 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKine2Go: Kinematic dataset for the Unitree Go2 robot with diverse gaits and motions
Jun 12, 2026The recent popularity of robotics, combined with the steadily decreasing cost of robotic hardware, has lowered the entry barrier to robotics research and enabled rapid advancements in the field. One of the primary examples is the Unitree Go2 quadruped robot, which is often used by researchers in the areas of locomotion, navigation, control, and others. Many researchers use the Go2 robot in combination with techniques like imitation learning, reinforcement learning, and behavioral cloning to allow machine learning systems to take full control of the robot. At the same time, many of those techniques require demonstration data consisting of the robot's kinematics information and actions applied to the motors. Obtaining such data is difficult, requires building complex pipelines, and can take significant time. To aid in those kinds of efforts, we present Kine2Go - a dataset with 800 diverse gait kinematics trajectory motion data for the Unitree Go2 robot, derived from 40 distinct policies. Our pipeline accepts data from various quadruped morphologies and translates them to a Go2-compatible format. Then we use Reinforcement Learning to train policies following a given motion, and finally we gather data from those policies, which grants robust, perturbed kinematic data with corresponding motor-level actions.
Swim2Real: VLM-Guided System Identification for Sim-to-Real Transfer
Mar 21, 2026We present Swim2Real, a pipeline that calibrates a 16-parameter robotic fish simulator from swimming videos using vision-language model (VLM) feedback, requiring no hand-designed search stages. Calibrating soft aquatic robots is particularly challenging because nonlinear fluid-structure coupling makes the parameter landscape chaotic, simplified fluid models introduce a persistent sim-to-real gap, and controlled aquatic experiments are difficult to reproduce. Prior work on this platform required three manually tailored stages to handle this complexity. The VLM compares simulated and real videos and proposes parameter updates. A backtracking line search then validates each step size, tripling the accept rate from 14% to 42% by recovering proposals where the direction is correct but the magnitude is too large. Swim2Real calibrates all 16 parameters simultaneously, most closely matching real fish velocities across all motor frequencies (MAE = 7.4 mm/s, 43% lower than the next-best method), with zero outlier seeds across five runs. Motor commands from the trained policy transfer to the physical fish at 50 Hz, completing the pipeline from swimming video to real-world deployment. Downstream RL policies swim 12% farther than those from BayesOpt-calibrated simulators and 90% farther than CMA-ES. These results demonstrate that VLM-guided calibration can close the sim-to-real gap for aquatic robots directly from video, enabling zero-shot RL transfer to physical swimmers without manual system identification, a step toward automated, general-purpose simulator tuning for underwater robotics.
Reward-Conditioned Reinforcement Learning
Mar 05, 2026RL agents are typically trained under a single, fixed reward function, which makes them brittle to reward misspecification and limits their ability to adapt to changing task preferences. We introduce Reward-Conditioned Reinforcement Learning (RCRL), a framework that trains a single agent to optimize a family of reward specifications while collecting experience under only one nominal objective. RCRL conditions the agent on reward parameterizations and learns multiple reward objectives from a shared replay data entirely off-policy, enabling a single policy to represent reward-specific behaviors. Across single-task, multi-task, and vision-based benchmarks, we show that RCRL not only improves performance under the nominal reward parameterization, but also enables efficient adaptation to new parameterizations. Our results demonstrate that RCRL provides a scalable mechanism for learning robust, steerable policies without sacrificing the simplicity of single-task training.
Vid2Sid: Videos Can Help Close the Sim2Real Gap
Feb 22, 2026Calibrating a robot simulator's physics parameters (friction, damping, material stiffness) to match real hardware is often done by hand or with black-box optimizers that reduce error but cannot explain which physical discrepancies drive the error. When sensing is limited to external cameras, the problem is further compounded by perception noise and the absence of direct force or state measurements. We present Vid2Sid, a video-driven system identification pipeline that couples foundation-model perception with a VLM-in-the-loop optimizer that analyzes paired sim-real videos, diagnoses concrete mismatches, and proposes physics parameter updates with natural language rationales. We evaluate our approach on a tendon-actuated finger (rigid-body dynamics in MuJoCo) and a deformable continuum tentacle (soft-body dynamics in PyElastica). On sim2real holdout controls unseen during training, Vid2Sid achieves the best average rank across all settings, matching or exceeding black-box optimizers while uniquely providing interpretable reasoning at each iteration. Sim2sim validation confirms that Vid2Sid recovers ground-truth parameters most accurately (mean relative error under 13\% vs. 28--98\%), and ablation analysis reveals three calibration regimes. VLM-guided optimization excels when perception is clean and the simulator is expressive, while model-class limitations bound performance in more challenging settings.
Debate2Create: Robot Co-design via Large Language Model Debates
Oct 29, 2025Automating the co-design of a robot's morphology and control is a long-standing challenge due to the vast design space and the tight coupling between body and behavior. We introduce Debate2Create (D2C), a framework in which large language model (LLM) agents engage in a structured dialectical debate to jointly optimize a robot's design and its reward function. In each round, a design agent proposes targeted morphological modifications, and a control agent devises a reward function tailored to exploit the new design. A panel of pluralistic judges then evaluates the design-control pair in simulation and provides feedback that guides the next round of debate. Through iterative debates, the agents progressively refine their proposals, producing increasingly effective robot designs. Notably, D2C yields diverse and specialized morphologies despite no explicit diversity objective. On a quadruped locomotion benchmark, D2C discovers designs that travel 73% farther than the default, demonstrating that structured LLM-based debate can serve as a powerful mechanism for emergent robot co-design. Our results suggest that multi-agent debate, when coupled with physics-grounded feedback, is a promising new paradigm for automated robot design.
Bigger, Regularized, Categorical: High-Capacity Value Functions are Efficient Multi-Task Learners
May 29, 2025Recent advances in language modeling and vision stem from training large models on diverse, multi-task data. This paradigm has had limited impact in value-based reinforcement learning (RL), where improvements are often driven by small models trained in a single-task context. This is because in multi-task RL sparse rewards and gradient conflicts make optimization of temporal difference brittle. Practical workflows for generalist policies therefore avoid online training, instead cloning expert trajectories or distilling collections of single-task policies into one agent. In this work, we show that the use of high-capacity value models trained via cross-entropy and conditioned on learnable task embeddings addresses the problem of task interference in online RL, allowing for robust and scalable multi-task training. We test our approach on 7 multi-task benchmarks with over 280 unique tasks, spanning high degree-of-freedom humanoid control and discrete vision-based RL. We find that, despite its simplicity, the proposed approach leads to state-of-the-art single and multi-task performance, as well as sample-efficient transfer to new tasks.
Joint MoE Scaling Laws: Mixture of Experts Can Be Memory Efficient
Feb 07, 2025



Mixture of Experts (MoE) architectures have significantly increased computational efficiency in both research and real-world applications of large-scale machine learning models. However, their scalability and efficiency under memory constraints remain relatively underexplored. In this work, we present joint scaling laws for dense and MoE models, incorporating key factors such as the number of active parameters, dataset size, and the number of experts. Our findings provide a principled framework for selecting the optimal MoE configuration under fixed memory and compute budgets. Surprisingly, we show that MoE models can be more memory-efficient than dense models, contradicting conventional wisdom. To derive and validate the theoretical predictions of our scaling laws, we conduct over 280 experiments with up to 2.7B active parameters and up to 5B total parameters. These results offer actionable insights for designing and deploying MoE models in practical large-scale training scenarios.
RoboMorph: Evolving Robot Morphology using Large Language Models
Jul 11, 2024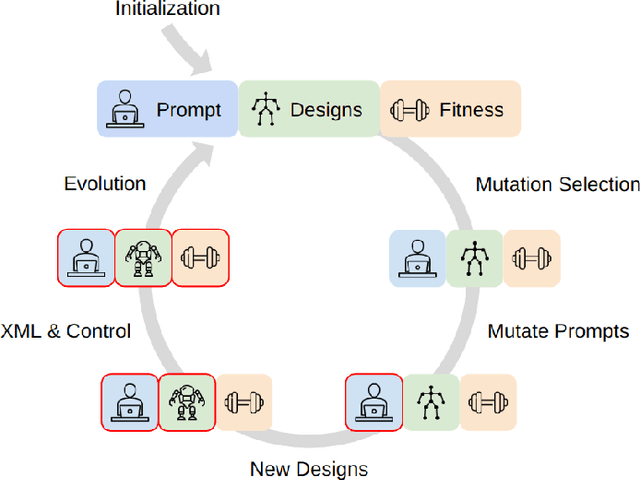
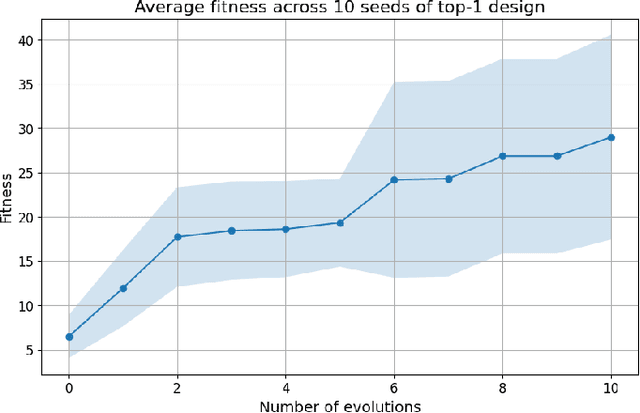
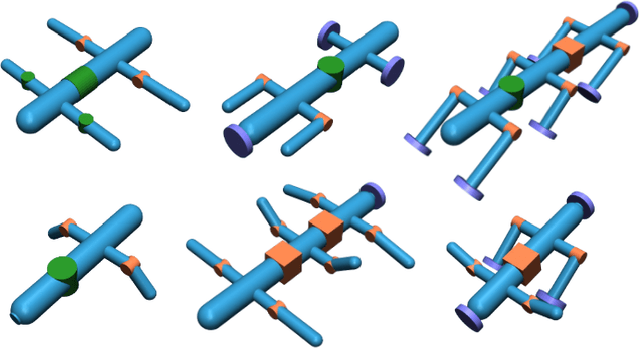
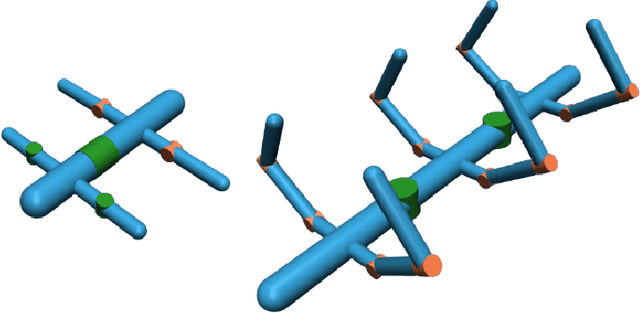
We introduce RoboMorph, an automated approach for generating and optimizing modular robot designs using large language models (LLMs) and evolutionary algorithms. In this framework, we represent each robot design as a grammar and leverage the capabilities of LLMs to navigate the extensive robot design space, which is traditionally time-consuming and computationally demanding. By integrating automatic prompt design and a reinforcement learning based control algorithm, RoboMorph iteratively improves robot designs through feedback loops. Our experimental results demonstrate that RoboMorph can successfully generate nontrivial robots that are optimized for a single terrain while showcasing improvements in morphology over successive evolutions. Our approach demonstrates the potential of using LLMs for data-driven and modular robot design, providing a promising methodology that can be extended to other domains with similar design frameworks.
Bigger, Regularized, Optimistic: scaling for compute and sample-efficient continuous control
May 25, 2024



Sample efficiency in Reinforcement Learning (RL) has traditionally been driven by algorithmic enhancements. In this work, we demonstrate that scaling can also lead to substantial improvements. We conduct a thorough investigation into the interplay of scaling model capacity and domain-specific RL enhancements. These empirical findings inform the design choices underlying our proposed BRO (Bigger, Regularized, Optimistic) algorithm. The key innovation behind BRO is that strong regularization allows for effective scaling of the critic networks, which, paired with optimistic exploration, leads to superior performance. BRO achieves state-of-the-art results, significantly outperforming the leading model-based and model-free algorithms across 40 complex tasks from the DeepMind Control, MetaWorld, and MyoSuite benchmarks. BRO is the first model-free algorithm to achieve near-optimal policies in the notoriously challenging Dog and Humanoid tasks.
A Case for Validation Buffer in Pessimistic Actor-Critic
Mar 01, 2024



In this paper, we investigate the issue of error accumulation in critic networks updated via pessimistic temporal difference objectives. We show that the critic approximation error can be approximated via a recursive fixed-point model similar to that of the Bellman value. We use such recursive definition to retrieve the conditions under which the pessimistic critic is unbiased. Building on these insights, we propose Validation Pessimism Learning (VPL) algorithm. VPL uses a small validation buffer to adjust the levels of pessimism throughout the agent training, with the pessimism set such that the approximation error of the critic targets is minimized. We investigate the proposed approach on a variety of locomotion and manipulation tasks and report improvements in sample efficiency and performance.