 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved motif-scaffolding with SE(3) flow matching
Jan 08, 2024Protein design often begins with knowledge of a desired function from a motif which motif-scaffolding aims to construct a functional protein around. Recently, generative models have achieved breakthrough success in designing scaffolds for a diverse range of motifs. However, the generated scaffolds tend to lack structural diversity, which can hinder success in wet-lab validation. In this work, we extend FrameFlow, an SE(3) flow matching model for protein backbone generation, to perform motif-scaffolding with two complementary approaches. The first is motif amortization, in which FrameFlow is trained with the motif as input using a data augmentation strategy. The second is motif guidance, which performs scaffolding using an estimate of the conditional score from FrameFlow, and requires no additional training. Both approaches achieve an equivalent or higher success rate than previous state-of-the-art methods, with 2.5 times more structurally diverse scaffolds. Code: https://github.com/ microsoft/frame-flow.
Latent Representation and Simulation of Markov Processes via Time-Lagged Information Bottleneck
Sep 13, 2023



Markov processes are widely used mathematical models for describing dynamic systems in various fields. However, accurately simulating large-scale systems at long time scales is computationally expensive due to the short time steps required for accurate integration. In this paper, we introduce an inference process that maps complex systems into a simplified representational space and models large jumps in time. To achieve this, we propose Time-lagged Information Bottleneck (T-IB), a principled objective rooted in information theory, which aims to capture relevant temporal features while discarding high-frequency information to simplify the simulation task and minimize the inference error. Our experiments demonstrate that T-IB learns information-optimal representations for accurately modeling the statistical properties and dynamics of the original process at a selected time lag, outperforming existing time-lagged dimensionality reduction methods.
PDE-Refiner: Achieving Accurate Long Rollouts with Neural PDE Solvers
Aug 10, 2023
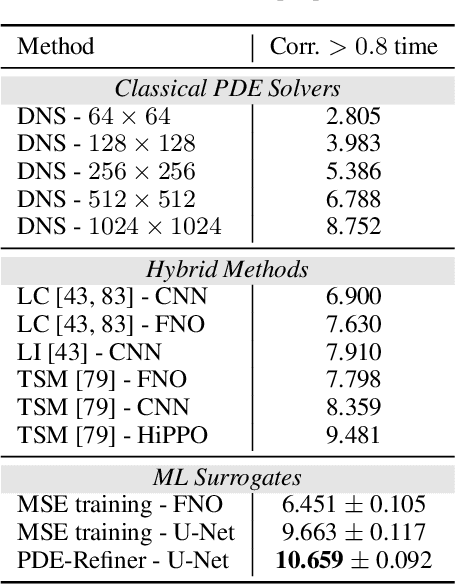


Time-dependent partial differential equations (PDEs) are ubiquitous in science and engineering. Recently, mostly due to the high computational cost of traditional solution techniques, deep neural network based surrogates have gained increased interest. The practical utility of such neural PDE solvers relies on their ability to provide accurate, stable predictions over long time horizons, which is a notoriously hard problem. In this work, we present a large-scale analysis of common temporal rollout strategies, identifying the neglect of non-dominant spatial frequency information, often associated with high frequencies in PDE solutions, as the primary pitfall limiting stable, accurate rollout performance. Based on these insights, we draw inspiration from recent advances in diffusion models to introduce PDE-Refiner; a novel model class that enables more accurate modeling of all frequency components via a multistep refinement process. We validate PDE-Refiner on challenging benchmarks of complex fluid dynamics, demonstrating stable and accurate rollouts that consistently outperform state-of-the-art models, including neural, numerical, and hybrid neural-numerical architectures. We further demonstrate that PDE-Refiner greatly enhances data efficiency, since the denoising objective implicitly induces a novel form of spectral data augmentation. Finally, PDE-Refiner's connection to diffusion models enables an accurate and efficient assessment of the model's predictive uncertainty, allowing us to estimate when the surrogate becomes inaccurate.
Dynamic Probabilistic Pruning: A general framework for hardware-constrained pruning at different granularities
May 26, 2021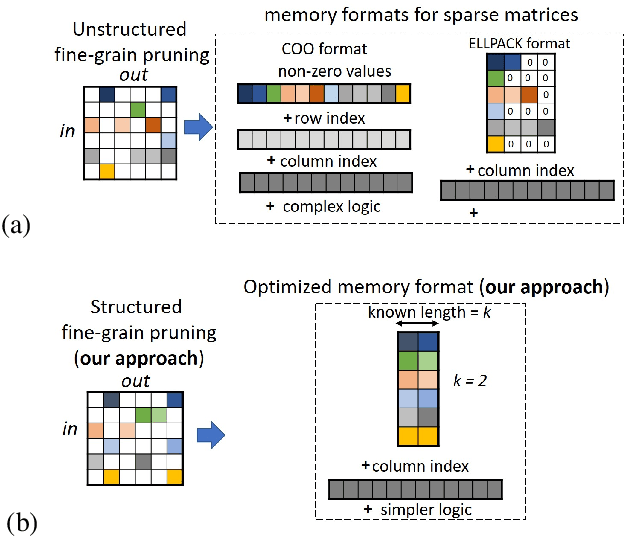
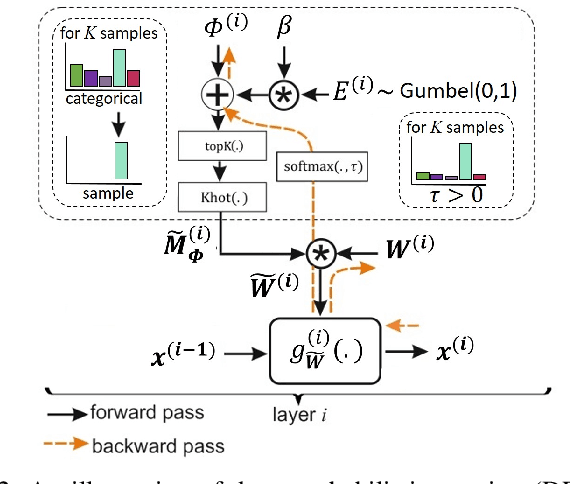
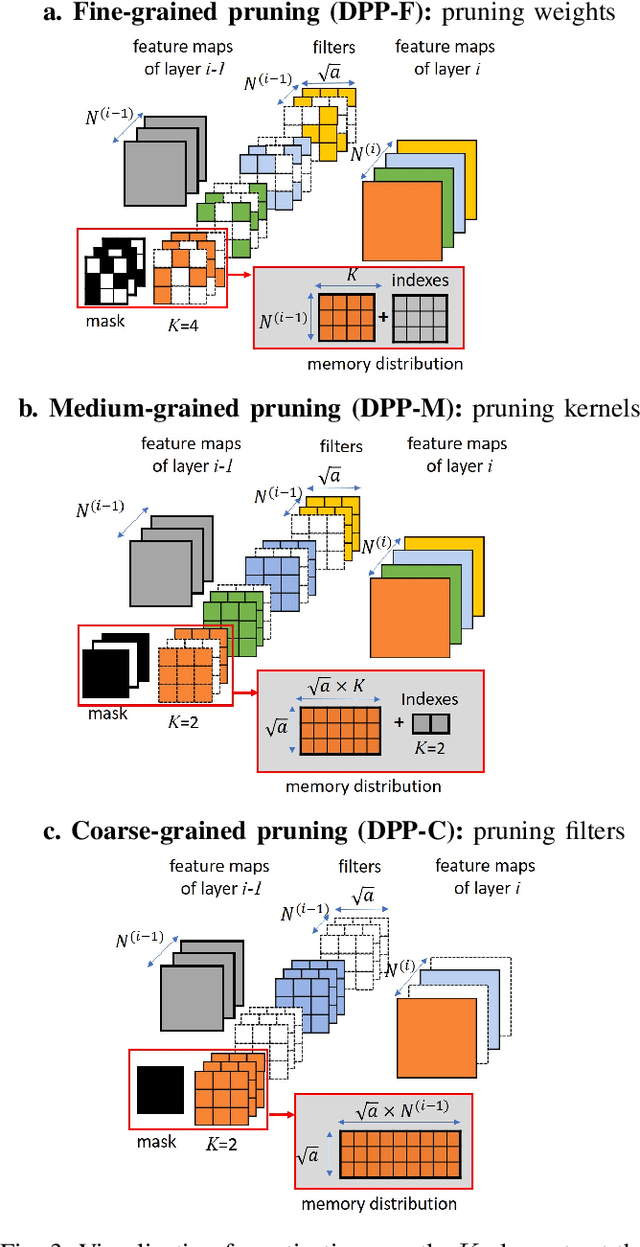
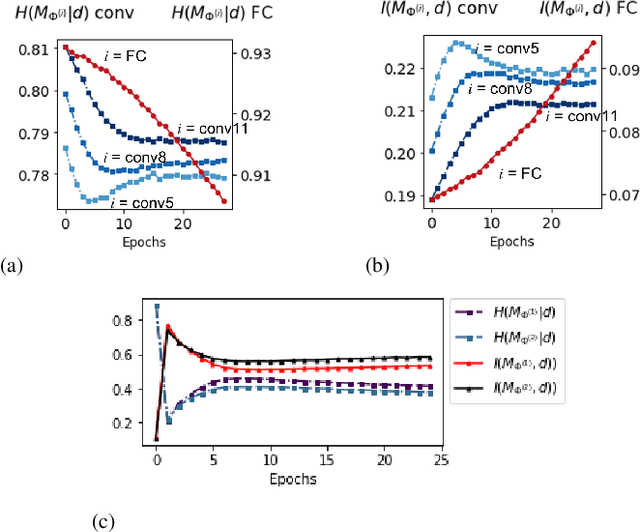
Unstructured neural network pruning algorithms have achieved impressive compression rates. However, the resulting - typically irregular - sparse matrices hamper efficient hardware implementations, leading to additional memory usage and complex control logic that diminishes the benefits of unstructured pruning. This has spurred structured coarse-grained pruning solutions that prune entire filters or even layers, enabling efficient implementation at the expense of reduced flexibility. Here we propose a flexible new pruning mechanism that facilitates pruning at different granularities (weights, kernels, filters/feature maps), while retaining efficient memory organization (e.g. pruning exactly k-out-of-n weights for every output neuron, or pruning exactly k-out-of-n kernels for every feature map). We refer to this algorithm as Dynamic Probabilistic Pruning (DPP). DPP leverages the Gumbel-softmax relaxation for differentiable k-out-of-n sampling, facilitating end-to-end optimization. We show that DPP achieves competitive compression rates and classification accuracy when pruning common deep learning models trained on different benchmark datasets for image classification. Relevantly, the non-magnitude-based nature of DPP allows for joint optimization of pruning and weight quantization in order to even further compress the network, which we show as well. Finally, we propose novel information theoretic metrics that show the confidence and pruning diversity of pruning masks within a layer.
Learning Sampling and Model-Based Signal Recovery for Compressed Sensing MRI
Apr 22, 2020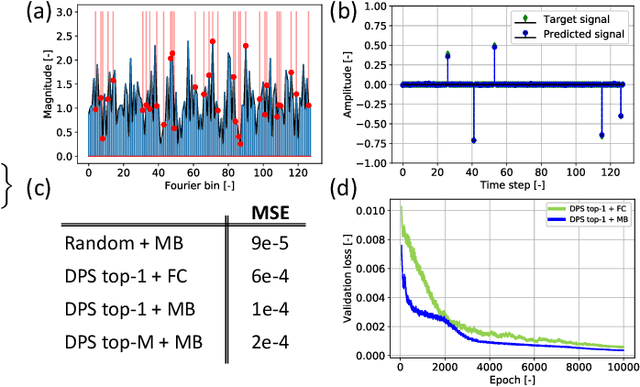

Compressed sensing (CS) MRI relies on adequate undersampling of the k-space to accelerate the acquisition without compromising image quality. Consequently, the design of optimal sampling patterns for these k-space coefficients has received significant attention, with many CS MRI methods exploiting variable-density probability distributions. Realizing that an optimal sampling pattern may depend on the downstream task (e.g. image reconstruction, segmentation, or classification), we here propose joint learning of both task-adaptive k-space sampling and a subsequent model-based proximal-gradient recovery network. The former is enabled through a probabilistic generative model that leverages the Gumbel-softmax relaxation to sample across trainable beliefs while maintaining differentiability. The proposed combination of a highly flexible sampling model and a model-based (sampling-adaptive) image reconstruction network facilitates exploration and efficient training, yielding improved MR image quality compared to other sampling baselines.
The k-tied Normal Distribution: A Compact Parameterization of Gaussian Mean Field Posteriors in Bayesian Neural Networks
Feb 07, 2020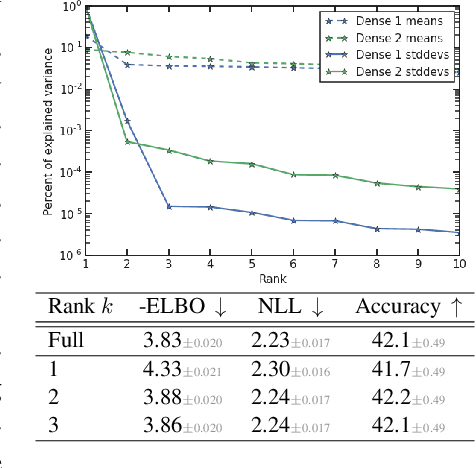
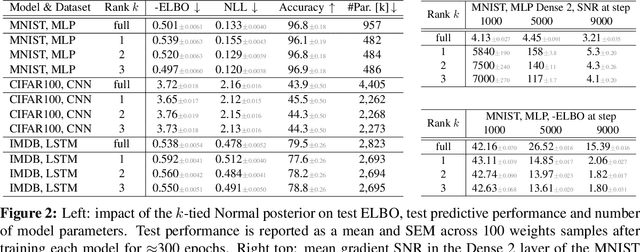
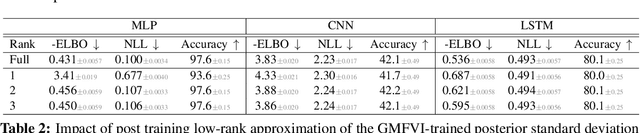
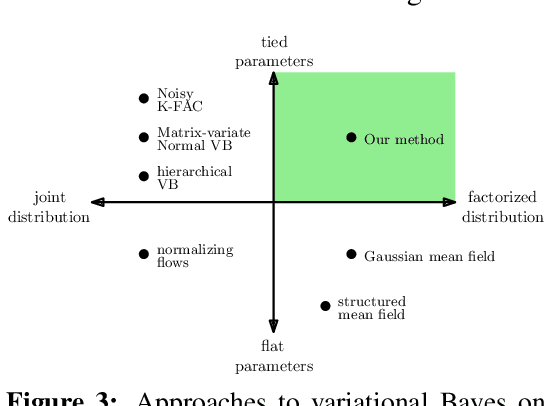
Variational Bayesian Inference is a popular methodology for approximating posterior distributions over Bayesian neural network weights. Recent work developing this class of methods has explored ever richer parameterizations of the approximate posterior in the hope of improving performance. In contrast, here we share a curious experimental finding that suggests instead restricting the variational distribution to a more compact parameterization. For a variety of deep Bayesian neural networks trained using Gaussian mean-field variational inference, we find that the posterior standard deviations consistently exhibit strong low-rank structure after convergence. This means that by decomposing these variational parameters into a low-rank factorization, we can make our variational approximation more compact without decreasing the models' performance. Furthermore, we find that such factorized parameterizations improve the signal-to-noise ratio of stochastic gradient estimates of the variational lower bound, resulting in faster convergence.
How Good is the Bayes Posterior in Deep Neural Networks Really?
Feb 06, 2020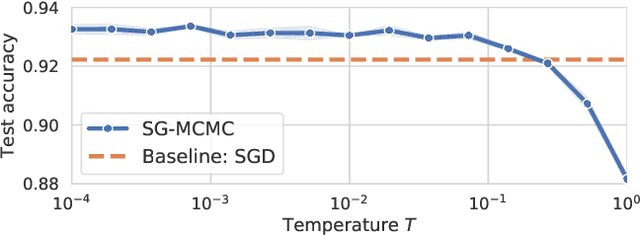
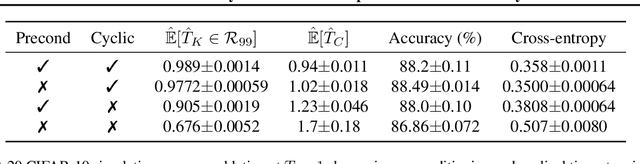
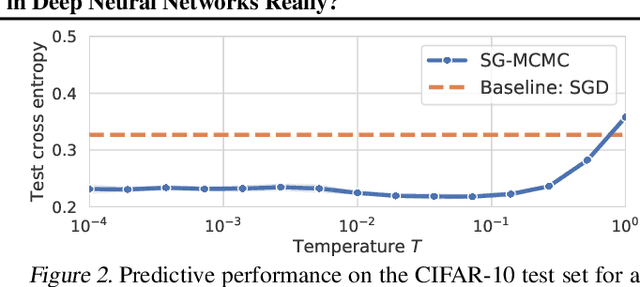

During the past five years the Bayesian deep learning community has developed increasingly accurate and efficient approximate inference procedures that allow for Bayesian inference in deep neural networks. However, despite this algorithmic progress and the promise of improved uncertainty quantification and sample efficiency there are---as of early 2020---no publicized deployments of Bayesian neural networks in industrial practice. In this work we cast doubt on the current understanding of Bayes posteriors in popular deep neural networks: we demonstrate through careful MCMC sampling that the posterior predictive induced by the Bayes posterior yields systematically worse predictions compared to simpler methods including point estimates obtained from SGD. Furthermore, we demonstrate that predictive performance is improved significantly through the use of a "cold posterior" that overcounts evidence. Such cold posteriors sharply deviate from the Bayesian paradigm but are commonly used as heuristic in Bayesian deep learning papers. We put forward several hypotheses that could explain cold posteriors and evaluate the hypotheses through experiments. Our work questions the goal of accurate posterior approximations in Bayesian deep learning: If the true Bayes posterior is poor, what is the use of more accurate approximations? Instead, we argue that it is timely to focus on understanding the origin of the improved performance of cold posteriors.
Hydra: Preserving Ensemble Diversity for Model Distillation
Jan 14, 2020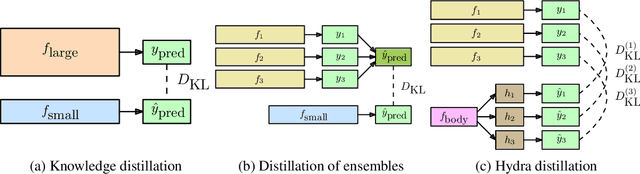
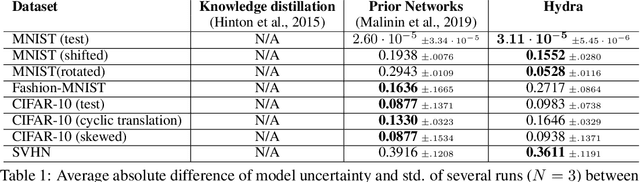
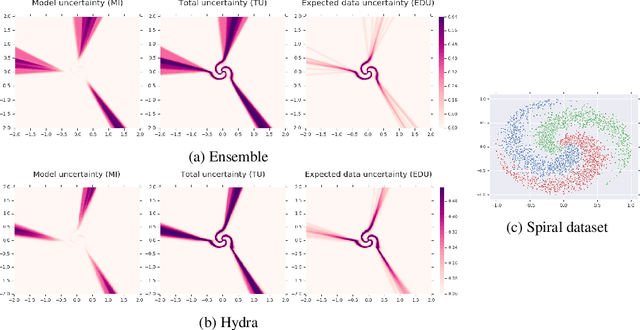
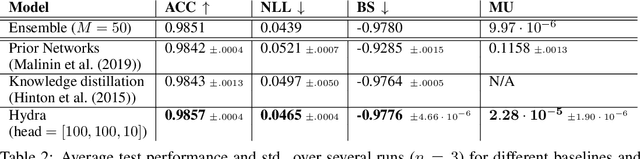
Ensembles of models have been empirically shown to improve predictive performance and to yield robust measures of uncertainty. However, they are expensive in computation and memory. Therefore, recent research has focused on distilling ensembles into a single compact model, reducing the computational and memory burden of the ensemble while trying to preserve its predictive behavior. Most existing distillation formulations summarize the ensemble by capturing its average predictions. As a result, the diversity of the ensemble predictions, stemming from each individual member, is lost. Thus, the distilled model cannot provide a measure of uncertainty comparable to that of the original ensemble. To retain more faithfully the diversity of the ensemble, we propose a distillation method based on a single multi-headed neural network, which we refer to as Hydra. The shared body network learns a joint feature representation that enables each head to capture the predictive behavior of each ensemble member. We demonstrate that with a slight increase in parameter count, Hydra improves distillation performance on classification and regression settings while capturing the uncertainty behaviour of the original ensemble over both in-domain and out-of-distribution tasks.
Learning Sub-Sampling and Signal Recovery with Applications in Ultrasound Imaging
Aug 15, 2019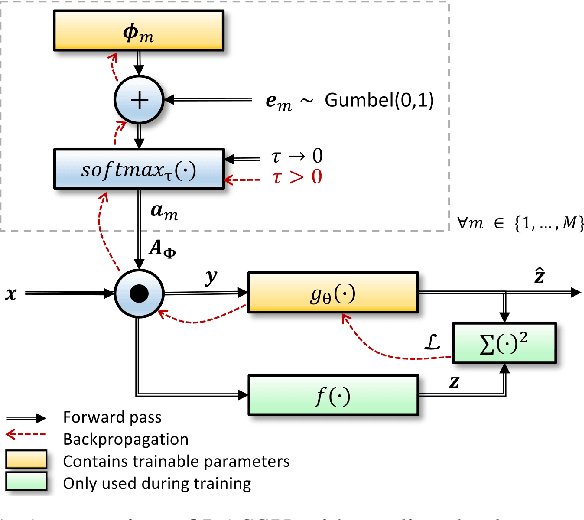
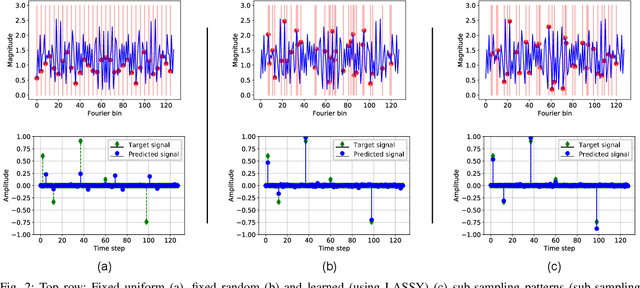
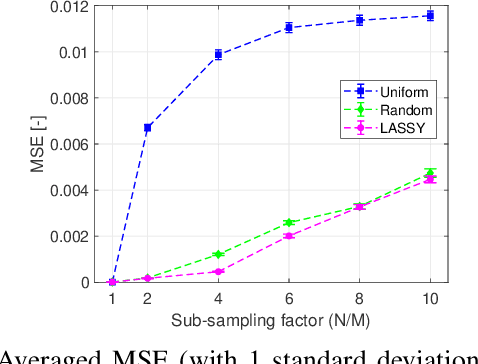
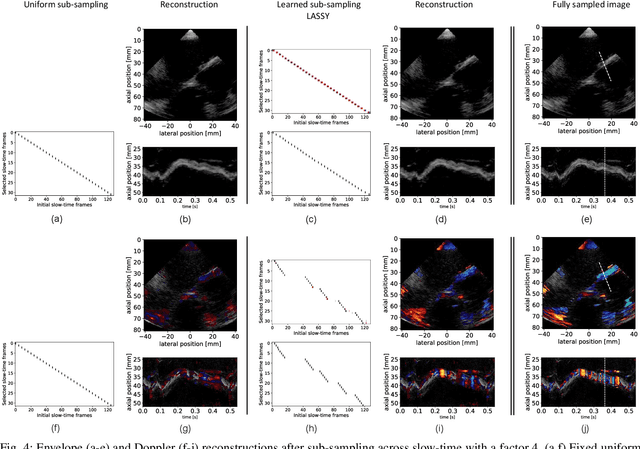
Limitations on bandwidth and power consumption impose strict bounds on data rates of diagnostic imaging systems. Consequently, the design of suitable (i.e. task- and data-aware) compression and reconstruction techniques has attracted considerable attention in recent years. Compressed sensing emerged as a popular framework for sparse signal reconstruction from a small set of compressed measurements. However, typical compressed sensing designs measure a (non)linearly weighted combination of all input signal elements, which poses practical challenges. These designs are also not necessarily task-optimal. In addition, real-time recovery is hampered by the iterative and time-consuming nature of sparse recovery algorithms. Recently, deep learning methods have shown promise for fast recovery from compressed measurements, but the design of adequate and practical sensing strategies remains a challenge. Here, we propose a deep learning solution, termed LASSY (LeArning Sub-Sampling and recoverY), that jointly learns a task-driven sub-sampling pattern and subsequent reconstruction model. The learned sub-sampling patterns are straightforwardly implementable, and based on the task at hand. LASSY's effectiveness is demonstrated in-silico for sparse signal recovery from partial Fourier measurements, and in-vivo for both anatomical-image and motion (Doppler) reconstruction from sub-sampled medical ultrasound imaging data.
Greedy InfoMax for Biologically Plausible Self-Supervised Representation Learning
May 28, 2019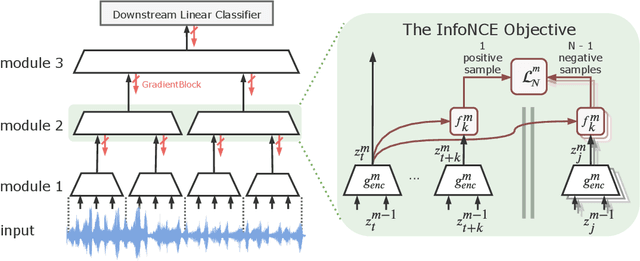
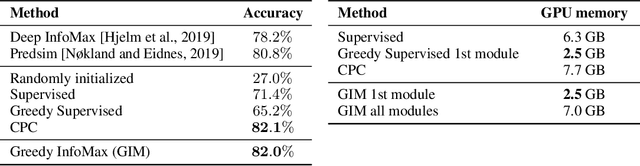

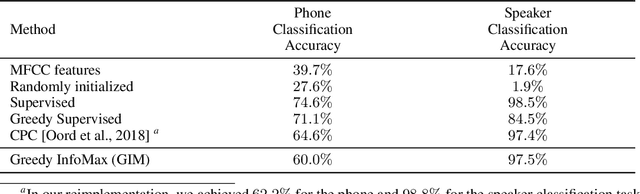
We propose a novel deep learning method for local self-supervised representation learning that does not require labels nor end-to-end backpropagation but exploits the natural order in data instead. Inspired by the observation that biological neural networks appear to learn without backpropagating a global error signal, we split a deep neural network into a stack of gradient-isolated modules. Each module is trained to maximize the mutual information between its consecutive outputs using the InfoNCE bound from Oord et al. [2018]. Despite this greedy training, we demonstrate that each module improves upon the output of its predecessor, and that the representations created by the top module yield highly competitive results on downstream classification tasks in the audio and visual domain. The proposal enables optimizing modules asynchronously, allowing large-scale distributed training of very deep neural networks on unlabelled datasets.