 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuxley-Gödel Machine: Human-Level Coding Agent Development by an Approximation of the Optimal Self-Improving Machine
Oct 24, 2025Recent studies operationalize self-improvement through coding agents that edit their own codebases. They grow a tree of self-modifications through expansion strategies that favor higher software engineering benchmark performance, assuming that this implies more promising subsequent self-modifications. However, we identify a mismatch between the agent's self-improvement potential (metaproductivity) and its coding benchmark performance, namely the Metaproductivity-Performance Mismatch. Inspired by Huxley's concept of clade, we propose a metric ($\mathrm{CMP}$) that aggregates the benchmark performances of the descendants of an agent as an indicator of its potential for self-improvement. We show that, in our self-improving coding agent development setting, access to the true $\mathrm{CMP}$ is sufficient to simulate how the G\"odel Machine would behave under certain assumptions. We introduce the Huxley-G\"odel Machine (HGM), which, by estimating $\mathrm{CMP}$ and using it as guidance, searches the tree of self-modifications. On SWE-bench Verified and Polyglot, HGM outperforms prior self-improving coding agent development methods while using less wall-clock time. Last but not least, HGM demonstrates strong transfer to other coding datasets and large language models. The agent optimized by HGM on SWE-bench Verified with GPT-5-mini and evaluated on SWE-bench Lite with GPT-5 achieves human-level performance, matching the best officially checked results of human-engineered coding agents. Our code is available at https://github.com/metauto-ai/HGM.
Bigger, Regularized, Optimistic: scaling for compute and sample-efficient continuous control
May 25, 2024



Sample efficiency in Reinforcement Learning (RL) has traditionally been driven by algorithmic enhancements. In this work, we demonstrate that scaling can also lead to substantial improvements. We conduct a thorough investigation into the interplay of scaling model capacity and domain-specific RL enhancements. These empirical findings inform the design choices underlying our proposed BRO (Bigger, Regularized, Optimistic) algorithm. The key innovation behind BRO is that strong regularization allows for effective scaling of the critic networks, which, paired with optimistic exploration, leads to superior performance. BRO achieves state-of-the-art results, significantly outperforming the leading model-based and model-free algorithms across 40 complex tasks from the DeepMind Control, MetaWorld, and MyoSuite benchmarks. BRO is the first model-free algorithm to achieve near-optimal policies in the notoriously challenging Dog and Humanoid tasks.
Overestimation, Overfitting, and Plasticity in Actor-Critic: the Bitter Lesson of Reinforcement Learning
Mar 01, 2024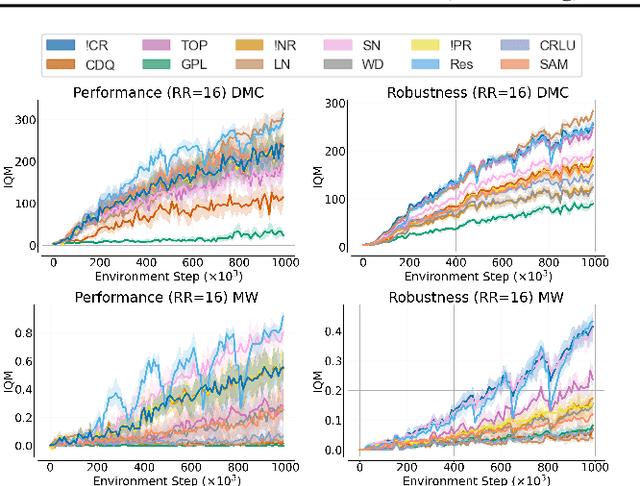

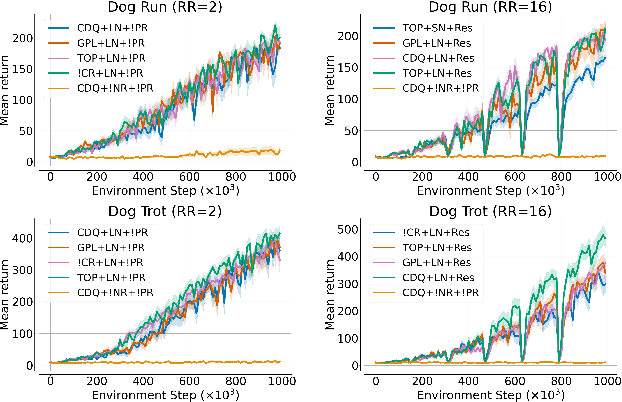
Recent advancements in off-policy Reinforcement Learning (RL) have significantly improved sample efficiency, primarily due to the incorporation of various forms of regularization that enable more gradient update steps than traditional agents. However, many of these techniques have been tested in limited settings, often on tasks from single simulation benchmarks and against well-known algorithms rather than a range of regularization approaches. This limits our understanding of the specific mechanisms driving RL improvements. To address this, we implemented over 60 different off-policy agents, each integrating established regularization techniques from recent state-of-the-art algorithms. We tested these agents across 14 diverse tasks from 2 simulation benchmarks. Our findings reveal that while the effectiveness of a specific regularization setup varies with the task, certain combinations consistently demonstrate robust and superior performance. Notably, a simple Soft Actor-Critic agent, appropriately regularized, reliably solves dog tasks, which were previously solved mainly through model-based approaches.
A Case for Validation Buffer in Pessimistic Actor-Critic
Mar 01, 2024



In this paper, we investigate the issue of error accumulation in critic networks updated via pessimistic temporal difference objectives. We show that the critic approximation error can be approximated via a recursive fixed-point model similar to that of the Bellman value. We use such recursive definition to retrieve the conditions under which the pessimistic critic is unbiased. Building on these insights, we propose Validation Pessimism Learning (VPL) algorithm. VPL uses a small validation buffer to adjust the levels of pessimism throughout the agent training, with the pessimism set such that the approximation error of the critic targets is minimized. We investigate the proposed approach on a variety of locomotion and manipulation tasks and report improvements in sample efficiency and performance.
Fine-tuning Reinforcement Learning Models is Secretly a Forgetting Mitigation Problem
Feb 05, 2024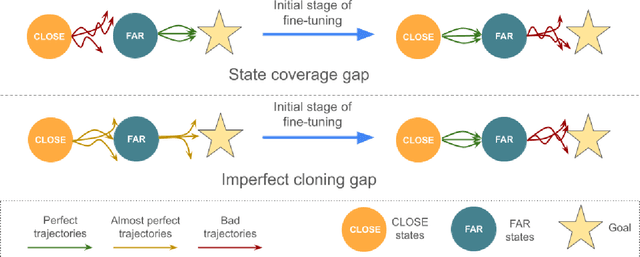
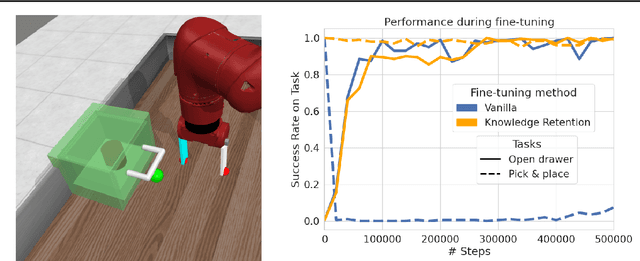
Fine-tuning is a widespread technique that allows practitioners to transfer pre-trained capabilities, as recently showcased by the successful applications of foundation models. However, fine-tuning reinforcement learning (RL) models remains a challenge. This work conceptualizes one specific cause of poor transfer, accentuated in the RL setting by the interplay between actions and observations: forgetting of pre-trained capabilities. Namely, a model deteriorates on the state subspace of the downstream task not visited in the initial phase of fine-tuning, on which the model behaved well due to pre-training. This way, we lose the anticipated transfer benefits. We identify conditions when this problem occurs, showing that it is common and, in many cases, catastrophic. Through a detailed empirical analysis of the challenging NetHack and Montezuma's Revenge environments, we show that standard knowledge retention techniques mitigate the problem and thus allow us to take full advantage of the pre-trained capabilities. In particular, in NetHack, we achieve a new state-of-the-art for neural models, improving the previous best score from $5$K to over $10$K points in the Human Monk scenario.
Curriculum reinforcement learning for quantum architecture search under hardware errors
Feb 05, 2024
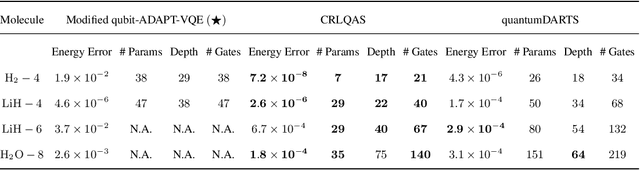


The key challenge in the noisy intermediate-scale quantum era is finding useful circuits compatible with current device limitations. Variational quantum algorithms (VQAs) offer a potential solution by fixing the circuit architecture and optimizing individual gate parameters in an external loop. However, parameter optimization can become intractable, and the overall performance of the algorithm depends heavily on the initially chosen circuit architecture. Several quantum architecture search (QAS) algorithms have been developed to design useful circuit architectures automatically. In the case of parameter optimization alone, noise effects have been observed to dramatically influence the performance of the optimizer and final outcomes, which is a key line of study. However, the effects of noise on the architecture search, which could be just as critical, are poorly understood. This work addresses this gap by introducing a curriculum-based reinforcement learning QAS (CRLQAS) algorithm designed to tackle challenges in realistic VQA deployment. The algorithm incorporates (i) a 3D architecture encoding and restrictions on environment dynamics to explore the search space of possible circuits efficiently, (ii) an episode halting scheme to steer the agent to find shorter circuits, and (iii) a novel variant of simultaneous perturbation stochastic approximation as an optimizer for faster convergence. To facilitate studies, we developed an optimized simulator for our algorithm, significantly improving computational efficiency in simulating noisy quantum circuits by employing the Pauli-transfer matrix formalism in the Pauli-Liouville basis. Numerical experiments focusing on quantum chemistry tasks demonstrate that CRLQAS outperforms existing QAS algorithms across several metrics in both noiseless and noisy environments.
On consequences of finetuning on data with highly discriminative features
Oct 30, 2023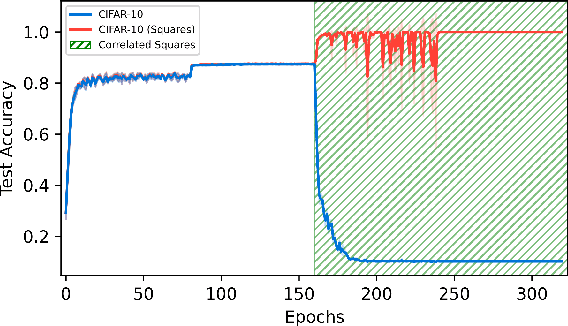


In the era of transfer learning, training neural networks from scratch is becoming obsolete. Transfer learning leverages prior knowledge for new tasks, conserving computational resources. While its advantages are well-documented, we uncover a notable drawback: networks tend to prioritize basic data patterns, forsaking valuable pre-learned features. We term this behavior "feature erosion" and analyze its impact on network performance and internal representations.
Enhancing variational quantum state diagonalization using reinforcement learning techniques
Jun 22, 2023The development of variational quantum algorithms is crucial for the application of NISQ computers. Such algorithms require short quantum circuits, which are more amenable to implementation on near-term hardware, and many such methods have been developed. One of particular interest is the so-called the variational diagonalization method, which constitutes an important algorithmic subroutine, and it can be used directly for working with data encoded in quantum states. In particular, it can be applied to discern the features of quantum states, such as entanglement properties of a system, or in quantum machine learning algorithms. In this work, we tackle the problem of designing a very shallow quantum circuit, required in the quantum state diagonalization task, by utilizing reinforcement learning. To achieve this, we utilize a novel encoding method that can be used to tackle the problem of circuit depth optimization using a reinforcement learning approach. We demonstrate that our approach provides a solid approximation to the diagonalization task while using a small number of gates. The circuits proposed by the reinforcement learning methods are shallower than the standard variational quantum state diagonalization algorithm, and thus can be used in situations where the depth of quantum circuits is limited by the hardware capabilities.
The Tunnel Effect: Building Data Representations in Deep Neural Networks
May 31, 2023
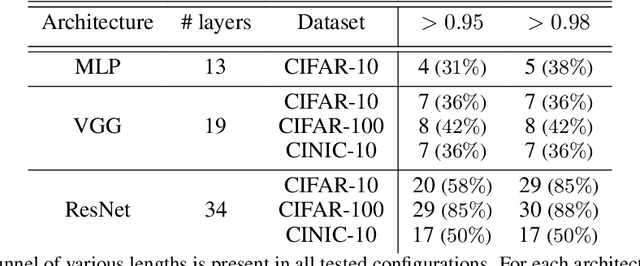
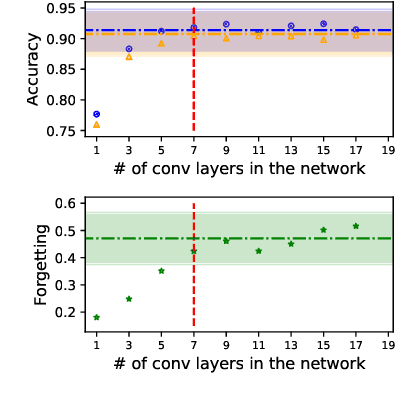
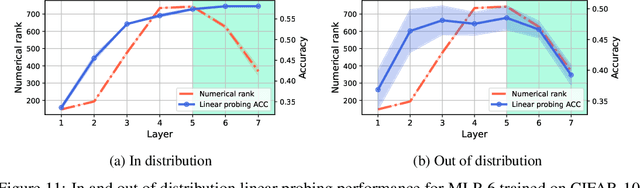
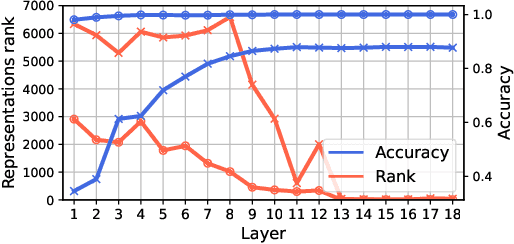
Deep neural networks are widely known for their remarkable effectiveness across various tasks, with the consensus that deeper networks implicitly learn more complex data representations. This paper shows that sufficiently deep networks trained for supervised image classification split into two distinct parts that contribute to the resulting data representations differently. The initial layers create linearly-separable representations, while the subsequent layers, which we refer to as \textit{the tunnel}, compress these representations and have a minimal impact on the overall performance. We explore the tunnel's behavior through comprehensive empirical studies, highlighting that it emerges early in the training process. Its depth depends on the relation between the network's capacity and task complexity. Furthermore, we show that the tunnel degrades out-of-distribution generalization and discuss its implications for continual learning.
Emergency action termination for immediate reaction in hierarchical reinforcement learning
Nov 11, 2022



Hierarchical decomposition of control is unavoidable in large dynamical systems. In reinforcement learning (RL), it is usually solved with subgoals defined at higher policy levels and achieved at lower policy levels. Reaching these goals can take a substantial amount of time, during which it is not verified whether they are still worth pursuing. However, due to the randomness of the environment, these goals may become obsolete. In this paper, we address this gap in the state-of-the-art approaches and propose a method in which the validity of higher-level actions (thus lower-level goals) is constantly verified at the higher level. If the actions, i.e. lower level goals, become inadequate, they are replaced by more appropriate ones. This way we combine the advantages of hierarchical RL, which is fast training, and flat RL, which is immediate reactivity. We study our approach experimentally on seven benchmark environments.