 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Vectors: a Task Arithmetic View on Backdoor Attacks and Defenses
Oct 09, 2025Model merging (MM) recently emerged as an effective method for combining large deep learning models. However, it poses significant security risks. Recent research shows that it is highly susceptible to backdoor attacks, which introduce a hidden trigger into a single fine-tuned model instance that allows the adversary to control the output of the final merged model at inference time. In this work, we propose a simple framework for understanding backdoor attacks by treating the attack itself as a task vector. $Backdoor\ Vector\ (BV)$ is calculated as the difference between the weights of a fine-tuned backdoored model and fine-tuned clean model. BVs reveal new insights into attacks understanding and a more effective framework to measure their similarity and transferability. Furthermore, we propose a novel method that enhances backdoor resilience through merging dubbed $Sparse\ Backdoor\ Vector\ (SBV)$ that combines multiple attacks into a single one. We identify the core vulnerability behind backdoor threats in MM: $inherent\ triggers$ that exploit adversarial weaknesses in the base model. To counter this, we propose $Injection\ BV\ Subtraction\ (IBVS)$ - an assumption-free defense against backdoors in MM. Our results show that SBVs surpass prior attacks and is the first method to leverage merging to improve backdoor effectiveness. At the same time, IBVS provides a lightweight, general defense that remains effective even when the backdoor threat is entirely unknown.
No Task Left Behind: Isotropic Model Merging with Common and Task-Specific Subspaces
Feb 07, 2025Model merging integrates the weights of multiple task-specific models into a single multi-task model. Despite recent interest in the problem, a significant performance gap between the combined and single-task models remains. In this paper, we investigate the key characteristics of task matrices -- weight update matrices applied to a pre-trained model -- that enable effective merging. We show that alignment between singular components of task-specific and merged matrices strongly correlates with performance improvement over the pre-trained model. Based on this, we propose an isotropic merging framework that flattens the singular value spectrum of task matrices, enhances alignment, and reduces the performance gap. Additionally, we incorporate both common and task-specific subspaces to further improve alignment and performance. Our proposed approach achieves state-of-the-art performance across multiple scenarios, including various sets of tasks and model scales. This work advances the understanding of model merging dynamics, offering an effective methodology to merge models without requiring additional training. Code is available at https://github.com/danielm1405/iso-merging .
Parameter-Efficient Interventions for Enhanced Model Merging
Dec 22, 2024



Model merging combines knowledge from task-specific models into a unified multi-task model to avoid joint training on all task data. However, current methods face challenges due to representation bias, which can interfere with tasks performance. As a remedy, we propose IntervMerge, a novel approach to multi-task model merging that effectively mitigates representation bias across the model using taskspecific interventions. To further enhance its efficiency, we introduce mini-interventions, which modify only part of the representation, thereby reducing the additional parameters without compromising performance. Experimental results demonstrate that IntervMerge consistently outperforms the state-of-the-art approaches using fewer parameters.
Exploring the Stability Gap in Continual Learning: The Role of the Classification Head
Nov 06, 2024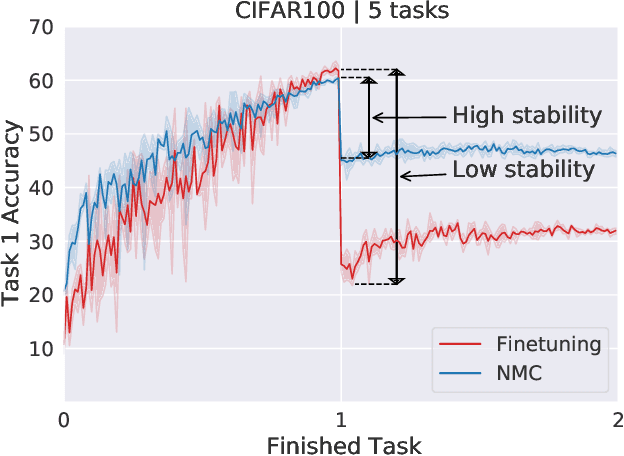
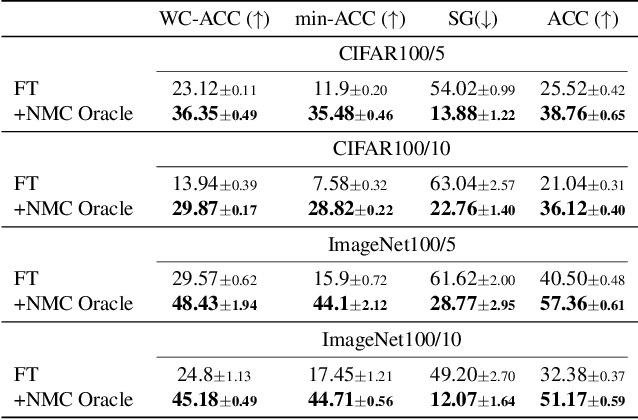

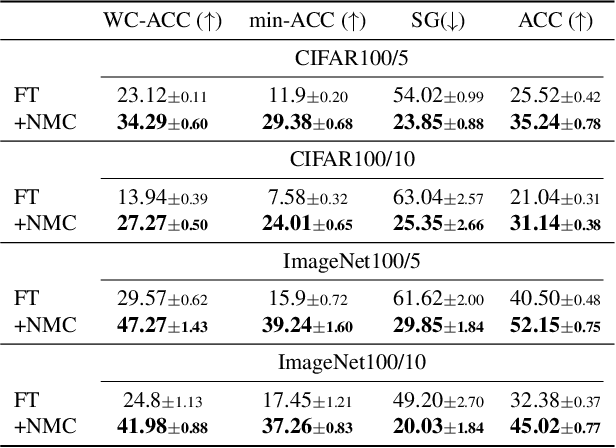
Continual learning (CL) has emerged as a critical area in machine learning, enabling neural networks to learn from evolving data distributions while mitigating catastrophic forgetting. However, recent research has identified the stability gap -- a phenomenon where models initially lose performance on previously learned tasks before partially recovering during training. Such learning dynamics are contradictory to the intuitive understanding of stability in continual learning where one would expect the performance to degrade gradually instead of rapidly decreasing and then partially recovering later. To better understand and alleviate the stability gap, we investigate it at different levels of the neural network architecture, particularly focusing on the role of the classification head. We introduce the nearest-mean classifier (NMC) as a tool to attribute the influence of the backbone and the classification head on the stability gap. Our experiments demonstrate that NMC not only improves final performance, but also significantly enhances training stability across various continual learning benchmarks, including CIFAR100, ImageNet100, CUB-200, and FGVC Aircrafts. Moreover, we find that NMC also reduces task-recency bias. Our analysis provides new insights into the stability gap and suggests that the primary contributor to this phenomenon is the linear head, rather than the insufficient representation learning.
MagMax: Leveraging Model Merging for Seamless Continual Learning
Jul 08, 2024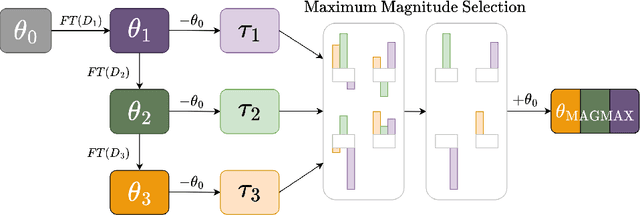
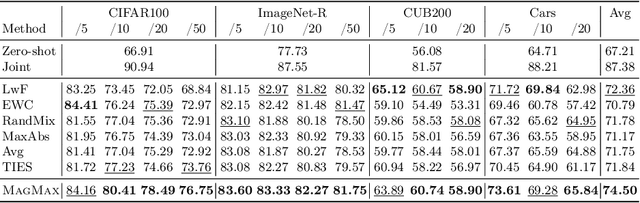
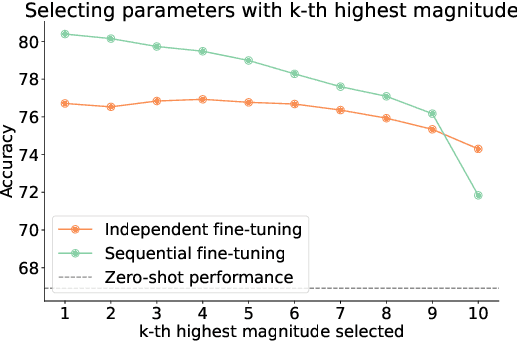
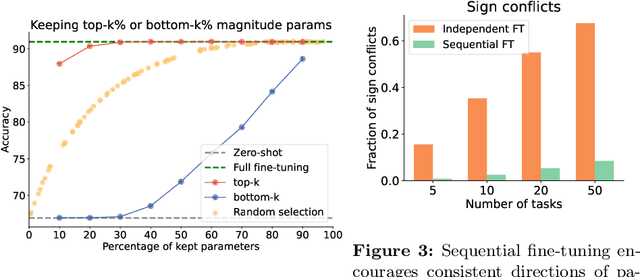
This paper introduces a continual learning approach named MagMax, which utilizes model merging to enable large pre-trained models to continuously learn from new data without forgetting previously acquired knowledge. Distinct from traditional continual learning methods that aim to reduce forgetting during task training, MagMax combines sequential fine-tuning with a maximum magnitude weight selection for effective knowledge integration across tasks. Our initial contribution is an extensive examination of model merging techniques, revealing that simple approaches like weight averaging and random weight selection surprisingly hold up well in various continual learning contexts. More importantly, we present MagMax, a novel model-merging strategy that enables continual learning of large pre-trained models for successive tasks. Our thorough evaluation demonstrates the superiority of MagMax in various scenarios, including class- and domain-incremental learning settings.
Revisiting Supervision for Continual Representation Learning
Nov 22, 2023



In the field of continual learning, models are designed to learn tasks one after the other. While most research has centered on supervised continual learning, recent studies have highlighted the strengths of self-supervised continual representation learning. The improved transferability of representations built with self-supervised methods is often associated with the role played by the multi-layer perceptron projector. In this work, we depart from this observation and reexamine the role of supervision in continual representation learning. We reckon that additional information, such as human annotations, should not deteriorate the quality of representations. Our findings show that supervised models when enhanced with a multi-layer perceptron head, can outperform self-supervised models in continual representation learning.
Generalized Continual Category Discovery
Aug 23, 2023Most of Continual Learning (CL) methods push the limit of supervised learning settings, where an agent is expected to learn new labeled tasks and not forget previous knowledge. However, these settings are not well aligned with real-life scenarios, where a learning agent has access to a vast amount of unlabeled data encompassing both novel (entirely unlabeled) classes and examples from known classes. Drawing inspiration from Generalized Category Discovery (GCD), we introduce a novel framework that relaxes this assumption. Precisely, in any task, we allow for the existence of novel and known classes, and one must use continual version of unsupervised learning methods to discover them. We call this setting Generalized Continual Category Discovery (GCCD). It unifies CL and GCD, bridging the gap between synthetic benchmarks and real-life scenarios. With a series of experiments, we present that existing methods fail to accumulate knowledge from subsequent tasks in which unlabeled samples of novel classes are present. In light of these limitations, we propose a method that incorporates both supervised and unsupervised signals and mitigates the forgetting through the use of centroid adaptation. Our method surpasses strong CL methods adopted for GCD techniques and presents a superior representation learning performance.
Logarithmic Continual Learning
Jan 17, 2022We introduce a neural network architecture that logarithmically reduces the number of self-rehearsal steps in the generative rehearsal of continually learned models. In continual learning (CL), training samples come in subsequent tasks, and the trained model can access only a single task at a time. To replay previous samples, contemporary CL methods bootstrap generative models and train them recursively with a combination of current and regenerated past data. This recurrence leads to superfluous computations as the same past samples are regenerated after each task, and the reconstruction quality successively degrades. In this work, we address these limitations and propose a new generative rehearsal architecture that requires at most logarithmic number of retraining for each sample. Our approach leverages allocation of past data in a~set of generative models such that most of them do not require retraining after a~task. The experimental evaluation of our logarithmic continual learning approach shows the superiority of our method with respect to the state-of-the-art generative rehearsal methods.
Multiband VAE: Latent Space Partitioning for Knowledge Consolidation in Continual Learning
Jun 23, 2021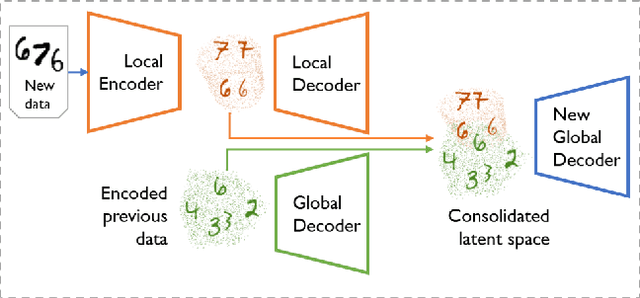
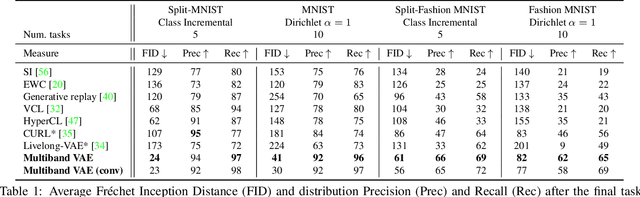
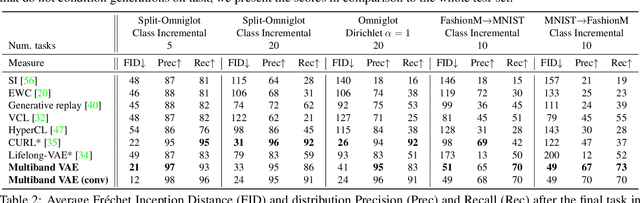
We propose a new method for unsupervised continual knowledge consolidation in generative models that relies on the partitioning of Variational Autoencoder's latent space. Acquiring knowledge about new data samples without forgetting previous ones is a critical problem of continual learning. Currently proposed methods achieve this goal by extending the existing model while constraining its behavior not to degrade on the past data, which does not exploit the full potential of relations within the entire training dataset. In this work, we identify this limitation and posit the goal of continual learning as a knowledge accumulation task. We solve it by continuously re-aligning latent space partitions that we call bands which are representations of samples seen in different tasks, driven by the similarity of the information they contain. In addition, we introduce a simple yet effective method for controlled forgetting of past data that improves the quality of reconstructions encoded in latent bands and a latent space disentanglement technique that improves knowledge consolidation. On top of the standard continual learning evaluation benchmarks, we evaluate our method on a new knowledge consolidation scenario and show that the proposed approach outperforms state-of-the-art by up to twofold across all testing scenarios.
BinPlay: A Binary Latent Autoencoder for Generative Replay Continual Learning
Nov 25, 2020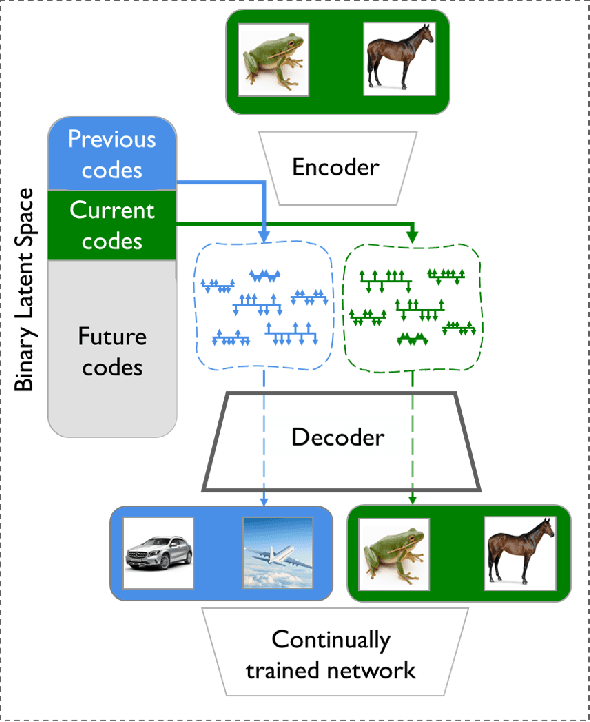

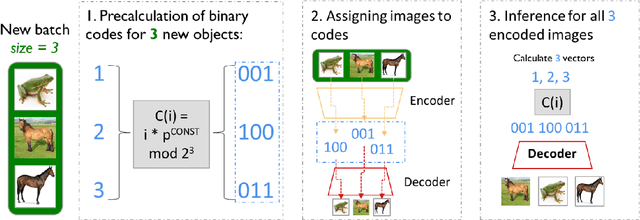
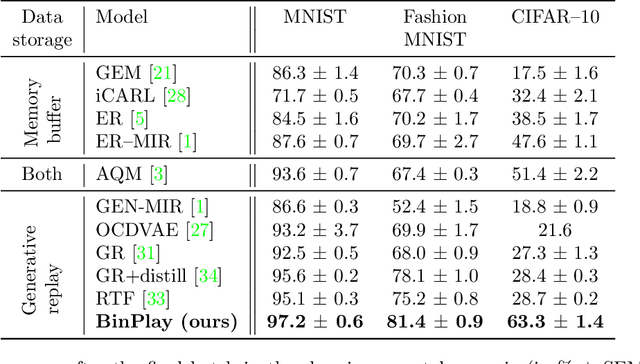
We introduce a binary latent space autoencoder architecture to rehearse training samples for the continual learning of neural networks. The ability to extend the knowledge of a model with new data without forgetting previously learned samples is a fundamental requirement in continual learning. Existing solutions address it by either replaying past data from memory, which is unsustainable with growing training data, or by reconstructing past samples with generative models that are trained to generalize beyond training data and, hence, miss important details of individual samples. In this paper, we take the best of both worlds and introduce a novel generative rehearsal approach called BinPlay. Its main objective is to find a quality-preserving encoding of past samples into precomputed binary codes living in the autoencoder's binary latent space. Since we parametrize the formula for precomputing the codes only on the chronological indices of the training samples, the autoencoder is able to compute the binary embeddings of rehearsed samples on the fly without the need to keep them in memory. Evaluation on three benchmark datasets shows up to a twofold accuracy improvement of BinPlay versus competing generative replay methods.