash Attention kernels. Leveraging the chunkwise-parallel formulation of linear RNNs, Flash Linear Attention (FLA) shows that linear RNN kernels are faster than Flash Attention, by parallelizing over chunks of the input sequence. However, since the chunk size of FLA is limited, many intermediate states must be materialized in GPU memory. This leads to low arithmetic intensity and causes high memory consumption and IO cost, especially for long-context pre-training. In this work, we present Tiled Flash Linear Attention (TFLA), a novel kernel algorithm for linear RNNs, that enables arbitrary large chunk sizes by introducing an additional level of sequence parallelization within each chunk. First, we apply TFLA to the xLSTM with matrix memory, the mLSTM. Second, we propose an mLSTM variant with sigmoid input gate and reduced computation for even faster kernel runtimes at equal language modeling performance. In our speed benchmarks, we show that our new mLSTM kernels based on TFLA outperform highly optimized Flash Attention, Linear Attention and Mamba kernels, setting a new state of the art for efficient long-context sequence modeling primitives.
xLSTM 7B: A Recurrent LLM for Fast and Efficient Inference
Mar 17, 2025Recent breakthroughs in solving reasoning, math and coding problems with Large Language Models (LLMs) have been enabled by investing substantial computation budgets at inference time. Therefore, inference speed is one of the most critical properties of LLM architectures, and there is a growing need for LLMs that are efficient and fast at inference. Recently, LLMs built on the xLSTM architecture have emerged as a powerful alternative to Transformers, offering linear compute scaling with sequence length and constant memory usage, both highly desirable properties for efficient inference. However, such xLSTM-based LLMs have yet to be scaled to larger models and assessed and compared with respect to inference speed and efficiency. In this work, we introduce xLSTM 7B, a 7-billion-parameter LLM that combines xLSTM's architectural benefits with targeted optimizations for fast and efficient inference. Our experiments demonstrate that xLSTM 7B achieves performance on downstream tasks comparable to other similar-sized LLMs, while providing significantly faster inference speeds and greater efficiency compared to Llama- and Mamba-based LLMs. These results establish xLSTM 7B as the fastest and most efficient 7B LLM, offering a solution for tasks that require large amounts of test-time computation. Our work highlights xLSTM's potential as a foundational architecture for methods building on heavy use of LLM inference. Our model weights, model code and training code are open-source.
Language Agents Meet Causality -- Bridging LLMs and Causal World Models
Oct 25, 2024Large Language Models (LLMs) have recently shown great promise in planning and reasoning applications. These tasks demand robust systems, which arguably require a causal understanding of the environment. While LLMs can acquire and reflect common sense causal knowledge from their pretraining data, this information is often incomplete, incorrect, or inapplicable to a specific environment. In contrast, causal representation learning (CRL) focuses on identifying the underlying causal structure within a given environment. We propose a framework that integrates CRLs with LLMs to enable causally-aware reasoning and planning. This framework learns a causal world model, with causal variables linked to natural language expressions. This mapping provides LLMs with a flexible interface to process and generate descriptions of actions and states in text form. Effectively, the causal world model acts as a simulator that the LLM can query and interact with. We evaluate the framework on causal inference and planning tasks across temporal scales and environmental complexities. Our experiments demonstrate the effectiveness of the approach, with the causally-aware method outperforming LLM-based reasoners, especially for longer planning horizons.
NARAIM: Native Aspect Ratio Autoregressive Image Models
Oct 13, 2024
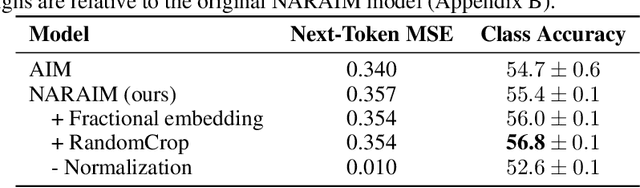
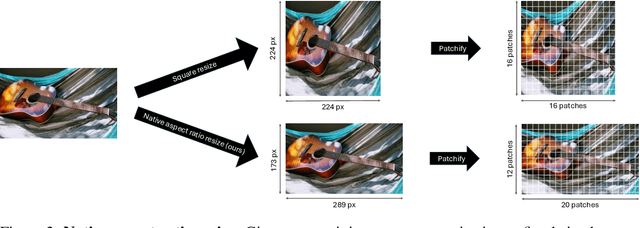
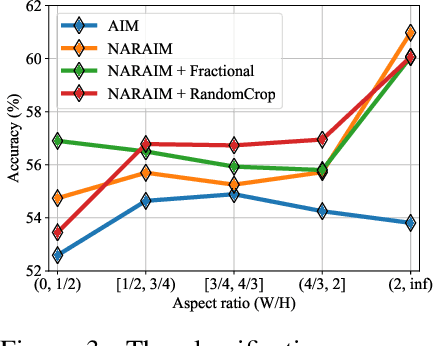
While vision transformers are able to solve a wide variety of computer vision tasks, no pre-training method has yet demonstrated the same scaling laws as observed in language models. Autoregressive models show promising results, but are commonly trained on images that are cropped or transformed into square images, which distorts or destroys information present in the input. To overcome this limitation, we propose NARAIM, a vision model pre-trained with an autoregressive objective that uses images in their native aspect ratio. By maintaining the native aspect ratio, we preserve the original spatial context, thereby enhancing the model's ability to interpret visual information. In our experiments, we show that maintaining the aspect ratio improves performance on a downstream classification task.
Towards the Reusability and Compositionality of Causal Representations
Mar 14, 2024



Causal Representation Learning (CRL) aims at identifying high-level causal factors and their relationships from high-dimensional observations, e.g., images. While most CRL works focus on learning causal representations in a single environment, in this work we instead propose a first step towards learning causal representations from temporal sequences of images that can be adapted in a new environment, or composed across multiple related environments. In particular, we introduce DECAF, a framework that detects which causal factors can be reused and which need to be adapted from previously learned causal representations. Our approach is based on the availability of intervention targets, that indicate which variables are perturbed at each time step. Experiments on three benchmark datasets show that integrating our framework with four state-of-the-art CRL approaches leads to accurate representations in a new environment with only a few samples.
How to Train Neural Field Representations: A Comprehensive Study and Benchmark
Dec 16, 2023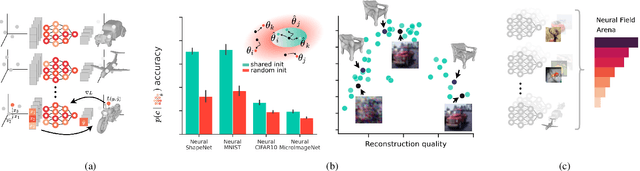
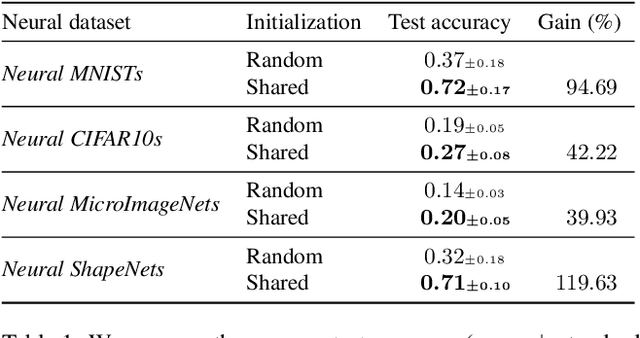


Neural fields (NeFs) have recently emerged as a versatile method for modeling signals of various modalities, including images, shapes, and scenes. Subsequently, a number of works have explored the use of NeFs as representations for downstream tasks, e.g. classifying an image based on the parameters of a NeF that has been fit to it. However, the impact of the NeF hyperparameters on their quality as downstream representation is scarcely understood and remains largely unexplored. This is in part caused by the large amount of time required to fit datasets of neural fields. In this work, we propose $\verb|fit-a-nef|$, a JAX-based library that leverages parallelization to enable fast optimization of large-scale NeF datasets, resulting in a significant speed-up. With this library, we perform a comprehensive study that investigates the effects of different hyperparameters -- including initialization, network architecture, and optimization strategies -- on fitting NeFs for downstream tasks. Our study provides valuable insights on how to train NeFs and offers guidance for optimizing their effectiveness in downstream applications. Finally, based on the proposed library and our analysis, we propose Neural Field Arena, a benchmark consisting of neural field variants of popular vision datasets, including MNIST, CIFAR, variants of ImageNet, and ShapeNetv2. Our library and the Neural Field Arena will be open-sourced to introduce standardized benchmarking and promote further research on neural fields.
PDE-Refiner: Achieving Accurate Long Rollouts with Neural PDE Solvers
Aug 10, 2023
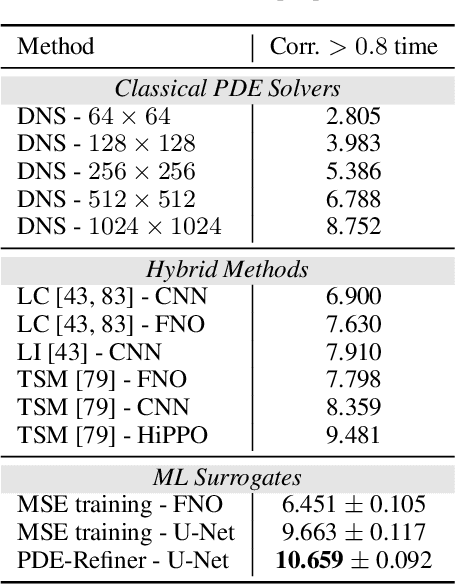


Time-dependent partial differential equations (PDEs) are ubiquitous in science and engineering. Recently, mostly due to the high computational cost of traditional solution techniques, deep neural network based surrogates have gained increased interest. The practical utility of such neural PDE solvers relies on their ability to provide accurate, stable predictions over long time horizons, which is a notoriously hard problem. In this work, we present a large-scale analysis of common temporal rollout strategies, identifying the neglect of non-dominant spatial frequency information, often associated with high frequencies in PDE solutions, as the primary pitfall limiting stable, accurate rollout performance. Based on these insights, we draw inspiration from recent advances in diffusion models to introduce PDE-Refiner; a novel model class that enables more accurate modeling of all frequency components via a multistep refinement process. We validate PDE-Refiner on challenging benchmarks of complex fluid dynamics, demonstrating stable and accurate rollouts that consistently outperform state-of-the-art models, including neural, numerical, and hybrid neural-numerical architectures. We further demonstrate that PDE-Refiner greatly enhances data efficiency, since the denoising objective implicitly induces a novel form of spectral data augmentation. Finally, PDE-Refiner's connection to diffusion models enables an accurate and efficient assessment of the model's predictive uncertainty, allowing us to estimate when the surrogate becomes inaccurate.
BISCUIT: Causal Representation Learning from Binary Interactions
Jun 16, 2023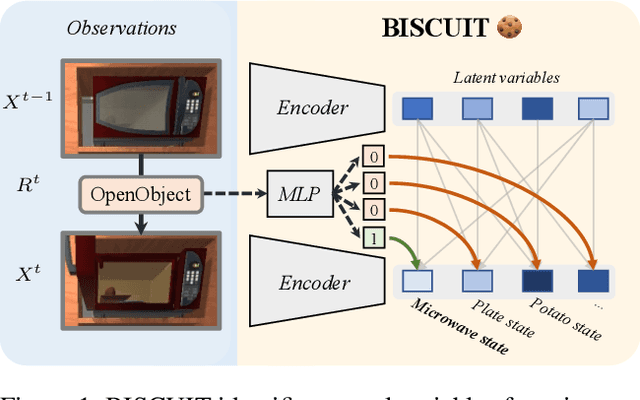



Identifying the causal variables of an environment and how to intervene on them is of core value in applications such as robotics and embodied AI. While an agent can commonly interact with the environment and may implicitly perturb the behavior of some of these causal variables, often the targets it affects remain unknown. In this paper, we show that causal variables can still be identified for many common setups, e.g., additive Gaussian noise models, if the agent's interactions with a causal variable can be described by an unknown binary variable. This happens when each causal variable has two different mechanisms, e.g., an observational and an interventional one. Using this identifiability result, we propose BISCUIT, a method for simultaneously learning causal variables and their corresponding binary interaction variables. On three robotic-inspired datasets, BISCUIT accurately identifies causal variables and can even be scaled to complex, realistic environments for embodied AI.
Rotating Features for Object Discovery
Jun 01, 2023
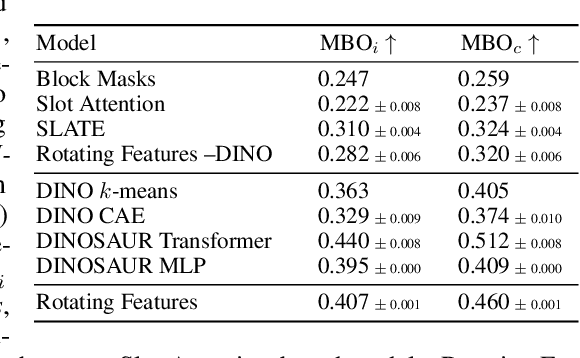

The binding problem in human cognition, concerning how the brain represents and connects objects within a fixed network of neural connections, remains a subject of intense debate. Most machine learning efforts addressing this issue in an unsupervised setting have focused on slot-based methods, which may be limiting due to their discrete nature and difficulty to express uncertainty. Recently, the Complex AutoEncoder was proposed as an alternative that learns continuous and distributed object-centric representations. However, it is only applicable to simple toy data. In this paper, we present Rotating Features, a generalization of complex-valued features to higher dimensions, and a new evaluation procedure for extracting objects from distributed representations. Additionally, we show the applicability of our approach to pre-trained features. Together, these advancements enable us to scale distributed object-centric representations from simple toy to real-world data. We believe this work advances a new paradigm for addressing the binding problem in machine learning and has the potential to inspire further innovation in the field.
Mesh Neural Networks for SE(3)-Equivariant Hemodynamics Estimation on the Artery Wall
Dec 09, 2022
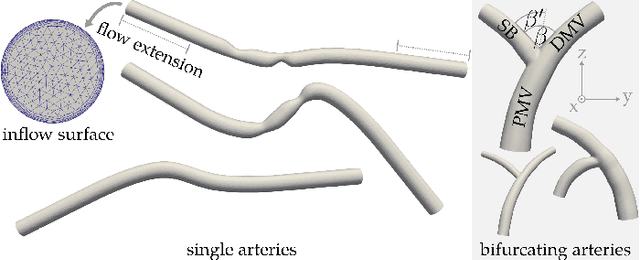
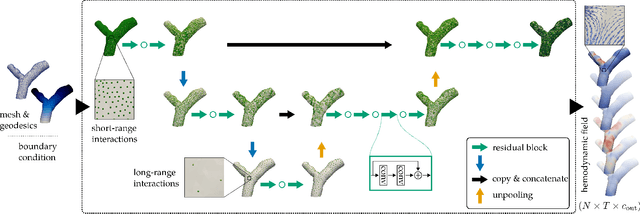
Computational fluid dynamics (CFD) is a valuable asset for patient-specific cardiovascular-disease diagnosis and prognosis, but its high computational demands hamper its adoption in practice. Machine-learning methods that estimate blood flow in individual patients could accelerate or replace CFD simulation to overcome these limitations. In this work, we consider the estimation of vector-valued quantities on the wall of three-dimensional geometric artery models. We employ group-equivariant graph convolution in an end-to-end SE(3)-equivariant neural network that operates directly on triangular surface meshes and makes efficient use of training data. We run experiments on a large dataset of synthetic coronary arteries and find that our method estimates directional wall shear stress (WSS) with an approximation error of 7.6% and normalised mean absolute error (NMAE) of 0.4% while up to two orders of magnitude faster than CFD. Furthermore, we show that our method is powerful enough to accurately predict transient, vector-valued WSS over the cardiac cycle while conditioned on a range of different inflow boundary conditions. These results demonstrate the potential of our proposed method as a plugin replacement for CFD in the personalised prediction of hemodynamic vector and scalar fields.