 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Filter: Few-shot text-to-speech speaker adaptation using voice conversion as a post-processing module
Paper and Code
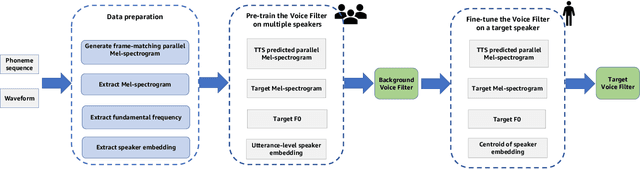

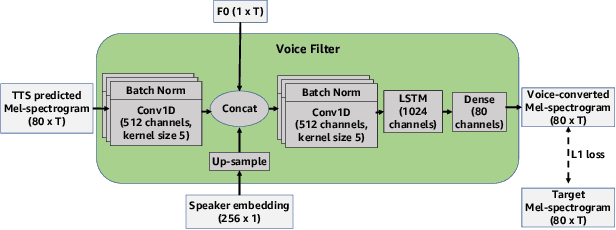

State-of-the-art text-to-speech (TTS) systems require several hours of recorded speech data to generate high-quality synthetic speech. When using reduced amounts of training data, standard TTS models suffer from speech quality and intelligibility degradations, making training low-resource TTS systems problematic. In this paper, we propose a novel extremely low-resource TTS method called Voice Filter that uses as little as one minute of speech from a target speaker. It uses voice conversion (VC) as a post-processing module appended to a pre-existing high-quality TTS system and marks a conceptual shift in the existing TTS paradigm, framing the few-shot TTS problem as a VC task. Furthermore, we propose to use a duration-controllable TTS system to create a parallel speech corpus to facilitate the VC task. Results show that the Voice Filter outperforms state-of-the-art few-shot speech synthesis techniques in terms of objective and subjective metrics on one minute of speech on a diverse set of voices, while being competitive against a TTS model built on 30 times more data.