 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating self-supervised features for expressive, multilingual voice conversion
May 13, 2025



Voice conversion (VC) systems are widely used for several applications, from speaker anonymisation to personalised speech synthesis. Supervised approaches learn a mapping between different speakers using parallel data, which is expensive to produce. Unsupervised approaches are typically trained to reconstruct the input signal, which is composed of the content and the speaker information. Disentangling these components is a challenge and often leads to speaker leakage or prosodic information removal. In this paper, we explore voice conversion by leveraging the potential of self-supervised learning (SSL). A combination of the latent representations of SSL models, concatenated with speaker embeddings, is fed to a vocoder which is trained to reconstruct the input. Zero-shot voice conversion results show that this approach allows to keep the prosody and content of the source speaker while matching the speaker similarity of a VC system based on phonetic posteriorgrams (PPGs).
* Published as a conference paper at ICASSP 2024
Enhancing the Stability of LLM-based Speech Generation Systems through Self-Supervised Representations
Feb 05, 2024


Large Language Models (LLMs) are one of the most promising technologies for the next era of speech generation systems, due to their scalability and in-context learning capabilities. Nevertheless, they suffer from multiple stability issues at inference time, such as hallucinations, content skipping or speech repetitions. In this work, we introduce a new self-supervised Voice Conversion (VC) architecture which can be used to learn to encode transitory features, such as content, separately from stationary ones, such as speaker ID or recording conditions, creating speaker-disentangled representations. Using speaker-disentangled codes to train LLMs for text-to-speech (TTS) allows the LLM to generate the content and the style of the speech only from the text, similarly to humans, while the speaker identity is provided by the decoder of the VC model. Results show that LLMs trained over speaker-disentangled self-supervised representations provide an improvement of 4.7pp in speaker similarity over SOTA entangled representations, and a word error rate (WER) 5.4pp lower. Furthermore, they achieve higher naturalness than human recordings of the LibriTTS test-other dataset. Finally, we show that using explicit reference embedding negatively impacts intelligibility (stability), with WER increasing by 14pp compared to the model that only uses text to infer the style.
Empirical study of the modulus as activation function in computer vision applications
Jan 15, 2023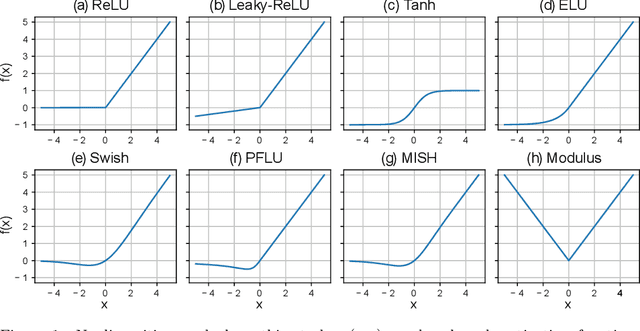



In this work we propose a new non-monotonic activation function: the modulus. The majority of the reported research on nonlinearities is focused on monotonic functions. We empirically demonstrate how by using the modulus activation function on computer vision tasks the models generalize better than with other nonlinearities - up to a 15% accuracy increase in CIFAR100 and 4% in CIFAR10, relative to the best of the benchmark activations tested. With the proposed activation function the vanishing gradient and dying neurons problems disappear, because the derivative of the activation function is always 1 or -1. The simplicity of the proposed function and its derivative make this solution specially suitable for TinyML and hardware applications.
Stutter-TTS: Controlled Synthesis and Improved Recognition of Stuttered Speech
Nov 04, 2022



Stuttering is a speech disorder where the natural flow of speech is interrupted by blocks, repetitions or prolongations of syllables, words and phrases. The majority of existing automatic speech recognition (ASR) interfaces perform poorly on utterances with stutter, mainly due to lack of matched training data. Synthesis of speech with stutter thus presents an opportunity to improve ASR for this type of speech. We describe Stutter-TTS, an end-to-end neural text-to-speech model capable of synthesizing diverse types of stuttering utterances. We develop a simple, yet effective prosody-control strategy whereby additional tokens are introduced into source text during training to represent specific stuttering characteristics. By choosing the position of the stutter tokens, Stutter-TTS allows word-level control of where stuttering occurs in the synthesized utterance. We are able to synthesize stutter events with high accuracy (F1-scores between 0.63 and 0.84, depending on stutter type). By fine-tuning an ASR model on synthetic stuttered speech we are able to reduce word error by 5.7% relative on stuttered utterances, with only minor (<0.2% relative) degradation for fluent utterances.
* 8 pages, 3 figures, 2 tables
Approaching sales forecasting using recurrent neural networks and transformers
Apr 16, 2022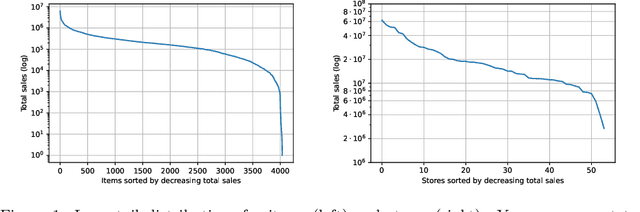
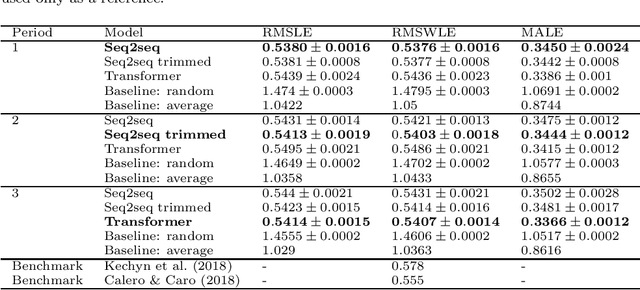
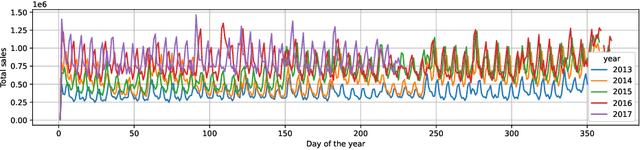
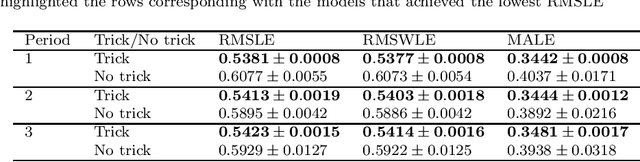
Accurate and fast demand forecast is one of the hot topics in supply chain for enabling the precise execution of the corresponding downstream processes (inbound and outbound planning, inventory placement, network planning, etc). We develop three alternatives to tackle the problem of forecasting the customer sales at day/store/item level using deep learning techniques and the Corporaci\'on Favorita data set, published as part of a Kaggle competition. Our empirical results show how good performance can be achieved by using a simple sequence to sequence architecture with minimal data preprocessing effort. Additionally, we describe a training trick for making the model more time independent and hence improving generalization over time. The proposed solution achieves a RMSLE of around 0.54, which is competitive with other more specific solutions to the problem proposed in the Kaggle competition.
End-to-end Keyword Spotting using Xception-1d
Oct 09, 2021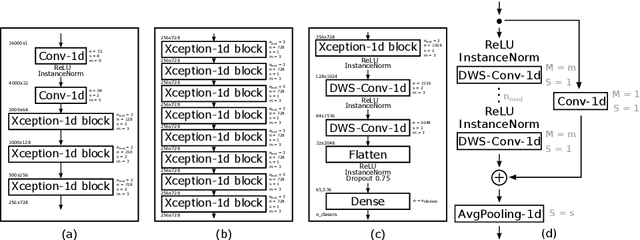
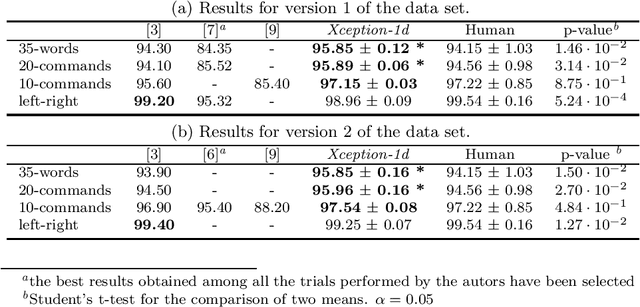
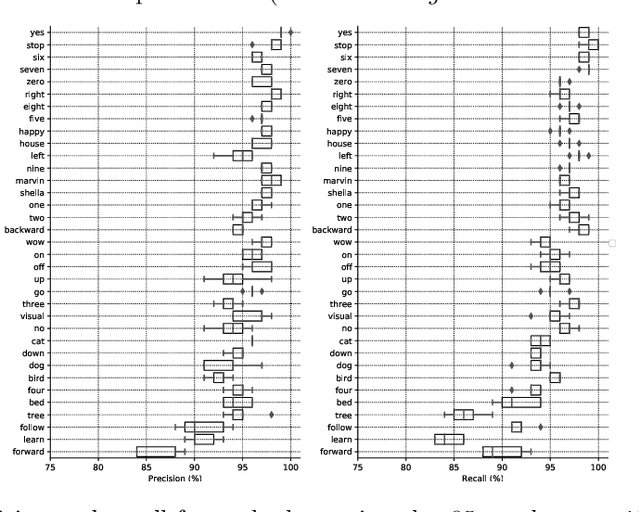
The field of conversational agents is growing fast and there is an increasing need for algorithms that enhance natural interaction. In this work we show how we achieved state of the art results in the Keyword Spotting field by adapting and tweaking the Xception algorithm, which achieved outstanding results in several computer vision tasks. We obtained about 96\% accuracy when classifying audio clips belonging to 35 different categories, beating human annotation at the most complex tasks proposed.
Improving multi-speaker TTS prosody variance with a residual encoder and normalizing flows
Jun 10, 2021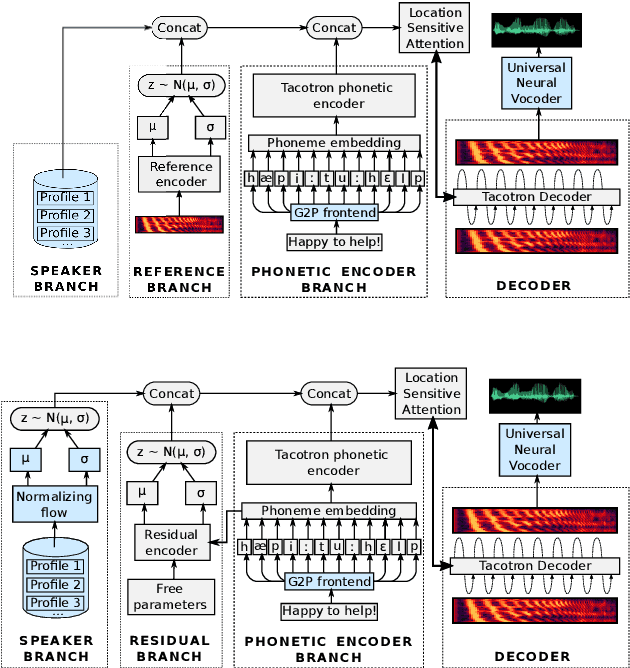

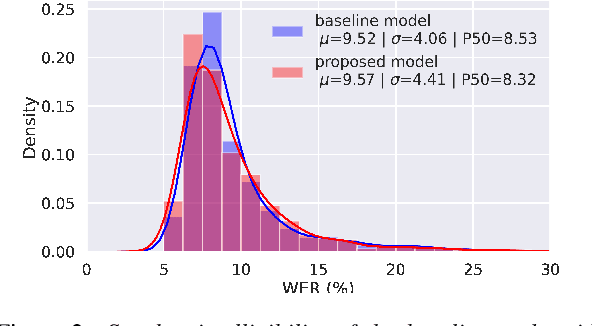

Text-to-speech systems recently achieved almost indistinguishable quality from human speech. However, the prosody of those systems is generally flatter than natural speech, producing samples with low expressiveness. Disentanglement of speaker id and prosody is crucial in text-to-speech systems to improve on naturalness and produce more variable syntheses. This paper proposes a new neural text-to-speech model that approaches the disentanglement problem by conditioning a Tacotron2-like architecture on flow-normalized speaker embeddings, and by substituting the reference encoder with a new learned latent distribution responsible for modeling the intra-sentence variability due to the prosody. By removing the reference encoder dependency, the speaker-leakage problem typically happening in this kind of systems disappears, producing more distinctive syntheses at inference time. The new model achieves significantly higher prosody variance than the baseline in a set of quantitative prosody features, as well as higher speaker distinctiveness, without decreasing the speaker intelligibility. Finally, we observe that the normalized speaker embeddings enable much richer speaker interpolations, substantially improving the distinctiveness of the new interpolated speakers.