 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight End-to-end Text-to-speech Synthesis for low resource on-device applications
May 12, 2025



Recent works have shown that modelling raw waveform directly from text in an end-to-end (E2E) fashion produces more natural-sounding speech than traditional neural text-to-speech (TTS) systems based on a cascade or two-stage approach. However, current E2E state-of-the-art models are computationally complex and memory-consuming, making them unsuitable for real-time offline on-device applications in low-resource scenarios. To address this issue, we propose a Lightweight E2E-TTS (LE2E) model that generates high-quality speech requiring minimal computational resources. We evaluate the proposed model on the LJSpeech dataset and show that it achieves state-of-the-art performance while being up to $90\%$ smaller in terms of model parameters and $10\times$ faster in real-time-factor. Furthermore, we demonstrate that the proposed E2E training paradigm achieves better quality compared to an equivalent architecture trained in a two-stage approach. Our results suggest that LE2E is a promising approach for developing real-time, high quality, low-resource TTS applications for on-device applications.
* Published as a conference paper at SSW 2023
Modelling low-resource accents without accent-specific TTS frontend
Jan 11, 2023



This work focuses on modelling a speaker's accent that does not have a dedicated text-to-speech (TTS) frontend, including a grapheme-to-phoneme (G2P) module. Prior work on modelling accents assumes a phonetic transcription is available for the target accent, which might not be the case for low-resource, regional accents. In our work, we propose an approach whereby we first augment the target accent data to sound like the donor voice via voice conversion, then train a multi-speaker multi-accent TTS model on the combination of recordings and synthetic data, to generate the donor's voice speaking in the target accent. Throughout the procedure, we use a TTS frontend developed for the same language but a different accent. We show qualitative and quantitative analysis where the proposed strategy achieves state-of-the-art results compared to other generative models. Our work demonstrates that low resource accents can be modelled with relatively little data and without developing an accent-specific TTS frontend. Audio samples of our model converting to multiple accents are available on our web page.
Voice Conversion for Whispered Speech Synthesis
Jan 17, 2020



We present an approach to synthesize whisper by applying a handcrafted signal processing recipe and Voice Conversion (VC) techniques to convert normally phonated speech to whispered speech. We investigate using Gaussian Mixture Models (GMM) and Deep Neural Networks (DNN) to model the mapping between acoustic features of normal speech and those of whispered speech. We evaluate naturalness and speaker similarity of the converted whisper on an internal corpus and on the publicly available wTIMIT corpus. We show that applying VC techniques is significantly better than using rule-based signal processing methods and it achieves results that are indistinguishable from copy-synthesis of natural whisper recordings. We investigate the ability of the DNN model to generalize on unseen speakers, when trained with data from multiple speakers. We show that excluding the target speaker from the training set has little or no impact on the perceived naturalness and speaker similarity of the converted whisper. The proposed DNN method is used in the newly released Whisper Mode of Amazon Alexa.
Using VAEs and Normalizing Flows for One-shot Text-To-Speech Synthesis of Expressive Speech
Nov 28, 2019
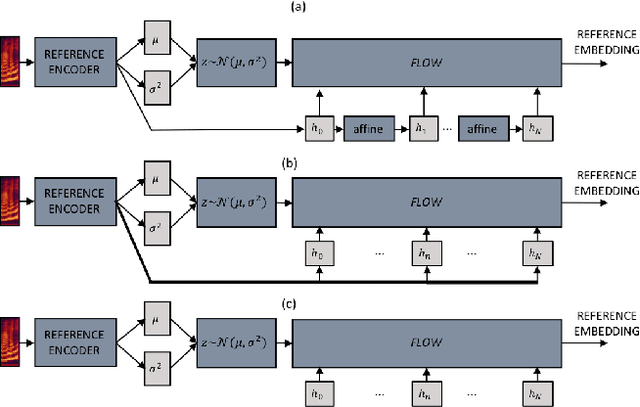


We propose a Text-to-Speech method to create an unseen expressive style using one utterance of expressive speech of around one second. Specifically, we enhance the disentanglement capabilities of a state-of-the-art sequence-to-sequence based system with a Variational AutoEncoder (VAE) and a Householder Flow. The proposed system provides a 22% KL-divergence reduction while jointly improving perceptual metrics over state-of-the-art. At synthesis time we use one example of expressive style as a reference input to the encoder for generating any text in the desired style. Perceptual MUSHRA evaluations show that we can create a voice with a 9% relative naturalness improvement over standard Neural Text-to-Speech, while also improving the perceived emotional intensity (59 compared to the 55 of neutral speech).