 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating New Voices using Normalizing Flows
Dec 22, 2023



Creating realistic and natural-sounding synthetic speech remains a big challenge for voice identities unseen during training. As there is growing interest in synthesizing voices of new speakers, here we investigate the ability of normalizing flows in text-to-speech (TTS) and voice conversion (VC) modes to extrapolate from speakers observed during training to create unseen speaker identities. Firstly, we create an approach for TTS and VC, and then we comprehensively evaluate our methods and baselines in terms of intelligibility, naturalness, speaker similarity, and ability to create new voices. We use both objective and subjective metrics to benchmark our techniques on 2 evaluation tasks: zero-shot and new voice speech synthesis. The goal of the former task is to measure the precision of the conversion to an unseen voice. The goal of the latter is to measure the ability to create new voices. Extensive evaluations demonstrate that the proposed approach systematically allows to obtain state-of-the-art performance in zero-shot speech synthesis and creates various new voices, unobserved in the training set. We consider this work to be the first attempt to synthesize new voices based on mel-spectrograms and normalizing flows, along with a comprehensive analysis and comparison of the TTS and VC modes.
* Interspeech 2022
Cross-lingual Knowledge Distillation via Flow-based Voice Conversion for Robust Polyglot Text-To-Speech
Sep 15, 2023In this work, we introduce a framework for cross-lingual speech synthesis, which involves an upstream Voice Conversion (VC) model and a downstream Text-To-Speech (TTS) model. The proposed framework consists of 4 stages. In the first two stages, we use a VC model to convert utterances in the target locale to the voice of the target speaker. In the third stage, the converted data is combined with the linguistic features and durations from recordings in the target language, which are then used to train a single-speaker acoustic model. Finally, the last stage entails the training of a locale-independent vocoder. Our evaluations show that the proposed paradigm outperforms state-of-the-art approaches which are based on training a large multilingual TTS model. In addition, our experiments demonstrate the robustness of our approach with different model architectures, languages, speakers and amounts of data. Moreover, our solution is especially beneficial in low-resource settings.
Comparing normalizing flows and diffusion models for prosody and acoustic modelling in text-to-speech
Jul 31, 2023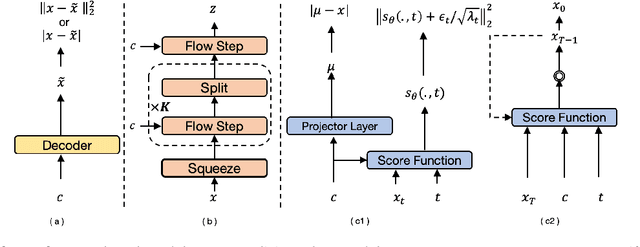
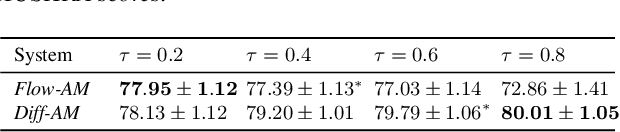
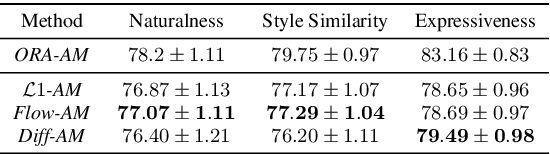
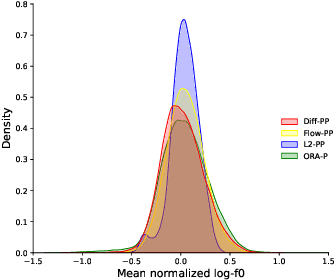
Neural text-to-speech systems are often optimized on L1/L2 losses, which make strong assumptions about the distributions of the target data space. Aiming to improve those assumptions, Normalizing Flows and Diffusion Probabilistic Models were recently proposed as alternatives. In this paper, we compare traditional L1/L2-based approaches to diffusion and flow-based approaches for the tasks of prosody and mel-spectrogram prediction for text-to-speech synthesis. We use a prosody model to generate log-f0 and duration features, which are used to condition an acoustic model that generates mel-spectrograms. Experimental results demonstrate that the flow-based model achieves the best performance for spectrogram prediction, improving over equivalent diffusion and L1 models. Meanwhile, both diffusion and flow-based prosody predictors result in significant improvements over a typical L2-trained prosody models.
Modelling low-resource accents without accent-specific TTS frontend
Jan 11, 2023This work focuses on modelling a speaker's accent that does not have a dedicated text-to-speech (TTS) frontend, including a grapheme-to-phoneme (G2P) module. Prior work on modelling accents assumes a phonetic transcription is available for the target accent, which might not be the case for low-resource, regional accents. In our work, we propose an approach whereby we first augment the target accent data to sound like the donor voice via voice conversion, then train a multi-speaker multi-accent TTS model on the combination of recordings and synthetic data, to generate the donor's voice speaking in the target accent. Throughout the procedure, we use a TTS frontend developed for the same language but a different accent. We show qualitative and quantitative analysis where the proposed strategy achieves state-of-the-art results compared to other generative models. Our work demonstrates that low resource accents can be modelled with relatively little data and without developing an accent-specific TTS frontend. Audio samples of our model converting to multiple accents are available on our web page.
Remap, warp and attend: Non-parallel many-to-many accent conversion with Normalizing Flows
Nov 10, 2022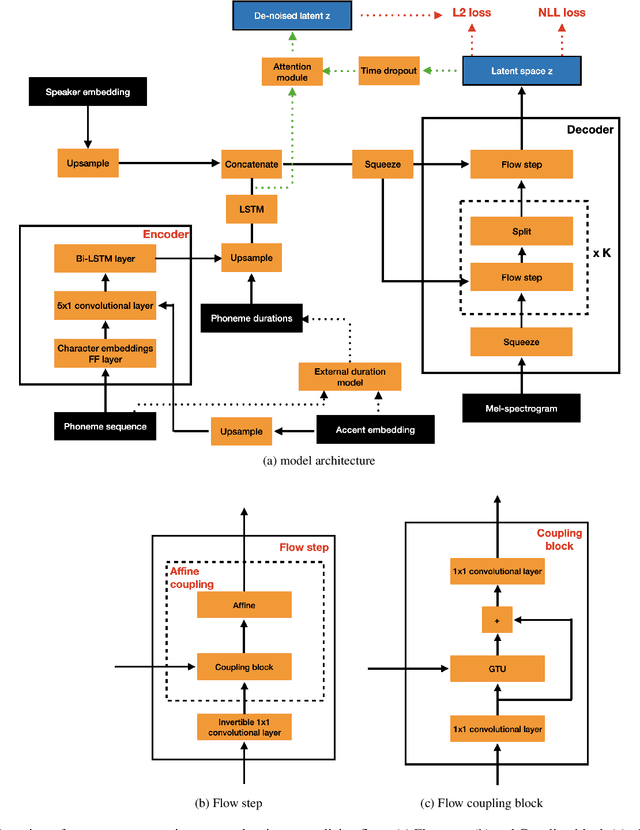

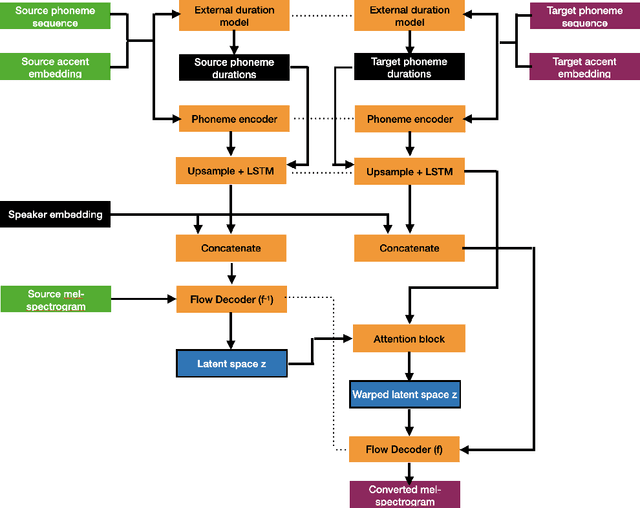

Regional accents of the same language affect not only how words are pronounced (i.e., phonetic content), but also impact prosodic aspects of speech such as speaking rate and intonation. This paper investigates a novel flow-based approach to accent conversion using normalizing flows. The proposed approach revolves around three steps: remapping the phonetic conditioning, to better match the target accent, warping the duration of the converted speech, to better suit the target phonemes, and an attention mechanism that implicitly aligns source and target speech sequences. The proposed remap-warp-attend system enables adaptation of both phonetic and prosodic aspects of speech while allowing for source and converted speech signals to be of different lengths. Objective and subjective evaluations show that the proposed approach significantly outperforms a competitive CopyCat baseline model in terms of similarity to the target accent, naturalness and intelligibility.
Unify and Conquer: How Phonetic Feature Representation Affects Polyglot Text-To-Speech (TTS)
Jul 04, 2022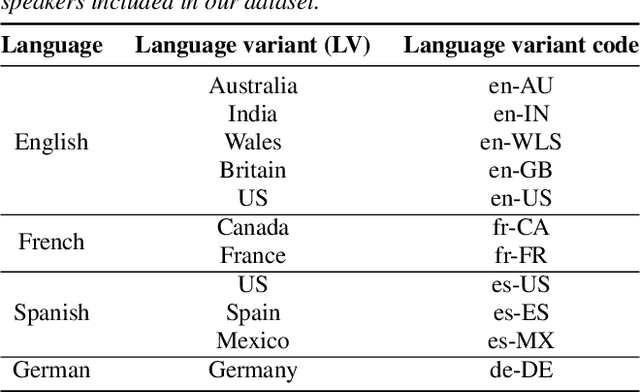
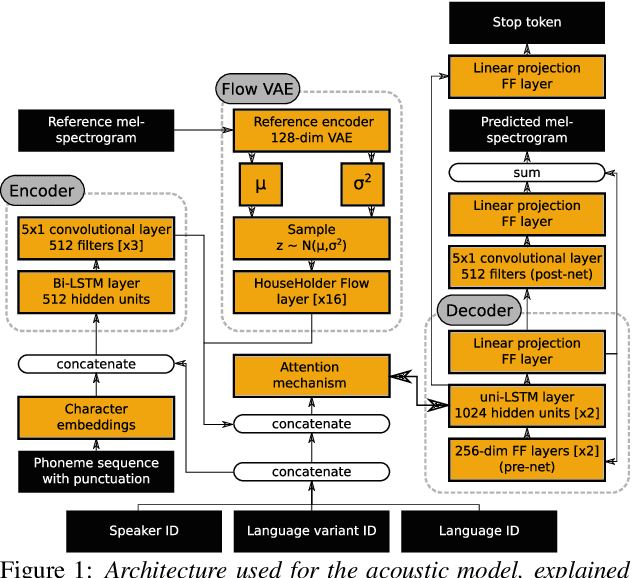
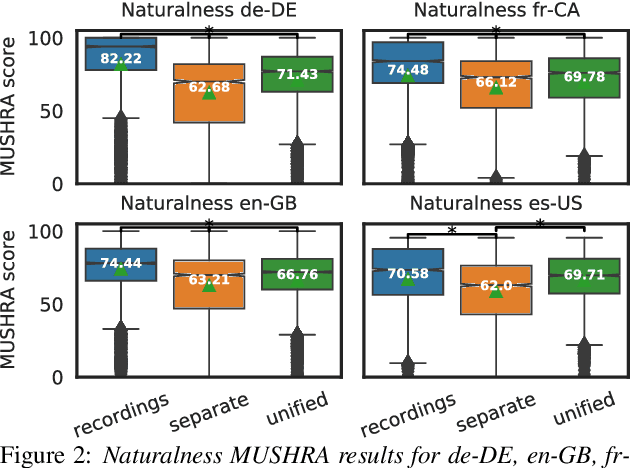
An essential design decision for multilingual Neural Text-To-Speech (NTTS) systems is how to represent input linguistic features within the model. Looking at the wide variety of approaches in the literature, two main paradigms emerge, unified and separate representations. The former uses a shared set of phonetic tokens across languages, whereas the latter uses unique phonetic tokens for each language. In this paper, we conduct a comprehensive study comparing multilingual NTTS systems models trained with both representations. Our results reveal that the unified approach consistently achieves better cross-lingual synthesis with respect to both naturalness and accent. Separate representations tend to have an order of magnitude more tokens than unified ones, which may affect model capacity. For this reason, we carry out an ablation study to understand the interaction of the representation type with the size of the token embedding. We find that the difference between the two paradigms only emerges above a certain threshold embedding size. This study provides strong evidence that unified representations should be the preferred paradigm when building multilingual NTTS systems.
Mix and Match: An Empirical Study on Training Corpus Composition for Polyglot Text-To-Speech
Jul 04, 2022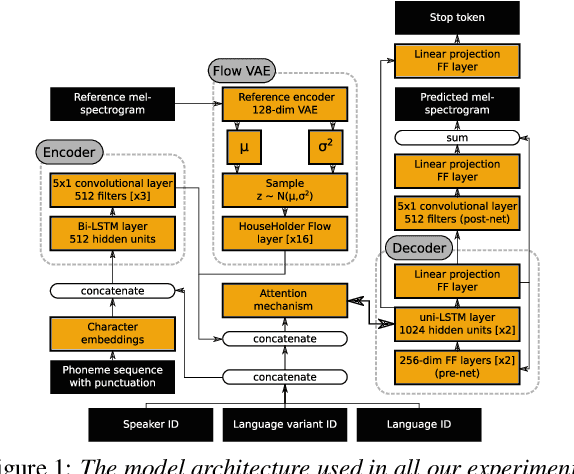
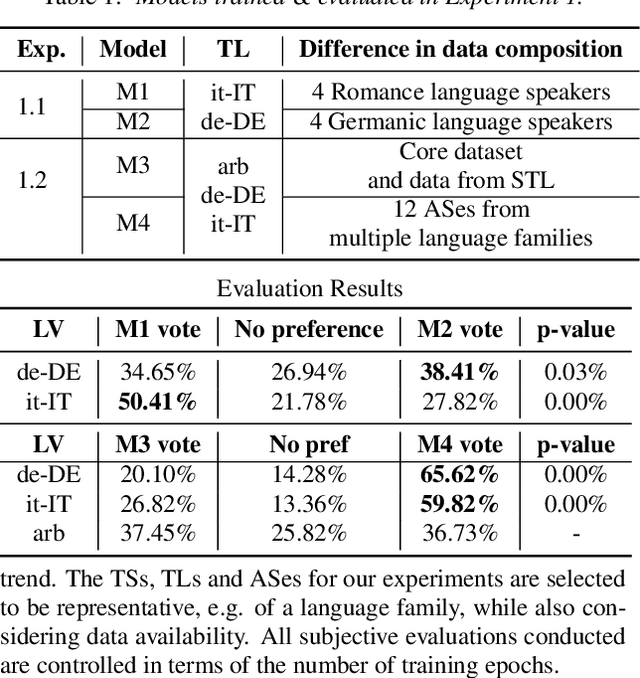
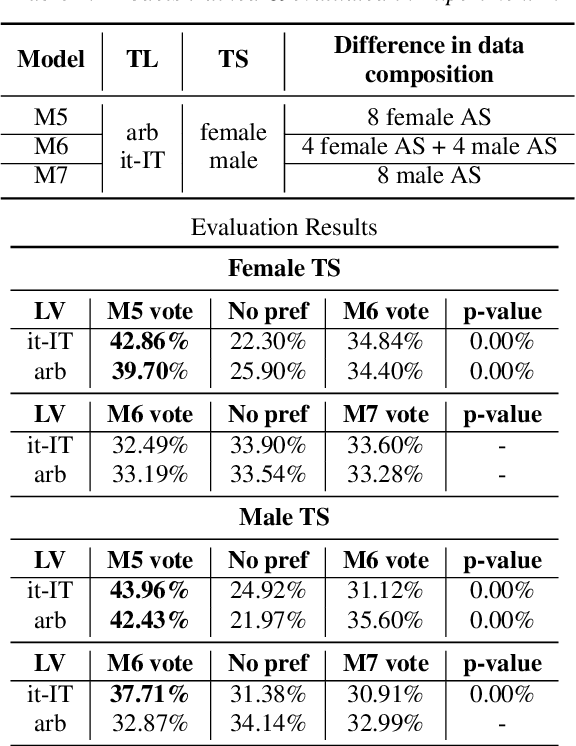
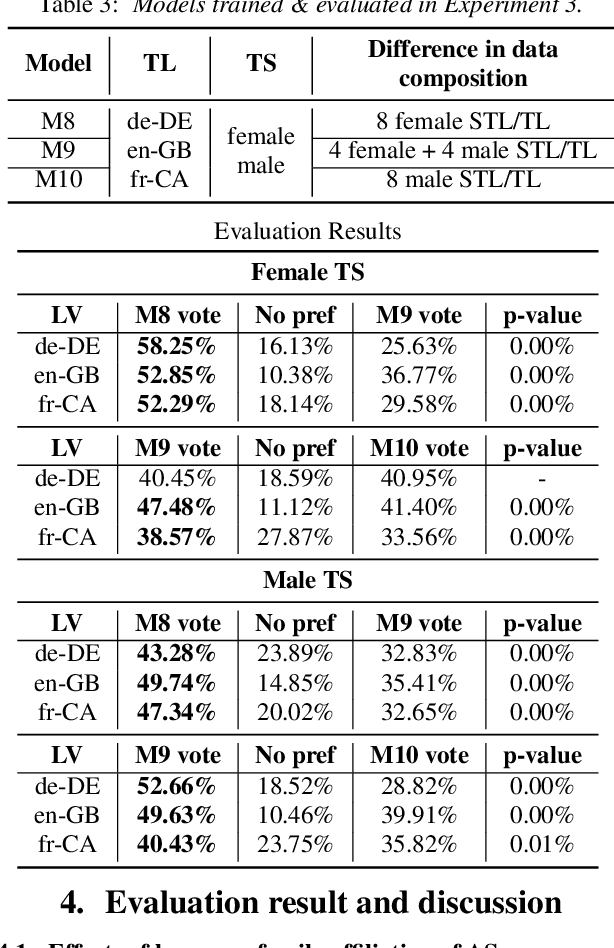
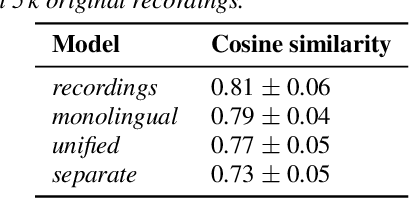
Training multilingual Neural Text-To-Speech (NTTS) models using only monolingual corpora has emerged as a popular way for building voice cloning based Polyglot NTTS systems. In order to train these models, it is essential to understand how the composition of the training corpora affects the quality of multilingual speech synthesis. In this context, it is common to hear questions such as "Would including more Spanish data help my Italian synthesis, given the closeness of both languages?". Unfortunately, we found existing literature on the topic lacking in completeness in this regard. In the present work, we conduct an extensive ablation study aimed at understanding how various factors of the training corpora, such as language family affiliation, gender composition, and the number of speakers, contribute to the quality of Polyglot synthesis. Our findings include the observation that female speaker data are preferred in most scenarios, and that it is not always beneficial to have more speakers from the target language variant in the training corpus. The findings herein are informative for the process of data procurement and corpora building.
Singing Synthesis: with a little help from my attention
Dec 12, 2019


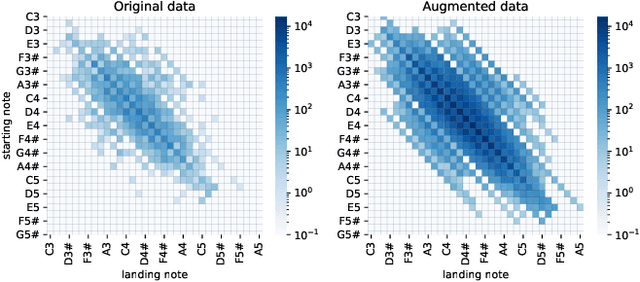
We present a novel system for singing synthesis, based on attention. Starting from a musical score with notes and lyrics, we build a phoneme-level multi stream note embedding. The embedding contains the information encoded in the score regarding pitch, duration and the phonemes to be pronounced on each note. This note representation is used to condition an attention-based sequence-to-sequence architecture, in order to generate mel-spectrograms. Our model demonstrates attention can be successfully applied to the singing synthesis field. The system requires considerably less explicit modelling of voice features such as F0 patterns, vibratos, and note and phoneme durations, than most models in the literature. However, we observe that completely dispensing with any duration modelling introduces occasional instabilities in the generated spectrograms. We train an autoregressive WaveNet to be used as a neural vocoder to synthesise the mel-spectrograms produced by the sequence-to-sequence architecture, using a combination of speech and singing data.