 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating self-supervised features for expressive, multilingual voice conversion
May 13, 2025



Voice conversion (VC) systems are widely used for several applications, from speaker anonymisation to personalised speech synthesis. Supervised approaches learn a mapping between different speakers using parallel data, which is expensive to produce. Unsupervised approaches are typically trained to reconstruct the input signal, which is composed of the content and the speaker information. Disentangling these components is a challenge and often leads to speaker leakage or prosodic information removal. In this paper, we explore voice conversion by leveraging the potential of self-supervised learning (SSL). A combination of the latent representations of SSL models, concatenated with speaker embeddings, is fed to a vocoder which is trained to reconstruct the input. Zero-shot voice conversion results show that this approach allows to keep the prosody and content of the source speaker while matching the speaker similarity of a VC system based on phonetic posteriorgrams (PPGs).
* Published as a conference paper at ICASSP 2024
Exploring the Use of Contrastive Language-Image Pre-Training for Human Posture Classification: Insights from Yoga Pose Analysis
Jan 13, 2025Accurate human posture classification in images and videos is crucial for automated applications across various fields, including work safety, physical rehabilitation, sports training, or daily assisted living. Recently, multimodal learning methods, such as Contrastive Language-Image Pretraining (CLIP), have advanced significantly in jointly understanding images and text. This study aims to assess the effectiveness of CLIP in classifying human postures, focusing on its application in yoga. Despite the initial limitations of the zero-shot approach, applying transfer learning on 15,301 images (real and synthetic) with 82 classes has shown promising results. The article describes the full procedure for fine-tuning, including the choice for image description syntax, models and hyperparameters adjustment. The fine-tuned CLIP model, tested on 3826 images, achieves an accuracy of over 85%, surpassing the current state-of-the-art of previous works on the same dataset by approximately 6%, its training time being 3.5 times lower than what is needed to fine-tune a YOLOv8-based model. For more application-oriented scenarios, with smaller datasets of six postures each, containing 1301 and 401 training images, the fine-tuned models attain an accuracy of 98.8% and 99.1%, respectively. Furthermore, our experiments indicate that training with as few as 20 images per pose can yield around 90% accuracy in a six-class dataset. This study demonstrates that this multimodal technique can be effectively used for yoga pose classification, and possibly for human posture classification, in general. Additionally, CLIP inference time (around 7 ms) supports that the model can be integrated into automated systems for posture evaluation, e.g., for developing a real-time personal yoga assistant for performance assessment.
Enhancing the Stability of LLM-based Speech Generation Systems through Self-Supervised Representations
Feb 05, 2024


Large Language Models (LLMs) are one of the most promising technologies for the next era of speech generation systems, due to their scalability and in-context learning capabilities. Nevertheless, they suffer from multiple stability issues at inference time, such as hallucinations, content skipping or speech repetitions. In this work, we introduce a new self-supervised Voice Conversion (VC) architecture which can be used to learn to encode transitory features, such as content, separately from stationary ones, such as speaker ID or recording conditions, creating speaker-disentangled representations. Using speaker-disentangled codes to train LLMs for text-to-speech (TTS) allows the LLM to generate the content and the style of the speech only from the text, similarly to humans, while the speaker identity is provided by the decoder of the VC model. Results show that LLMs trained over speaker-disentangled self-supervised representations provide an improvement of 4.7pp in speaker similarity over SOTA entangled representations, and a word error rate (WER) 5.4pp lower. Furthermore, they achieve higher naturalness than human recordings of the LibriTTS test-other dataset. Finally, we show that using explicit reference embedding negatively impacts intelligibility (stability), with WER increasing by 14pp compared to the model that only uses text to infer the style.
GlowVC: Mel-spectrogram space disentangling model for language-independent text-free voice conversion
Jul 04, 2022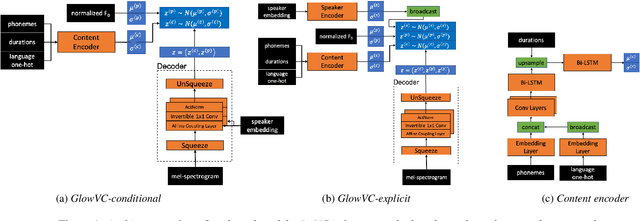

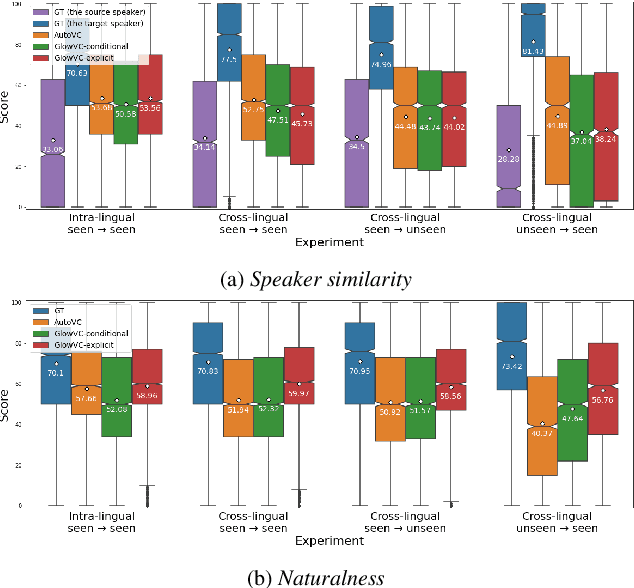
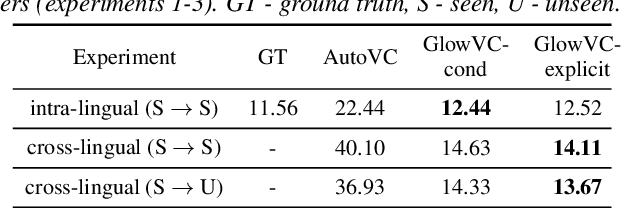
In this paper, we propose GlowVC: a multilingual multi-speaker flow-based model for language-independent text-free voice conversion. We build on Glow-TTS, which provides an architecture that enables use of linguistic features during training without the necessity of using them for VC inference. We consider two versions of our model: GlowVC-conditional and GlowVC-explicit. GlowVC-conditional models the distribution of mel-spectrograms with speaker-conditioned flow and disentangles the mel-spectrogram space into content- and pitch-relevant dimensions, while GlowVC-explicit models the explicit distribution with unconditioned flow and disentangles said space into content-, pitch- and speaker-relevant dimensions. We evaluate our models in terms of intelligibility, speaker similarity and naturalness for intra- and cross-lingual conversion in seen and unseen languages. GlowVC models greatly outperform AutoVC baseline in terms of intelligibility, while achieving just as high speaker similarity in intra-lingual VC, and slightly worse in the cross-lingual setting. Moreover, we demonstrate that GlowVC-explicit surpasses both GlowVC-conditional and AutoVC in terms of naturalness.