 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization capabilities of MeshGraphNets to unseen geometries for fluid dynamics
Aug 12, 2024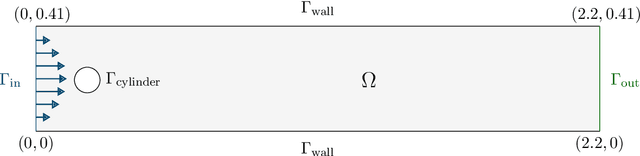

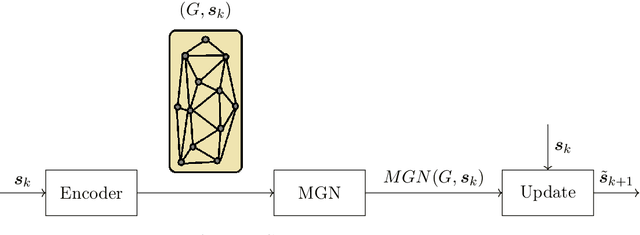

This works investigates the generalization capabilities of MeshGraphNets (MGN) [Pfaff et al. Learning Mesh-Based Simulation with Graph Networks. ICML 2021] to unseen geometries for fluid dynamics, e.g. predicting the flow around a new obstacle that was not part of the training data. For this purpose, we create a new benchmark dataset for data-driven computational fluid dynamics (CFD) which extends DeepMind's flow around a cylinder dataset by including different shapes and multiple objects. We then use this new dataset to extend the generalization experiments conducted by DeepMind on MGNs by testing how well an MGN can generalize to different shapes. In our numerical tests, we show that MGNs can sometimes generalize well to various shapes by training on a dataset of one obstacle shape and testing on a dataset of another obstacle shape.
Voice Filter: Few-shot text-to-speech speaker adaptation using voice conversion as a post-processing module
Feb 16, 2022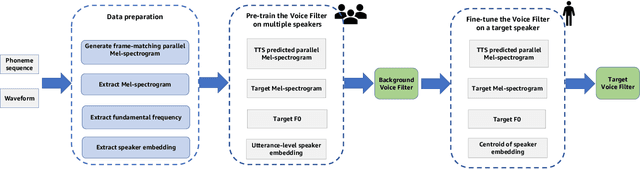

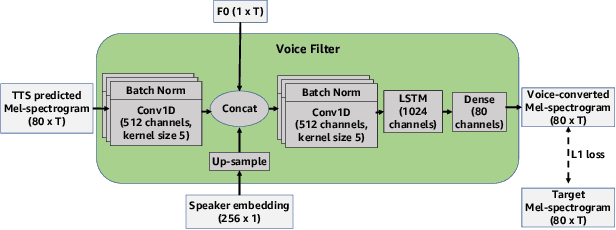

State-of-the-art text-to-speech (TTS) systems require several hours of recorded speech data to generate high-quality synthetic speech. When using reduced amounts of training data, standard TTS models suffer from speech quality and intelligibility degradations, making training low-resource TTS systems problematic. In this paper, we propose a novel extremely low-resource TTS method called Voice Filter that uses as little as one minute of speech from a target speaker. It uses voice conversion (VC) as a post-processing module appended to a pre-existing high-quality TTS system and marks a conceptual shift in the existing TTS paradigm, framing the few-shot TTS problem as a VC task. Furthermore, we propose to use a duration-controllable TTS system to create a parallel speech corpus to facilitate the VC task. Results show that the Voice Filter outperforms state-of-the-art few-shot speech synthesis techniques in terms of objective and subjective metrics on one minute of speech on a diverse set of voices, while being competitive against a TTS model built on 30 times more data.
Cross-speaker style transfer for text-to-speech using data augmentation
Feb 10, 2022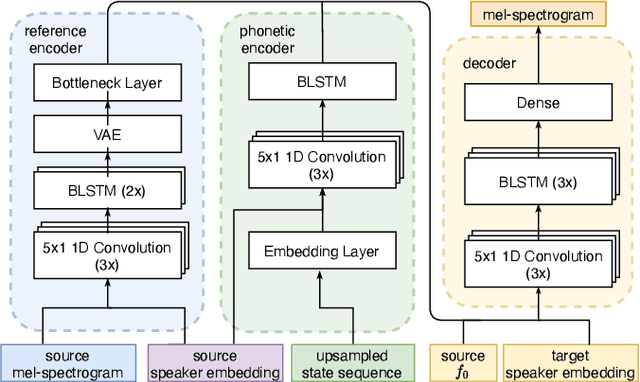
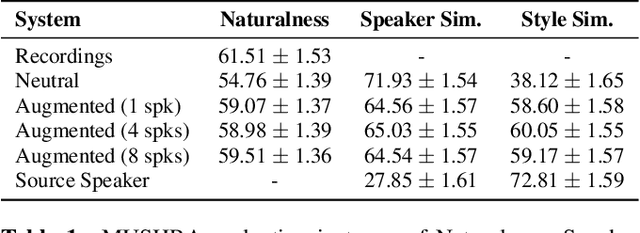
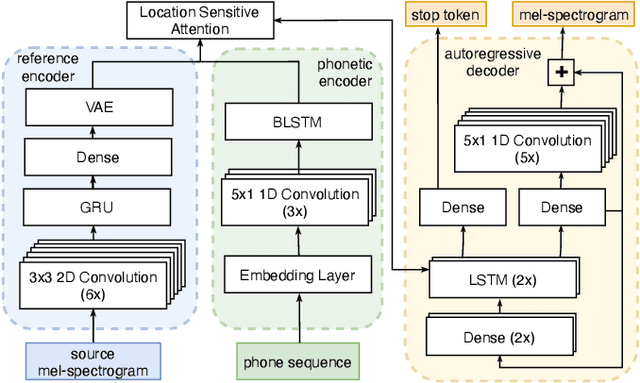
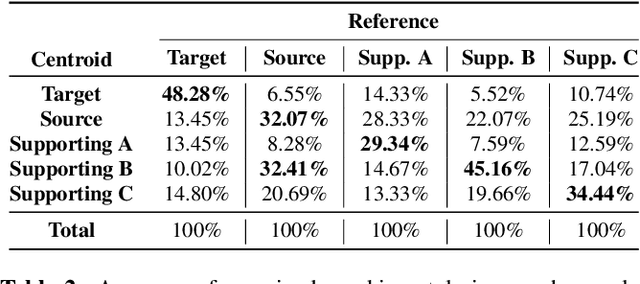
We address the problem of cross-speaker style transfer for text-to-speech (TTS) using data augmentation via voice conversion. We assume to have a corpus of neutral non-expressive data from a target speaker and supporting conversational expressive data from different speakers. Our goal is to build a TTS system that is expressive, while retaining the target speaker's identity. The proposed approach relies on voice conversion to first generate high-quality data from the set of supporting expressive speakers. The voice converted data is then pooled with natural data from the target speaker and used to train a single-speaker multi-style TTS system. We provide evidence that this approach is efficient, flexible, and scalable. The method is evaluated using one or more supporting speakers, as well as a variable amount of supporting data. We further provide evidence that this approach allows some controllability of speaking style, when using multiple supporting speakers. We conclude by scaling our proposed technology to a set of 14 speakers across 7 languages. Results indicate that our technology consistently improves synthetic samples in terms of style similarity, while retaining the target speaker's identity.
Improving multi-speaker TTS prosody variance with a residual encoder and normalizing flows
Jun 10, 2021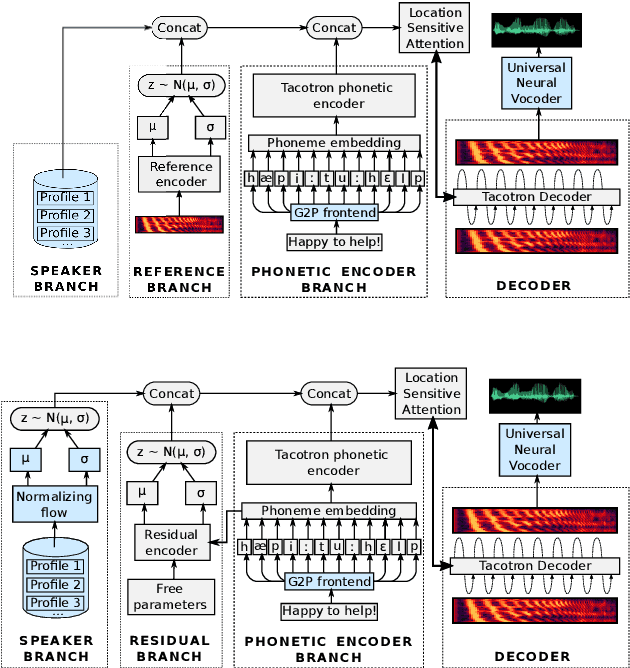

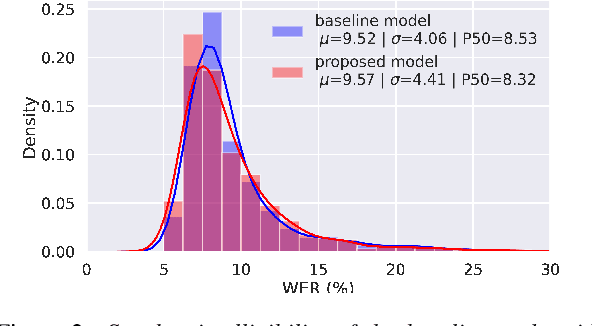

Text-to-speech systems recently achieved almost indistinguishable quality from human speech. However, the prosody of those systems is generally flatter than natural speech, producing samples with low expressiveness. Disentanglement of speaker id and prosody is crucial in text-to-speech systems to improve on naturalness and produce more variable syntheses. This paper proposes a new neural text-to-speech model that approaches the disentanglement problem by conditioning a Tacotron2-like architecture on flow-normalized speaker embeddings, and by substituting the reference encoder with a new learned latent distribution responsible for modeling the intra-sentence variability due to the prosody. By removing the reference encoder dependency, the speaker-leakage problem typically happening in this kind of systems disappears, producing more distinctive syntheses at inference time. The new model achieves significantly higher prosody variance than the baseline in a set of quantitative prosody features, as well as higher speaker distinctiveness, without decreasing the speaker intelligibility. Finally, we observe that the normalized speaker embeddings enable much richer speaker interpolations, substantially improving the distinctiveness of the new interpolated speakers.