 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Reliability Gap in Benchmark Auditing: Distribution Shift and Scale as Failure Modes of Contamination Detection
Jun 02, 2026Benchmark contamination, where evaluation examples appear in a model's training data, threatens the validity of LLM assessment. Statistical tools for detecting training-data membership exist, but have been validated almost exclusively in controlled academic regimes: large, homogeneous pre-training corpora and transparent, single-stage training pipelines. Whether these methods remain reliable in realistic auditing scenarios remains unclear. We identify two under-studied failure modes: distribution shift, which arises when suspect and validation sets violate the IID assumption, and scale constraints, which arise because benchmarks are orders of magnitude smaller than pre-training corpora. We systematically evaluate three leading paradigms: LLM Dataset Inference, Post-Hoc Dataset Inference, and CoDeC across 27 models from multiple families (including Pythia, OLMo~2, and specialised cultural and medical LLMs) and scales (up to 27B). We then further extend our analysis to frontier industry models. Across 335 evaluations, only 199 yield correct outcomes. LLM Dataset Inference results in false positives under distribution shift, Post-Hoc Dataset Inference is underpowered at benchmark scale, and CoDeC provides only coarse provenance signals that are insufficient to verify individual benchmark splits. Our results reveal a systematic reliability gap between controlled validation and practical benchmark auditing, and show that statistical detection cannot yet replace transparent data provenance. We open-source our benchmark for further research.
Beyond Classification: Dynamic Adapter Routing for Continual Multimodal Retrieval
May 29, 2026While retrieval is a core function of vision-language models, continually updating these models for retrieval tasks remains critically underexplored. Existing work often approaches continual retrieval through the lens of class-incremental learning (CIL), evaluating both standard CIL methods and retrieval-oriented adaptations in settings that may not fully capture the retrieval-specific dynamics. To address this, we introduce a new, principled evaluation framework for continual multimodal retrieval (CMR) spanning diverse visual domains, and systematically evaluate common approaches within this setting. Our empirical analysis shows that standard CIL methods fail to yield meaningful gains in our more challenging scenario. Therefore, we propose Dynamic Adapter Routing (DAR), a novel approach based on adapters selected through prototype-based routing and combined via model merging.DAR achieves superior performance over the previous baselines and demonstrates strong generalization under out-of-distribution evaluation. Our results highlights the unique challenges of CMR and encourages further research in this direction.
Monitoring the Internal Monologue: Probe Trajectories Reveal Reasoning Dynamics
May 18, 2026Large Reasoning Models (LRMs) introduce new opportunities for safety monitoring through their Chain of Thought (CoT) reasoning. However, CoT is not always faithful to the model's final output, undermining its reliability as a monitoring tool. To address this, we investigate the hidden representations of LRMs to determine whether future behavior can be predicted from prompt and CoT representations. By evaluating a probe at each generated token, we construct a probe trajectory, the continuous evolution of a concept's probability across the reasoning process. We find that future model behavior is more distinguishable when examined over the full trajectory than from a single static prediction. To characterize these temporal dynamics, we extract signal-processing features that capture volatility, trend, and steady-state behavior, significantly improving the separation of future model states. We also present two methodological insights. First, template-based training data achieves near-parity with dynamically generated model responses, eliminating the need for a costly initial inference and labeling. Second, the choice of pooling operation is critical: average-pooling and last-token methods collapse to near-random performance, while max-pooling achieves up to 95% AUROC and yields stable probe trajectories. Using four datasets and four reasoning models across the domains of safety and mathematics, we demonstrate that trajectory features encode task-specific dynamics that improve outcome separability. These findings establish probe trajectories as a complementary framework for monitoring LRM behavior. Warning: This article contains potentially harmful content.
Subspace Optimization for Backpropagation-Free Continual Test-Time Adaptation
Mar 30, 2026We introduce PACE, a backpropagation-free continual test-time adaptation system that directly optimizes the affine parameters of normalization layers. Existing derivative-free approaches struggle to balance runtime efficiency with learning capacity, as they either restrict updates to input prompts or require continuous, resource-intensive adaptation regardless of domain stability. To address these limitations, PACE leverages the Covariance Matrix Adaptation Evolution Strategy with the Fastfood projection to optimize high-dimensional affine parameters within a low-dimensional subspace, leading to superior adaptive performance. Furthermore, we enhance the runtime efficiency by incorporating an adaptation stopping criterion and a domain-specialized vector bank to eliminate redundant computation. Our framework achieves state-of-the-art accuracy across multiple benchmarks under continual distribution shifts, reducing runtime by over 50% compared to existing backpropagation-free methods.
Annotation-Efficient Vision-Language Model Adaptation to the Polish Language Using the LLaVA Framework
Feb 17, 2026Most vision-language models (VLMs) are trained on English-centric data, limiting their performance in other languages and cultural contexts. This restricts their usability for non-English-speaking users and hinders the development of multimodal systems that reflect diverse linguistic and cultural realities. In this work, we reproduce and adapt the LLaVA-Next methodology to create a set of Polish VLMs. We rely on a fully automated pipeline for translating and filtering existing multimodal datasets, and complement this with synthetic Polish data for OCR and culturally specific tasks. Despite relying almost entirely on automatic translation and minimal manual intervention to the training data, our approach yields strong results: we observe a +9.5% improvement over LLaVA-1.6-Vicuna-13B on a Polish-adapted MMBench, along with higher-quality captions in generative evaluations, as measured by human annotators in terms of linguistic correctness. These findings highlight that large-scale automated translation, combined with lightweight filtering, can effectively bootstrap high-quality multimodal models for low-resource languages. Some challenges remain, particularly in cultural coverage and evaluation. To facilitate further research, we make our models and evaluation dataset publicly available.
Efficient Multi-Source Knowledge Transfer by Model Merging
Aug 26, 2025While transfer learning is an advantageous strategy, it overlooks the opportunity to leverage knowledge from numerous available models online. Addressing this multi-source transfer learning problem is a promising path to boost adaptability and cut re-training costs. However, existing approaches are inherently coarse-grained, lacking the necessary precision for granular knowledge extraction and the aggregation efficiency required to fuse knowledge from either a large number of source models or those with high parameter counts. We address these limitations by leveraging Singular Value Decomposition (SVD) to first decompose each source model into its elementary, rank-one components. A subsequent aggregation stage then selects only the most salient components from all sources, thereby overcoming the previous efficiency and precision limitations. To best preserve and leverage the synthesized knowledge base, our method adapts to the target task by fine-tuning only the principal singular values of the merged matrix. In essence, this process only recalibrates the importance of top SVD components. The proposed framework allows for efficient transfer learning, is robust to perturbations both at the input level and in the parameter space (e.g., noisy or pruned sources), and scales well computationally.
No Task Left Behind: Isotropic Model Merging with Common and Task-Specific Subspaces
Feb 07, 2025Model merging integrates the weights of multiple task-specific models into a single multi-task model. Despite recent interest in the problem, a significant performance gap between the combined and single-task models remains. In this paper, we investigate the key characteristics of task matrices -- weight update matrices applied to a pre-trained model -- that enable effective merging. We show that alignment between singular components of task-specific and merged matrices strongly correlates with performance improvement over the pre-trained model. Based on this, we propose an isotropic merging framework that flattens the singular value spectrum of task matrices, enhances alignment, and reduces the performance gap. Additionally, we incorporate both common and task-specific subspaces to further improve alignment and performance. Our proposed approach achieves state-of-the-art performance across multiple scenarios, including various sets of tasks and model scales. This work advances the understanding of model merging dynamics, offering an effective methodology to merge models without requiring additional training. Code is available at https://github.com/danielm1405/iso-merging .
Task-recency bias strikes back: Adapting covariances in Exemplar-Free Class Incremental Learning
Sep 26, 2024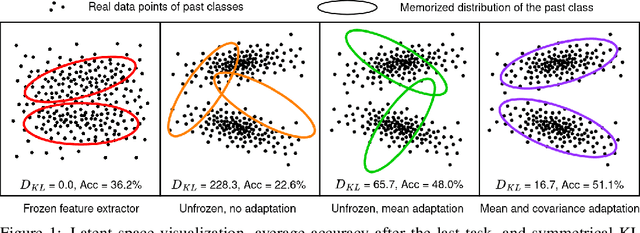
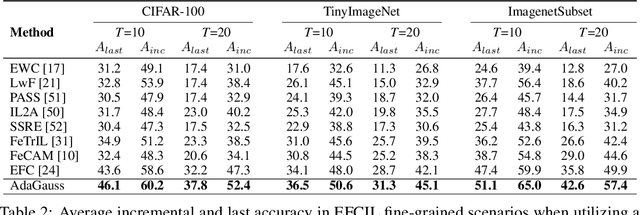
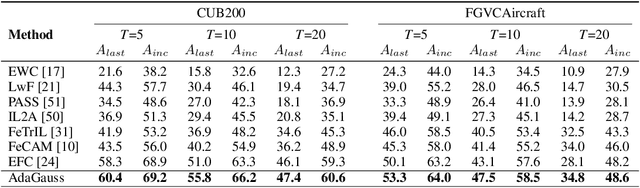

Exemplar-Free Class Incremental Learning (EFCIL) tackles the problem of training a model on a sequence of tasks without access to past data. Existing state-of-the-art methods represent classes as Gaussian distributions in the feature extractor's latent space, enabling Bayes classification or training the classifier by replaying pseudo features. However, we identify two critical issues that compromise their efficacy when the feature extractor is updated on incremental tasks. First, they do not consider that classes' covariance matrices change and must be adapted after each task. Second, they are susceptible to a task-recency bias caused by dimensionality collapse occurring during training. In this work, we propose AdaGauss -- a novel method that adapts covariance matrices from task to task and mitigates the task-recency bias owing to the additional anti-collapse loss function. AdaGauss yields state-of-the-art results on popular EFCIL benchmarks and datasets when training from scratch or starting from a pre-trained backbone. The code is available at: https://github.com/grypesc/AdaGauss.
Realistic Evaluation of Test-Time Adaptation Algorithms: Unsupervised Hyperparameter Selection
Jul 19, 2024



Test-Time Adaptation (TTA) has recently emerged as a promising strategy for tackling the problem of machine learning model robustness under distribution shifts by adapting the model during inference without access to any labels. Because of task difficulty, hyperparameters strongly influence the effectiveness of adaptation. However, the literature has provided little exploration into optimal hyperparameter selection. In this work, we tackle this problem by evaluating existing TTA methods using surrogate-based hp-selection strategies (which do not assume access to the test labels) to obtain a more realistic evaluation of their performance. We show that some of the recent state-of-the-art methods exhibit inferior performance compared to the previous algorithms when using our more realistic evaluation setup. Further, we show that forgetting is still a problem in TTA as the only method that is robust to hp-selection resets the model to the initial state at every step. We analyze different types of unsupervised selection strategies, and while they work reasonably well in most scenarios, the only strategies that work consistently well use some kind of supervision (either by a limited number of annotated test samples or by using pretraining data). Our findings underscore the need for further research with more rigorous benchmarking by explicitly stating model selection strategies, to facilitate which we open-source our code.
MagMax: Leveraging Model Merging for Seamless Continual Learning
Jul 08, 2024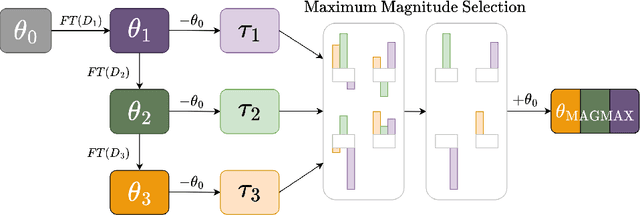
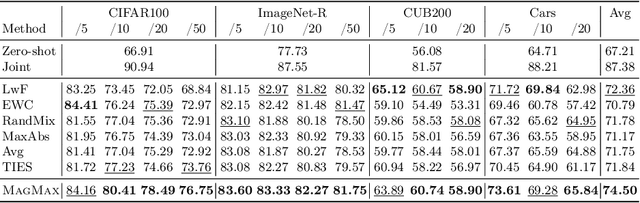
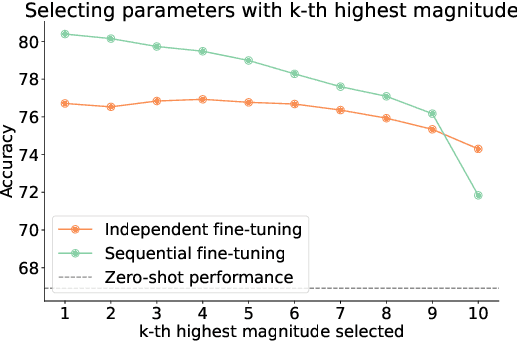
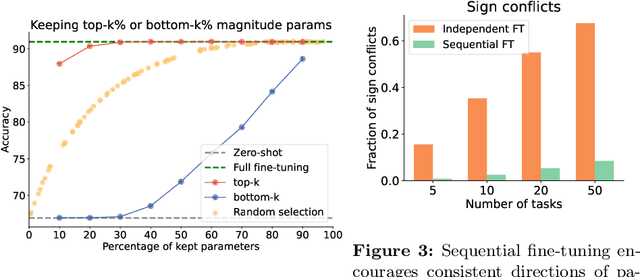
This paper introduces a continual learning approach named MagMax, which utilizes model merging to enable large pre-trained models to continuously learn from new data without forgetting previously acquired knowledge. Distinct from traditional continual learning methods that aim to reduce forgetting during task training, MagMax combines sequential fine-tuning with a maximum magnitude weight selection for effective knowledge integration across tasks. Our initial contribution is an extensive examination of model merging techniques, revealing that simple approaches like weight averaging and random weight selection surprisingly hold up well in various continual learning contexts. More importantly, we present MagMax, a novel model-merging strategy that enables continual learning of large pre-trained models for successive tasks. Our thorough evaluation demonstrates the superiority of MagMax in various scenarios, including class- and domain-incremental learning settings.