 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Diversity-Aware Domain Adaptation for 3D Object detection
Dec 31, 20253D object detectors are fundamental components of perception systems in autonomous vehicles. While these detectors achieve remarkable performance on standard autonomous driving benchmarks, they often struggle to generalize across different domains - for instance, a model trained in the U.S. may perform poorly in regions like Asia or Europe. This paper presents a novel lidar domain adaptation method based on neuron activation patterns, demonstrating that state-of-the-art performance can be achieved by annotating only a small, representative, and diverse subset of samples from the target domain if they are correctly selected. The proposed approach requires very small annotation budget and, when combined with post-training techniques inspired by continual learning prevent weight drift from the original model. Empirical evaluation shows that the proposed domain adaptation approach outperforms both linear probing and state-of-the-art domain adaptation techniques.
SACn: Soft Actor-Critic with n-step Returns
Dec 15, 2025



Soft Actor-Critic (SAC) is widely used in practical applications and is now one of the most relevant off-policy online model-free reinforcement learning (RL) methods. The technique of n-step returns is known to increase the convergence speed of RL algorithms compared to their 1-step returns-based versions. However, SAC is notoriously difficult to combine with n-step returns, since their usual combination introduces bias in off-policy algorithms due to the changes in action distribution. While this problem is solved by importance sampling, a method for estimating expected values of one distribution using samples from another distribution, importance sampling may result in numerical instability. In this work, we combine SAC with n-step returns in a way that overcomes this issue. We present an approach to applying numerically stable importance sampling with simplified hyperparameter selection. Furthermore, we analyze the entropy estimation approach of Soft Actor-Critic in the context of the n-step maximum entropy framework and formulate the $τ$-sampled entropy estimation to reduce the variance of the learning target. Finally, we formulate the Soft Actor-Critic with n-step returns (SAC$n$) algorithm that we experimentally verify on MuJoCo simulated environments.
HyperInterval: Hypernetwork approach to training weight interval regions in continual learning
May 27, 2024Recently, a new Continual Learning (CL) paradigm was presented to control catastrophic forgetting, called Interval Continual Learning (InterContiNet), which relies on enforcing interval constraints on the neural network parameter space. Unfortunately, InterContiNet training is challenging due to the high dimensionality of the weight space, making intervals difficult to manage. To address this issue, we introduce HyperInterval, a technique that employs interval arithmetic within the embedding space and utilizes a hypernetwork to map these intervals to the target network parameter space. We train interval embeddings for consecutive tasks and train a hypernetwork to transform these embeddings into weights of the target network. An embedding for a given task is trained along with the hypernetwork, preserving the response of the target network for the previous task embeddings. Interval arithmetic works with a more manageable, lower-dimensional embedding space rather than directly preparing intervals in a high-dimensional weight space. Our model allows faster and more efficient training. Furthermore, HyperInterval maintains the guarantee of not forgetting. At the end of training, we can choose one universal embedding to produce a single network dedicated to all tasks. In such a framework, hypernetwork is used only for training and can be seen as a meta-trainer. HyperInterval obtains significantly better results than InterContiNet and gives SOTA results on several benchmarks.
Graph Vertex Embeddings: Distance, Regularization and Community Detection
Apr 09, 2024



Graph embeddings have emerged as a powerful tool for representing complex network structures in a low-dimensional space, enabling the use of efficient methods that employ the metric structure in the embedding space as a proxy for the topological structure of the data. In this paper, we explore several aspects that affect the quality of a vertex embedding of graph-structured data. To this effect, we first present a family of flexible distance functions that faithfully capture the topological distance between different vertices. Secondly, we analyze vertex embeddings as resulting from a fitted transformation of the distance matrix rather than as a direct result of optimization. Finally, we evaluate the effectiveness of our proposed embedding constructions by performing community detection on a host of benchmark datasets. The reported results are competitive with classical algorithms that operate on the entire graph while benefitting from a substantially reduced computational complexity due to the reduced dimensionality of the representations.
Actor-Critic with variable time discretization via sustained actions
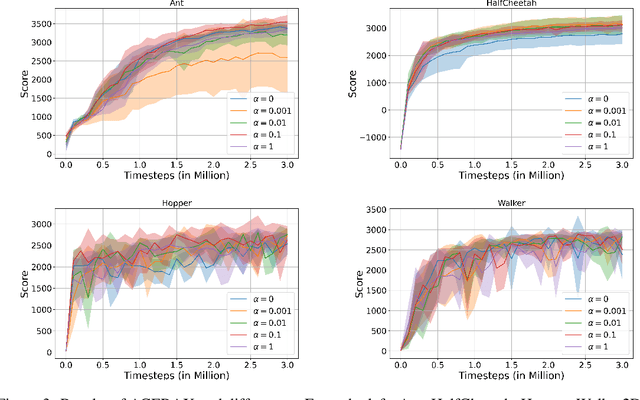
Aug 08, 2023Reinforcement learning (RL) methods work in discrete time. In order to apply RL to inherently continuous problems like robotic control, a specific time discretization needs to be defined. This is a choice between sparse time control, which may be easier to train, and finer time control, which may allow for better ultimate performance. In this work, we propose SusACER, an off-policy RL algorithm that combines the advantages of different time discretization settings. Initially, it operates with sparse time discretization and gradually switches to a fine one. We analyze the effects of the changing time discretization in robotic control environments: Ant, HalfCheetah, Hopper, and Walker2D. In all cases our proposed algorithm outperforms state of the art.
Reinforcement learning for optimization of energy trading strategy
Mar 28, 2023An increasing part of energy is produced from renewable sources by a large number of small producers. The efficiency of these sources is volatile and, to some extent, random, exacerbating the energy market balance problem. In many countries, that balancing is performed on day-ahead (DA) energy markets. In this paper, we consider automated trading on a DA energy market by a medium size prosumer. We model this activity as a Markov Decision Process and formalize a framework in which a ready-to-use strategy can be optimized with real-life data. We synthesize parametric trading strategies and optimize them with an evolutionary algorithm. We also use state-of-the-art reinforcement learning algorithms to optimize a black-box trading strategy fed with available information from the environment that can impact future prices.
Emergency action termination for immediate reaction in hierarchical reinforcement learning
Nov 11, 2022Hierarchical decomposition of control is unavoidable in large dynamical systems. In reinforcement learning (RL), it is usually solved with subgoals defined at higher policy levels and achieved at lower policy levels. Reaching these goals can take a substantial amount of time, during which it is not verified whether they are still worth pursuing. However, due to the randomness of the environment, these goals may become obsolete. In this paper, we address this gap in the state-of-the-art approaches and propose a method in which the validity of higher-level actions (thus lower-level goals) is constantly verified at the higher level. If the actions, i.e. lower level goals, become inadequate, they are replaced by more appropriate ones. This way we combine the advantages of hierarchical RL, which is fast training, and flat RL, which is immediate reactivity. We study our approach experimentally on seven benchmark environments.
Reinforcement learning with experience replay and adaptation of action dispersion
Jul 30, 2022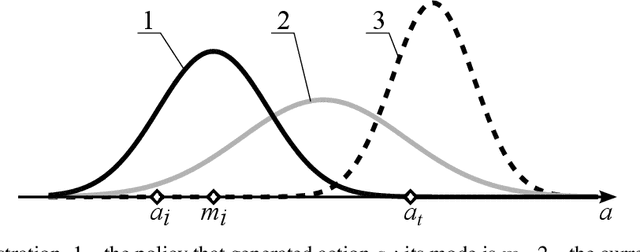


Effective reinforcement learning requires a proper balance of exploration and exploitation defined by the dispersion of action distribution. However, this balance depends on the task, the current stage of the learning process, and the current environment state. Existing methods that designate the action distribution dispersion require problem-dependent hyperparameters. In this paper, we propose to automatically designate the action distribution dispersion using the following principle: This distribution should have sufficient dispersion to enable the evaluation of future policies. To that end, the dispersion should be tuned to assure a sufficiently high probability (densities) of the actions in the replay buffer and the modes of the distributions that generated them, yet this dispersion should not be higher. This way, a policy can be effectively evaluated based on the actions in the buffer, but exploratory randomness in actions decreases when this policy converges. The above principle is verified here on challenging benchmarks Ant, HalfCheetah, Hopper, and Walker2D, with good results. Our method makes the action standard deviations converge to values similar to those resulting from trial-and-error optimization.
Graph autoencoder with constant dimensional latent space
Feb 16, 2022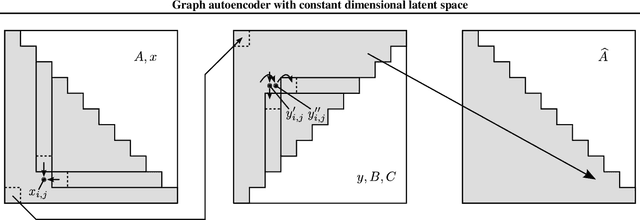
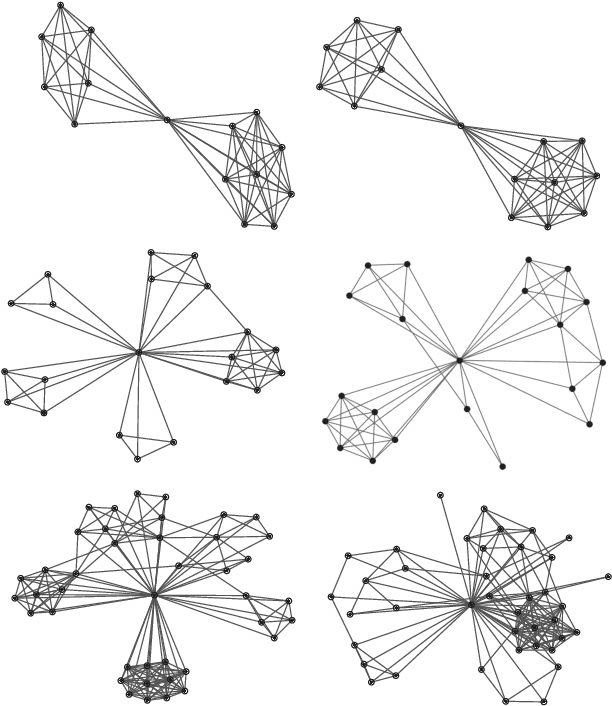
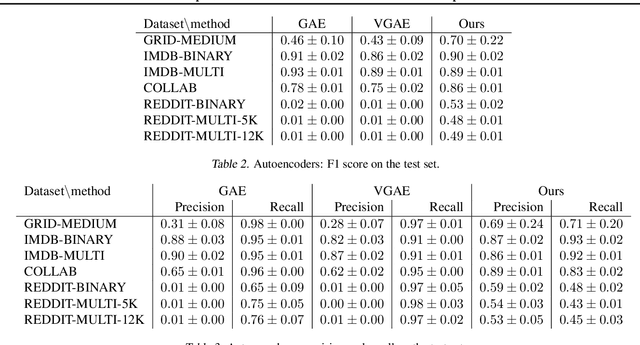
Invertible transformation of large graphs into constant dimensional vectors (embeddings) remains a challenge. In this paper we address it with recursive neural networks: The encoder and the decoder. The encoder network transforms embeddings of subgraphs into embeddings of larger subgraphs, and eventually into the embedding of the input graph. The decoder does the opposite. The dimension of the embeddings is constant regardless of the size of the (sub)graphs. Simulation experiments presented in this paper confirm that our proposed graph autoencoder can handle graphs with even thousands of vertices.
Logarithmic Continual Learning
Jan 17, 2022We introduce a neural network architecture that logarithmically reduces the number of self-rehearsal steps in the generative rehearsal of continually learned models. In continual learning (CL), training samples come in subsequent tasks, and the trained model can access only a single task at a time. To replay previous samples, contemporary CL methods bootstrap generative models and train them recursively with a combination of current and regenerated past data. This recurrence leads to superfluous computations as the same past samples are regenerated after each task, and the reconstruction quality successively degrades. In this work, we address these limitations and propose a new generative rehearsal architecture that requires at most logarithmic number of retraining for each sample. Our approach leverages allocation of past data in a~set of generative models such that most of them do not require retraining after a~task. The experimental evaluation of our logarithmic continual learning approach shows the superiority of our method with respect to the state-of-the-art generative rehearsal methods.