 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Iterative Computation in Reinforcement Learning
Feb 17, 2026How does the amount of compute available to a reinforcement learning (RL) policy affect its learning? Can policies using a fixed amount of parameters, still benefit from additional compute? The standard RL framework does not provide a language to answer these questions formally. Empirically, deep RL policies are often parameterized as neural networks with static architectures, conflating the amount of compute and the number of parameters. In this paper, we formalize compute bounded policies and prove that policies which use more compute can solve problems and generalize to longer-horizon tasks that are outside the scope of policies with less compute. Building on prior work in algorithmic learning and model-free planning, we propose a minimal architecture that can use a variable amount of compute. Our experiments complement our theory. On a set 31 different tasks spanning online and offline RL, we show that $(1)$ this architecture achieves stronger performance simply by using more compute, and $(2)$ stronger generalization on longer-horizon test tasks compared to standard feedforward networks or deep residual network using up to 5 times more parameters.
On Computation and Reinforcement Learning
Feb 05, 2026How does the amount of compute available to a reinforcement learning (RL) policy affect its learning? Can policies using a fixed amount of parameters, still benefit from additional compute? The standard RL framework does not provide a language to answer these questions formally. Empirically, deep RL policies are often parameterized as neural networks with static architectures, conflating the amount of compute and the number of parameters. In this paper, we formalize compute bounded policies and prove that policies which use more compute can solve problems and generalize to longer-horizon tasks that are outside the scope of policies with less compute. Building on prior work in algorithmic learning and model-free planning, we propose a minimal architecture that can use a variable amount of compute. Our experiments complement our theory. On a set 31 different tasks spanning online and offline RL, we show that $(1)$ this architecture achieves stronger performance simply by using more compute, and $(2)$ stronger generalization on longer-horizon test tasks compared to standard feedforward networks or deep residual network using up to 5 times more parameters.
1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
Mar 19, 2025Scaling up self-supervised learning has driven breakthroughs in language and vision, yet comparable progress has remained elusive in reinforcement learning (RL). In this paper, we study building blocks for self-supervised RL that unlock substantial improvements in scalability, with network depth serving as a critical factor. Whereas most RL papers in recent years have relied on shallow architectures (around 2 - 5 layers), we demonstrate that increasing the depth up to 1024 layers can significantly boost performance. Our experiments are conducted in an unsupervised goal-conditioned setting, where no demonstrations or rewards are provided, so an agent must explore (from scratch) and learn how to maximize the likelihood of reaching commanded goals. Evaluated on simulated locomotion and manipulation tasks, our approach increases performance by $2\times$ - $50\times$. Increasing the model depth not only increases success rates but also qualitatively changes the behaviors learned.
Accelerating Goal-Conditioned RL Algorithms and Research
Aug 20, 2024Self-supervision has the potential to transform reinforcement learning (RL), paralleling the breakthroughs it has enabled in other areas of machine learning. While self-supervised learning in other domains aims to find patterns in a fixed dataset, self-supervised goal-conditioned reinforcement learning (GCRL) agents discover new behaviors by learning from the goals achieved during unstructured interaction with the environment. However, these methods have failed to see similar success, both due to a lack of data from slow environments as well as a lack of stable algorithms. We take a step toward addressing both of these issues by releasing a high-performance codebase and benchmark JaxGCRL for self-supervised GCRL, enabling researchers to train agents for millions of environment steps in minutes on a single GPU. The key to this performance is a combination of GPU-accelerated environments and a stable, batched version of the contrastive reinforcement learning algorithm, based on an infoNCE objective, that effectively makes use of this increased data throughput. With this approach, we provide a foundation for future research in self-supervised GCRL, enabling researchers to quickly iterate on new ideas and evaluate them in a diverse set of challenging environments. Website + Code: https://github.com/MichalBortkiewicz/JaxGCRL
Overestimation, Overfitting, and Plasticity in Actor-Critic: the Bitter Lesson of Reinforcement Learning
Mar 01, 2024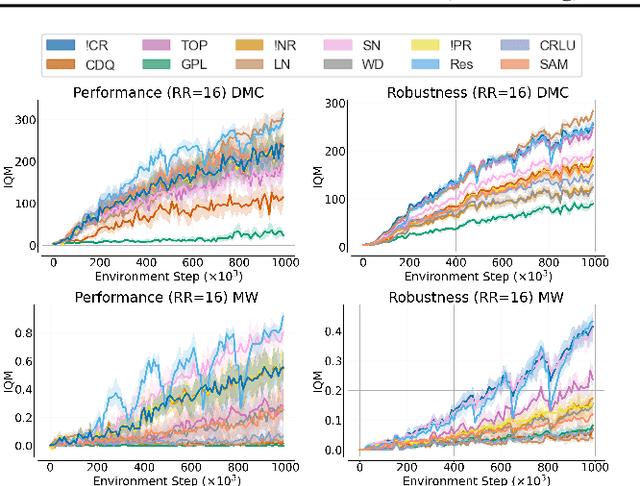

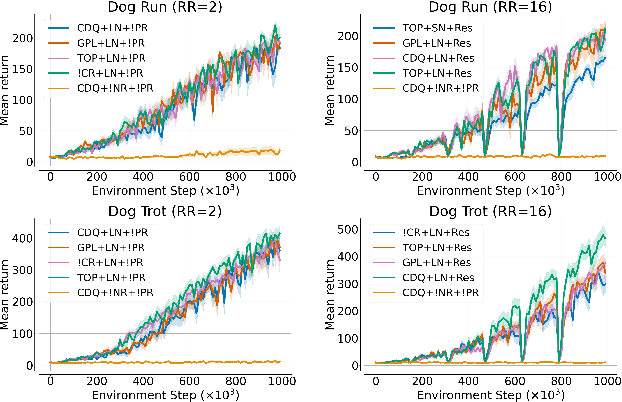
Recent advancements in off-policy Reinforcement Learning (RL) have significantly improved sample efficiency, primarily due to the incorporation of various forms of regularization that enable more gradient update steps than traditional agents. However, many of these techniques have been tested in limited settings, often on tasks from single simulation benchmarks and against well-known algorithms rather than a range of regularization approaches. This limits our understanding of the specific mechanisms driving RL improvements. To address this, we implemented over 60 different off-policy agents, each integrating established regularization techniques from recent state-of-the-art algorithms. We tested these agents across 14 diverse tasks from 2 simulation benchmarks. Our findings reveal that while the effectiveness of a specific regularization setup varies with the task, certain combinations consistently demonstrate robust and superior performance. Notably, a simple Soft Actor-Critic agent, appropriately regularized, reliably solves dog tasks, which were previously solved mainly through model-based approaches.
Fine-tuning Reinforcement Learning Models is Secretly a Forgetting Mitigation Problem
Feb 05, 2024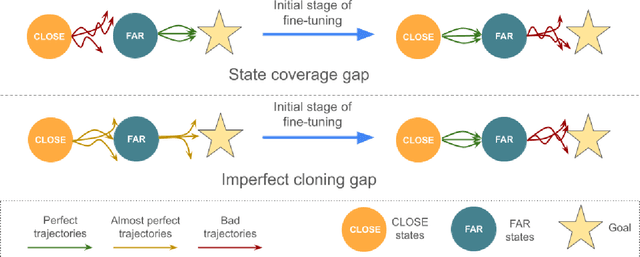
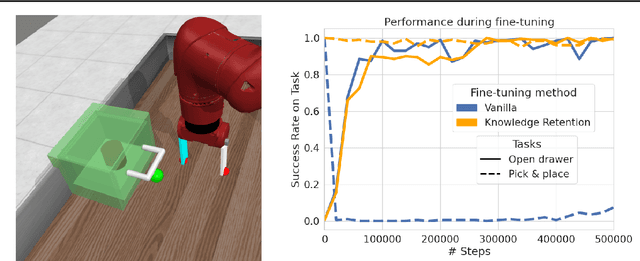
Fine-tuning is a widespread technique that allows practitioners to transfer pre-trained capabilities, as recently showcased by the successful applications of foundation models. However, fine-tuning reinforcement learning (RL) models remains a challenge. This work conceptualizes one specific cause of poor transfer, accentuated in the RL setting by the interplay between actions and observations: forgetting of pre-trained capabilities. Namely, a model deteriorates on the state subspace of the downstream task not visited in the initial phase of fine-tuning, on which the model behaved well due to pre-training. This way, we lose the anticipated transfer benefits. We identify conditions when this problem occurs, showing that it is common and, in many cases, catastrophic. Through a detailed empirical analysis of the challenging NetHack and Montezuma's Revenge environments, we show that standard knowledge retention techniques mitigate the problem and thus allow us to take full advantage of the pre-trained capabilities. In particular, in NetHack, we achieve a new state-of-the-art for neural models, improving the previous best score from $5$K to over $10$K points in the Human Monk scenario.
Emergency action termination for immediate reaction in hierarchical reinforcement learning
Nov 11, 2022



Hierarchical decomposition of control is unavoidable in large dynamical systems. In reinforcement learning (RL), it is usually solved with subgoals defined at higher policy levels and achieved at lower policy levels. Reaching these goals can take a substantial amount of time, during which it is not verified whether they are still worth pursuing. However, due to the randomness of the environment, these goals may become obsolete. In this paper, we address this gap in the state-of-the-art approaches and propose a method in which the validity of higher-level actions (thus lower-level goals) is constantly verified at the higher level. If the actions, i.e. lower level goals, become inadequate, they are replaced by more appropriate ones. This way we combine the advantages of hierarchical RL, which is fast training, and flat RL, which is immediate reactivity. We study our approach experimentally on seven benchmark environments.
Progressive Latent Replay for efficient Generative Rehearsal
Jul 05, 2022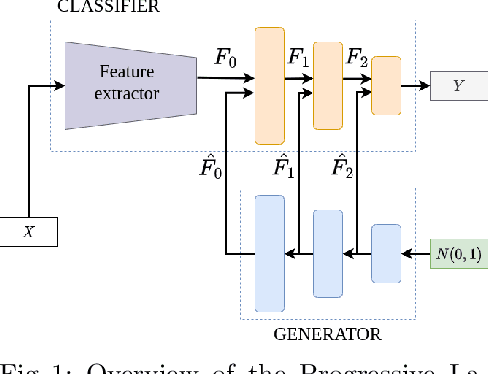
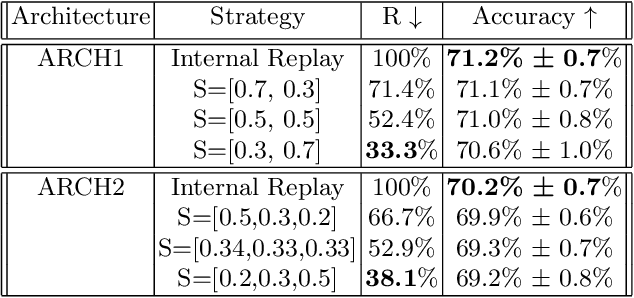

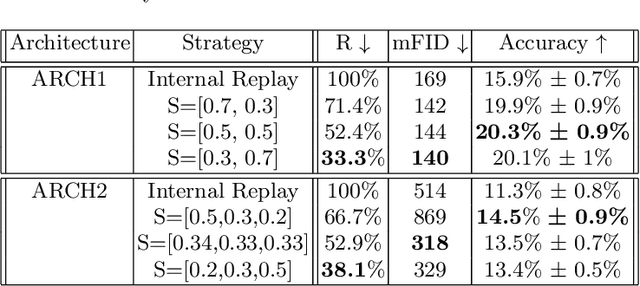
We introduce a new method for internal replay that modulates the frequency of rehearsal based on the depth of the network. While replay strategies mitigate the effects of catastrophic forgetting in neural networks, recent works on generative replay show that performing the rehearsal only on the deeper layers of the network improves the performance in continual learning. However, the generative approach introduces additional computational overhead, limiting its applications. Motivated by the observation that earlier layers of neural networks forget less abruptly, we propose to update network layers with varying frequency using intermediate-level features during replay. This reduces the computational burden by omitting computations for both deeper layers of the generator and earlier layers of the main model. We name our method Progressive Latent Replay and show that it outperforms Internal Replay while using significantly fewer resources.