 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating self-supervised features for expressive, multilingual voice conversion
May 13, 2025



Voice conversion (VC) systems are widely used for several applications, from speaker anonymisation to personalised speech synthesis. Supervised approaches learn a mapping between different speakers using parallel data, which is expensive to produce. Unsupervised approaches are typically trained to reconstruct the input signal, which is composed of the content and the speaker information. Disentangling these components is a challenge and often leads to speaker leakage or prosodic information removal. In this paper, we explore voice conversion by leveraging the potential of self-supervised learning (SSL). A combination of the latent representations of SSL models, concatenated with speaker embeddings, is fed to a vocoder which is trained to reconstruct the input. Zero-shot voice conversion results show that this approach allows to keep the prosody and content of the source speaker while matching the speaker similarity of a VC system based on phonetic posteriorgrams (PPGs).
* Published as a conference paper at ICASSP 2024
Lightweight End-to-end Text-to-speech Synthesis for low resource on-device applications
May 12, 2025



Recent works have shown that modelling raw waveform directly from text in an end-to-end (E2E) fashion produces more natural-sounding speech than traditional neural text-to-speech (TTS) systems based on a cascade or two-stage approach. However, current E2E state-of-the-art models are computationally complex and memory-consuming, making them unsuitable for real-time offline on-device applications in low-resource scenarios. To address this issue, we propose a Lightweight E2E-TTS (LE2E) model that generates high-quality speech requiring minimal computational resources. We evaluate the proposed model on the LJSpeech dataset and show that it achieves state-of-the-art performance while being up to $90\%$ smaller in terms of model parameters and $10\times$ faster in real-time-factor. Furthermore, we demonstrate that the proposed E2E training paradigm achieves better quality compared to an equivalent architecture trained in a two-stage approach. Our results suggest that LE2E is a promising approach for developing real-time, high quality, low-resource TTS applications for on-device applications.
* Published as a conference paper at SSW 2023
Enhancing the Stability of LLM-based Speech Generation Systems through Self-Supervised Representations
Feb 05, 2024


Large Language Models (LLMs) are one of the most promising technologies for the next era of speech generation systems, due to their scalability and in-context learning capabilities. Nevertheless, they suffer from multiple stability issues at inference time, such as hallucinations, content skipping or speech repetitions. In this work, we introduce a new self-supervised Voice Conversion (VC) architecture which can be used to learn to encode transitory features, such as content, separately from stationary ones, such as speaker ID or recording conditions, creating speaker-disentangled representations. Using speaker-disentangled codes to train LLMs for text-to-speech (TTS) allows the LLM to generate the content and the style of the speech only from the text, similarly to humans, while the speaker identity is provided by the decoder of the VC model. Results show that LLMs trained over speaker-disentangled self-supervised representations provide an improvement of 4.7pp in speaker similarity over SOTA entangled representations, and a word error rate (WER) 5.4pp lower. Furthermore, they achieve higher naturalness than human recordings of the LibriTTS test-other dataset. Finally, we show that using explicit reference embedding negatively impacts intelligibility (stability), with WER increasing by 14pp compared to the model that only uses text to infer the style.
Multilingual context-based pronunciation learning for Text-to-Speech
Jul 31, 2023Phonetic information and linguistic knowledge are an essential component of a Text-to-speech (TTS) front-end. Given a language, a lexicon can be collected offline and Grapheme-to-Phoneme (G2P) relationships are usually modeled in order to predict the pronunciation for out-of-vocabulary (OOV) words. Additionally, post-lexical phonology, often defined in the form of rule-based systems, is used to correct pronunciation within or between words. In this work we showcase a multilingual unified front-end system that addresses any pronunciation related task, typically handled by separate modules. We evaluate the proposed model on G2P conversion and other language-specific challenges, such as homograph and polyphones disambiguation, post-lexical rules and implicit diacritization. We find that the multilingual model is competitive across languages and tasks, however, some trade-offs exists when compared to equivalent monolingual solutions.
Comparing normalizing flows and diffusion models for prosody and acoustic modelling in text-to-speech
Jul 31, 2023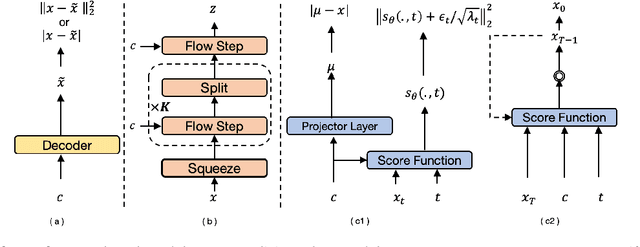
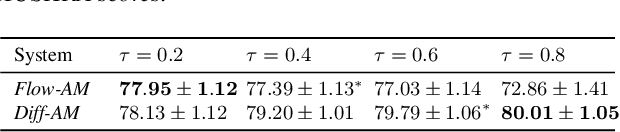
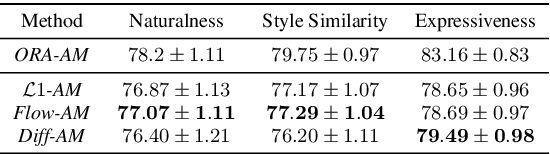
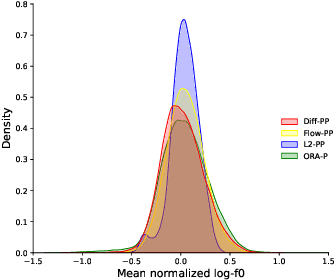
Neural text-to-speech systems are often optimized on L1/L2 losses, which make strong assumptions about the distributions of the target data space. Aiming to improve those assumptions, Normalizing Flows and Diffusion Probabilistic Models were recently proposed as alternatives. In this paper, we compare traditional L1/L2-based approaches to diffusion and flow-based approaches for the tasks of prosody and mel-spectrogram prediction for text-to-speech synthesis. We use a prosody model to generate log-f0 and duration features, which are used to condition an acoustic model that generates mel-spectrograms. Experimental results demonstrate that the flow-based model achieves the best performance for spectrogram prediction, improving over equivalent diffusion and L1 models. Meanwhile, both diffusion and flow-based prosody predictors result in significant improvements over a typical L2-trained prosody models.
Improving grapheme-to-phoneme conversion by learning pronunciations from speech recordings
Jul 31, 2023The Grapheme-to-Phoneme (G2P) task aims to convert orthographic input into a discrete phonetic representation. G2P conversion is beneficial to various speech processing applications, such as text-to-speech and speech recognition. However, these tend to rely on manually-annotated pronunciation dictionaries, which are often time-consuming and costly to acquire. In this paper, we propose a method to improve the G2P conversion task by learning pronunciation examples from audio recordings. Our approach bootstraps a G2P with a small set of annotated examples. The G2P model is used to train a multilingual phone recognition system, which then decodes speech recordings with a phonetic representation. Given hypothesized phoneme labels, we learn pronunciation dictionaries for out-of-vocabulary words, and we use those to re-train the G2P system. Results indicate that our approach consistently improves the phone error rate of G2P systems across languages and amount of available data.
Low-data? No problem: low-resource, language-agnostic conversational text-to-speech via F0-conditioned data augmentation
Jul 29, 2022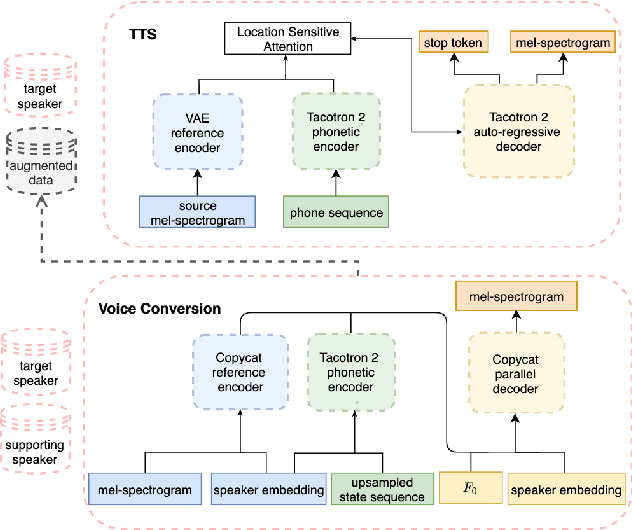

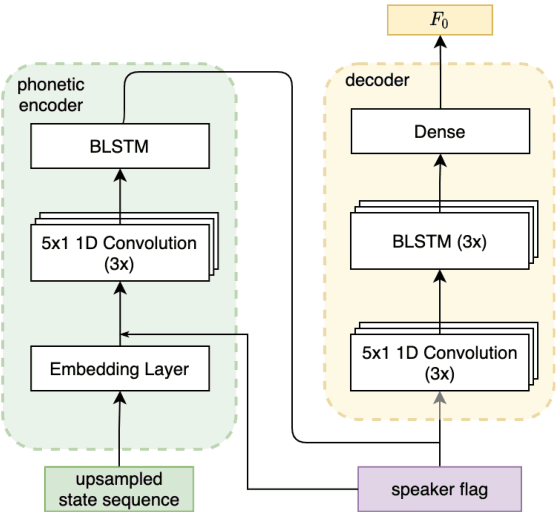
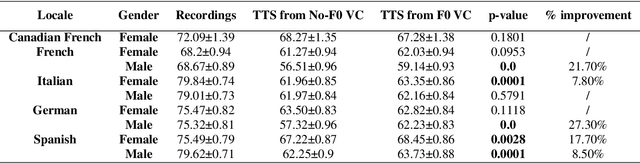
The availability of data in expressive styles across languages is limited, and recording sessions are costly and time consuming. To overcome these issues, we demonstrate how to build low-resource, neural text-to-speech (TTS) voices with only 1 hour of conversational speech, when no other conversational data are available in the same language. Assuming the availability of non-expressive speech data in that language, we propose a 3-step technology: 1) we train an F0-conditioned voice conversion (VC) model as data augmentation technique; 2) we train an F0 predictor to control the conversational flavour of the voice-converted synthetic data; 3) we train a TTS system that consumes the augmented data. We prove that our technology enables F0 controllability, is scalable across speakers and languages and is competitive in terms of naturalness over a state-of-the-art baseline model, another augmented method which does not make use of F0 information.
Computer-assisted Pronunciation Training -- Speech synthesis is almost all you need
Jul 02, 2022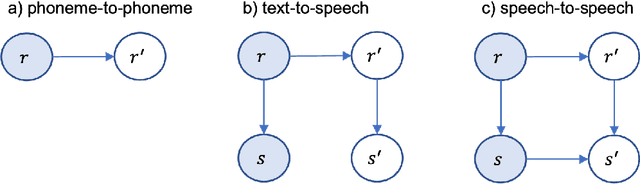
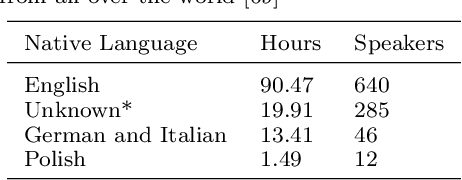

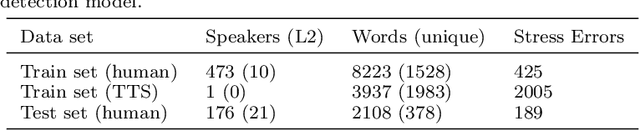
The research community has long studied computer-assisted pronunciation training (CAPT) methods in non-native speech. Researchers focused on studying various model architectures, such as Bayesian networks and deep learning methods, as well as on the analysis of different representations of the speech signal. Despite significant progress in recent years, existing CAPT methods are not able to detect pronunciation errors with high accuracy (only 60\% precision at 40\%-80\% recall). One of the key problems is the low availability of mispronounced speech that is needed for the reliable training of pronunciation error detection models. If we had a generative model that could mimic non-native speech and produce any amount of training data, then the task of detecting pronunciation errors would be much easier. We present three innovative techniques based on phoneme-to-phoneme (P2P), text-to-speech (T2S), and speech-to-speech (S2S) conversion to generate correctly pronounced and mispronounced synthetic speech. We show that these techniques not only improve the accuracy of three machine learning models for detecting pronunciation errors but also help establish a new state-of-the-art in the field. Earlier studies have used simple speech generation techniques such as P2P conversion, but only as an additional mechanism to improve the accuracy of pronunciation error detection. We, on the other hand, consider speech generation to be the first-class method of detecting pronunciation errors. The effectiveness of these techniques is assessed in the tasks of detecting pronunciation and lexical stress errors. Non-native English speech corpora of German, Italian, and Polish speakers are used in the evaluations. The best proposed S2S technique improves the accuracy of detecting pronunciation errors in AUC metric by 41\% from 0.528 to 0.749 compared to the state-of-the-art approach.
Voice Filter: Few-shot text-to-speech speaker adaptation using voice conversion as a post-processing module
Feb 16, 2022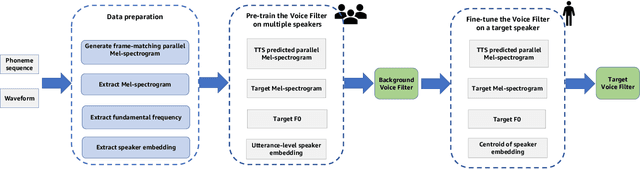

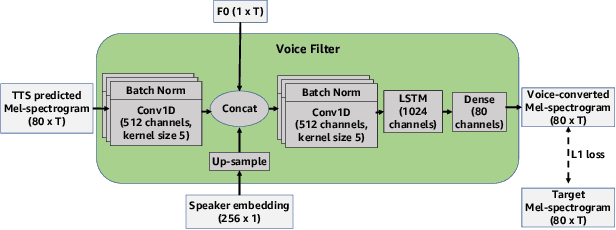

State-of-the-art text-to-speech (TTS) systems require several hours of recorded speech data to generate high-quality synthetic speech. When using reduced amounts of training data, standard TTS models suffer from speech quality and intelligibility degradations, making training low-resource TTS systems problematic. In this paper, we propose a novel extremely low-resource TTS method called Voice Filter that uses as little as one minute of speech from a target speaker. It uses voice conversion (VC) as a post-processing module appended to a pre-existing high-quality TTS system and marks a conceptual shift in the existing TTS paradigm, framing the few-shot TTS problem as a VC task. Furthermore, we propose to use a duration-controllable TTS system to create a parallel speech corpus to facilitate the VC task. Results show that the Voice Filter outperforms state-of-the-art few-shot speech synthesis techniques in terms of objective and subjective metrics on one minute of speech on a diverse set of voices, while being competitive against a TTS model built on 30 times more data.
Cross-speaker style transfer for text-to-speech using data augmentation
Feb 10, 2022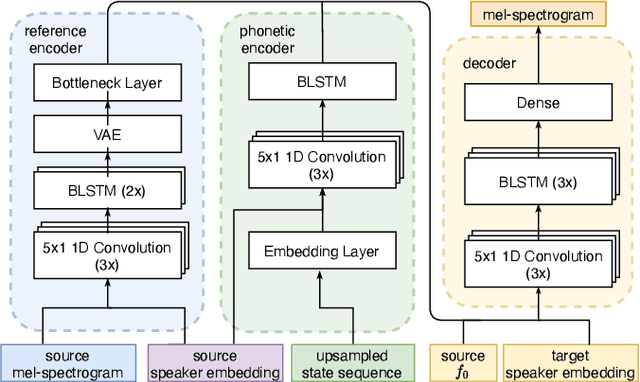
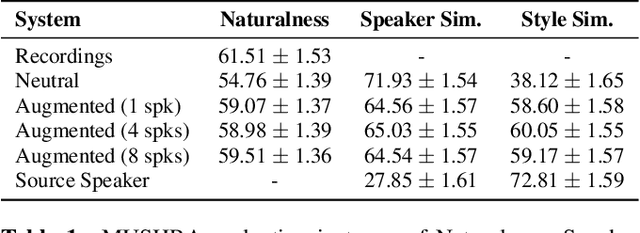
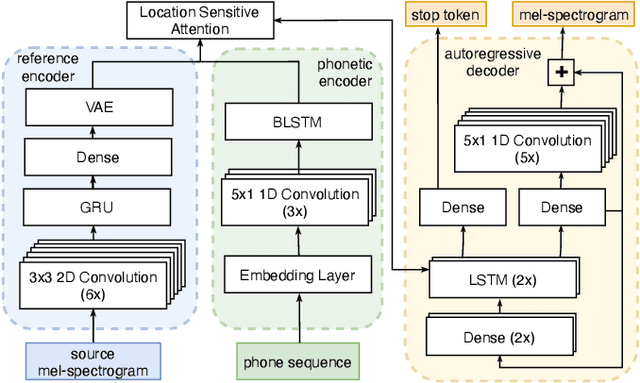
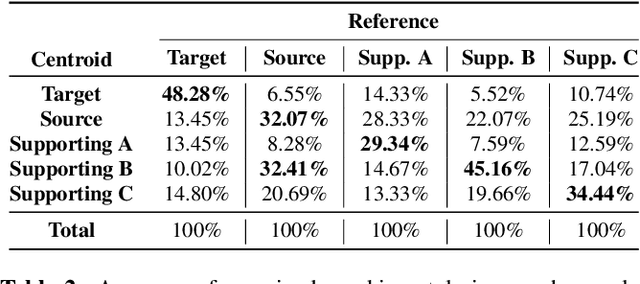
We address the problem of cross-speaker style transfer for text-to-speech (TTS) using data augmentation via voice conversion. We assume to have a corpus of neutral non-expressive data from a target speaker and supporting conversational expressive data from different speakers. Our goal is to build a TTS system that is expressive, while retaining the target speaker's identity. The proposed approach relies on voice conversion to first generate high-quality data from the set of supporting expressive speakers. The voice converted data is then pooled with natural data from the target speaker and used to train a single-speaker multi-style TTS system. We provide evidence that this approach is efficient, flexible, and scalable. The method is evaluated using one or more supporting speakers, as well as a variable amount of supporting data. We further provide evidence that this approach allows some controllability of speaking style, when using multiple supporting speakers. We conclude by scaling our proposed technology to a set of 14 speakers across 7 languages. Results indicate that our technology consistently improves synthetic samples in terms of style similarity, while retaining the target speaker's identity.