 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Control With Ensemble Deep Deterministic Policy Gradients
Nov 30, 2021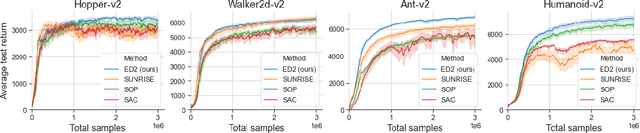
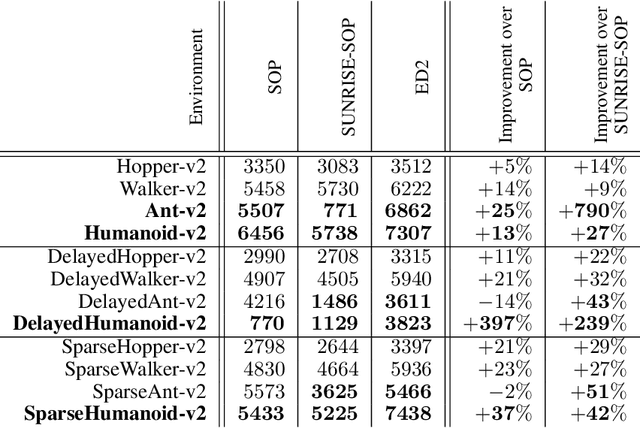
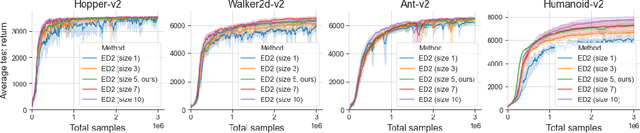

The growth of deep reinforcement learning (RL) has brought multiple exciting tools and methods to the field. This rapid expansion makes it important to understand the interplay between individual elements of the RL toolbox. We approach this task from an empirical perspective by conducting a study in the continuous control setting. We present multiple insights of fundamental nature, including: an average of multiple actors trained from the same data boosts performance; the existing methods are unstable across training runs, epochs of training, and evaluation runs; a commonly used additive action noise is not required for effective training; a strategy based on posterior sampling explores better than the approximated UCB combined with the weighted Bellman backup; the weighted Bellman backup alone cannot replace the clipped double Q-Learning; the critics' initialization plays the major role in ensemble-based actor-critic exploration. As a conclusion, we show how existing tools can be brought together in a novel way, giving rise to the Ensemble Deep Deterministic Policy Gradients (ED2) method, to yield state-of-the-art results on continuous control tasks from OpenAI Gym MuJoCo. From the practical side, ED2 is conceptually straightforward, easy to code, and does not require knowledge outside of the existing RL toolbox.
How Good is the Bayes Posterior in Deep Neural Networks Really?
Feb 06, 2020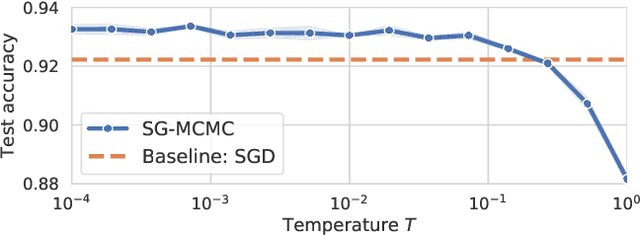
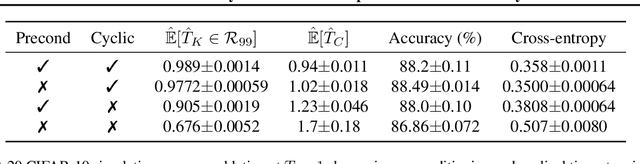
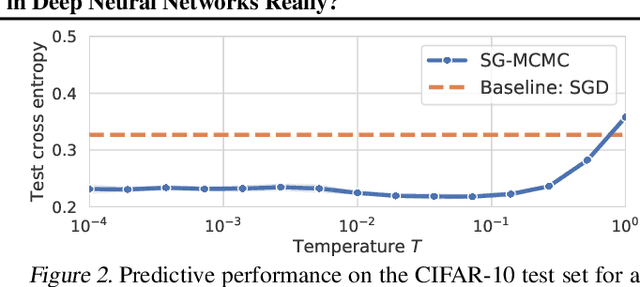

During the past five years the Bayesian deep learning community has developed increasingly accurate and efficient approximate inference procedures that allow for Bayesian inference in deep neural networks. However, despite this algorithmic progress and the promise of improved uncertainty quantification and sample efficiency there are---as of early 2020---no publicized deployments of Bayesian neural networks in industrial practice. In this work we cast doubt on the current understanding of Bayes posteriors in popular deep neural networks: we demonstrate through careful MCMC sampling that the posterior predictive induced by the Bayes posterior yields systematically worse predictions compared to simpler methods including point estimates obtained from SGD. Furthermore, we demonstrate that predictive performance is improved significantly through the use of a "cold posterior" that overcounts evidence. Such cold posteriors sharply deviate from the Bayesian paradigm but are commonly used as heuristic in Bayesian deep learning papers. We put forward several hypotheses that could explain cold posteriors and evaluate the hypotheses through experiments. Our work questions the goal of accurate posterior approximations in Bayesian deep learning: If the true Bayes posterior is poor, what is the use of more accurate approximations? Instead, we argue that it is timely to focus on understanding the origin of the improved performance of cold posteriors.
Improved GQ-CNN: Deep Learning Model for Planning Robust Grasps
Feb 16, 2018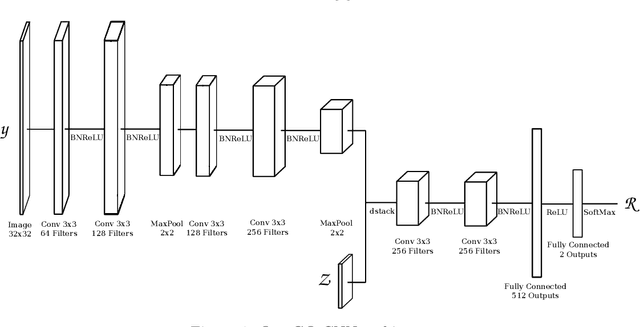


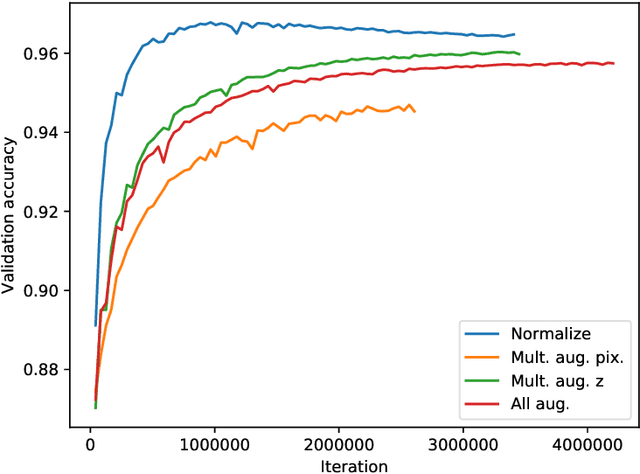
Recent developments in the field of robot grasping have shown great improvements in the grasp success rates when dealing with unknown objects. In this work we improve on one of the most promising approaches, the Grasp Quality Convolutional Neural Network (GQ-CNN) trained on the DexNet 2.0 dataset. We propose a new architecture for the GQ-CNN and describe practical improvements that increase the model validation accuracy from 92.2% to 95.8% and from 85.9% to 88.0% on respectively image-wise and object-wise training and validation splits.