 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSACn: Soft Actor-Critic with n-step Returns
Dec 15, 2025



Soft Actor-Critic (SAC) is widely used in practical applications and is now one of the most relevant off-policy online model-free reinforcement learning (RL) methods. The technique of n-step returns is known to increase the convergence speed of RL algorithms compared to their 1-step returns-based versions. However, SAC is notoriously difficult to combine with n-step returns, since their usual combination introduces bias in off-policy algorithms due to the changes in action distribution. While this problem is solved by importance sampling, a method for estimating expected values of one distribution using samples from another distribution, importance sampling may result in numerical instability. In this work, we combine SAC with n-step returns in a way that overcomes this issue. We present an approach to applying numerically stable importance sampling with simplified hyperparameter selection. Furthermore, we analyze the entropy estimation approach of Soft Actor-Critic in the context of the n-step maximum entropy framework and formulate the $τ$-sampled entropy estimation to reduce the variance of the learning target. Finally, we formulate the Soft Actor-Critic with n-step returns (SAC$n$) algorithm that we experimentally verify on MuJoCo simulated environments.
Actor-Critic with variable time discretization via sustained actions
Aug 08, 2023


Reinforcement learning (RL) methods work in discrete time. In order to apply RL to inherently continuous problems like robotic control, a specific time discretization needs to be defined. This is a choice between sparse time control, which may be easier to train, and finer time control, which may allow for better ultimate performance. In this work, we propose SusACER, an off-policy RL algorithm that combines the advantages of different time discretization settings. Initially, it operates with sparse time discretization and gradually switches to a fine one. We analyze the effects of the changing time discretization in robotic control environments: Ant, HalfCheetah, Hopper, and Walker2D. In all cases our proposed algorithm outperforms state of the art.
Detecting Out-of-distribution Objects Using Neuron Activation Patterns
Jul 31, 2023Object detection is essential to many perception algorithms used in modern robotics applications. Unfortunately, the existing models share a tendency to assign high confidence scores for out-of-distribution (OOD) samples. Although OOD detection has been extensively studied in recent years by the computer vision (CV) community, most proposed solutions apply only to the image recognition task. Real-world applications such as perception in autonomous vehicles struggle with far more complex challenges than classification. In our work, we focus on the prevalent field of object detection, introducing Neuron Activation PaTteRns for out-of-distribution samples detection in Object detectioN (NAPTRON). Performed experiments show that our approach outperforms state-of-the-art methods, without the need to affect in-distribution (ID) performance. By evaluating the methods in two distinct OOD scenarios and three types of object detectors we have created the largest open-source benchmark for OOD object detection.
Combating noisy labels in object detection datasets
Nov 25, 2022



The quality of training datasets for deep neural networks is a key factor contributing to the accuracy of resulting models. This is even more important in difficult tasks such as object detection. Dealing with errors in these datasets was in the past limited to accepting that some fraction of examples is incorrect or predicting their confidence and assigning appropriate weights during training. In this work, we propose a different approach. For the first time, we extended the confident learning algorithm to the object detection task. By focusing on finding incorrect labels in the original training datasets, we can eliminate erroneous examples in their root. Suspicious bounding boxes can be re-annotated in order to improve the quality of the dataset itself, thus leading to better models without complicating their already complex architectures. We can effectively point out 99\% of artificially disturbed bounding boxes with FPR below 0.3. We see this method as a promising path to correcting well-known object detection datasets.
Emergency action termination for immediate reaction in hierarchical reinforcement learning
Nov 11, 2022



Hierarchical decomposition of control is unavoidable in large dynamical systems. In reinforcement learning (RL), it is usually solved with subgoals defined at higher policy levels and achieved at lower policy levels. Reaching these goals can take a substantial amount of time, during which it is not verified whether they are still worth pursuing. However, due to the randomness of the environment, these goals may become obsolete. In this paper, we address this gap in the state-of-the-art approaches and propose a method in which the validity of higher-level actions (thus lower-level goals) is constantly verified at the higher level. If the actions, i.e. lower level goals, become inadequate, they are replaced by more appropriate ones. This way we combine the advantages of hierarchical RL, which is fast training, and flat RL, which is immediate reactivity. We study our approach experimentally on seven benchmark environments.
ACERAC: Efficient reinforcement learning in fine time discretization
Apr 08, 2021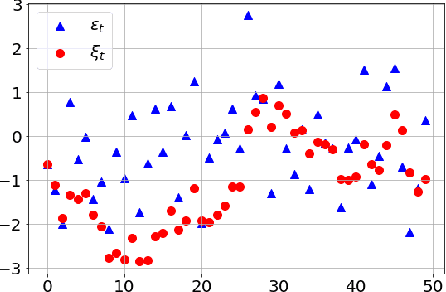
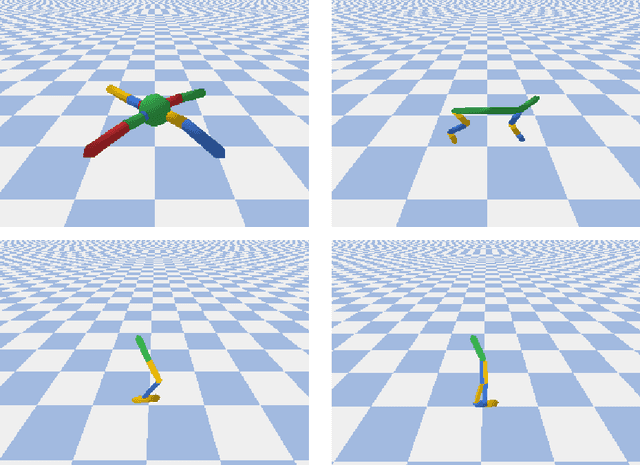
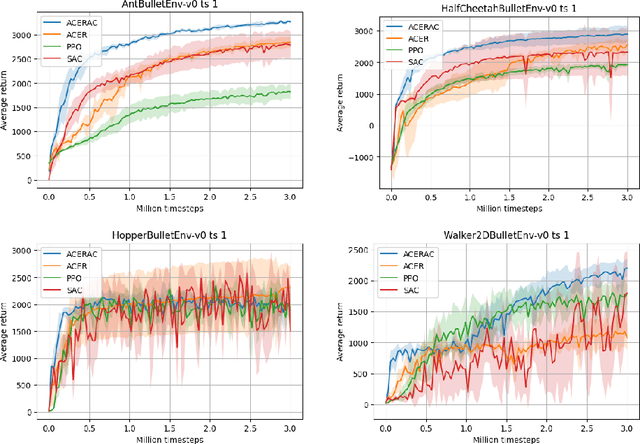

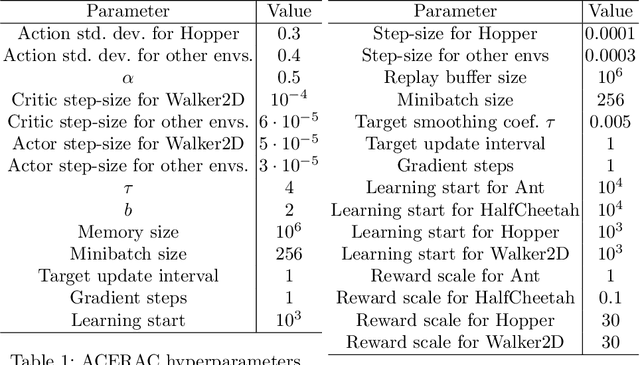
We propose a framework for reinforcement learning (RL) in fine time discretization and a learning algorithm in this framework. One of the main goals of RL is to provide a way for physical machines to learn optimal behavior instead of being programmed. However, the machines are usually controlled in fine time discretization. The most common RL methods apply independent random elements to each action, which is not suitable in that setting. It is not feasible because it causes the controlled system to jerk, and does not ensure sufficient exploration since a single action is not long enough to create a significant experience that could be translated into policy improvement. In the RL framework introduced in this paper, policies are considered that produce actions based on states and random elements autocorrelated in subsequent time instants. The RL algorithm introduced here approximately optimizes such a policy. The efficiency of this algorithm is verified against three other RL methods (PPO, SAC, ACER) in four simulated learning control problems (Ant, HalfCheetah, Hopper, and Walker2D) in diverse time discretization. The algorithm introduced here outperforms the competitors in most cases considered.
A framework for reinforcement learning with autocorrelated actions
Sep 10, 2020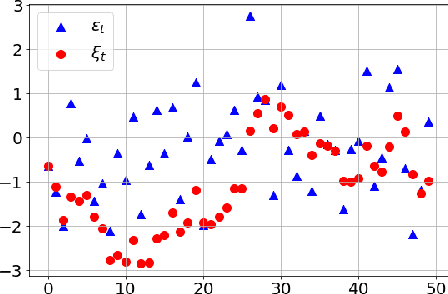
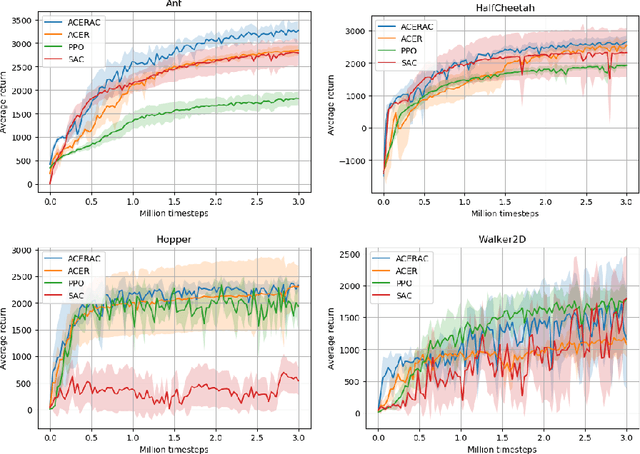
The subject of this paper is reinforcement learning. Policies are considered here that produce actions based on states and random elements autocorrelated in subsequent time instants. Consequently, an agent learns from experiments that are distributed over time and potentially give better clues to policy improvement. Also, physical implementation of such policies, e.g. in robotics, is less problematic, as it avoids making robots shake. This is in opposition to most RL algorithms which add white noise to control causing unwanted shaking of the robots. An algorithm is introduced here that approximately optimizes the aforementioned policy. Its efficiency is verified for four simulated learning control problems (Ant, HalfCheetah, Hopper, and Walker2D) against three other methods (PPO, SAC, ACER). The algorithm outperforms others in three of these problems.