 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlowVC: Mel-spectrogram space disentangling model for language-independent text-free voice conversion
Paper and Code
Jul 04, 2022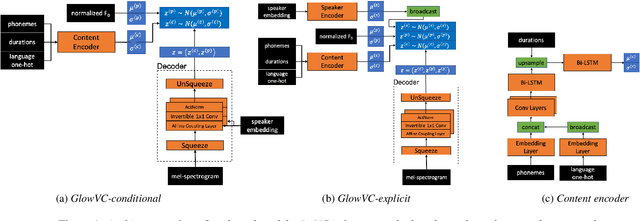

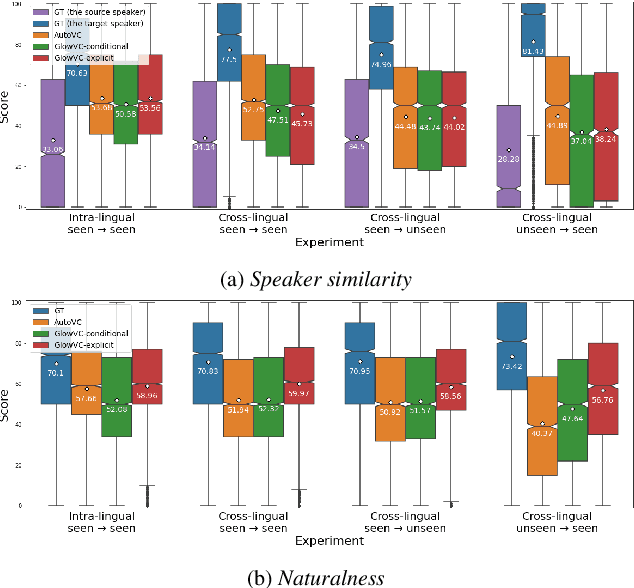
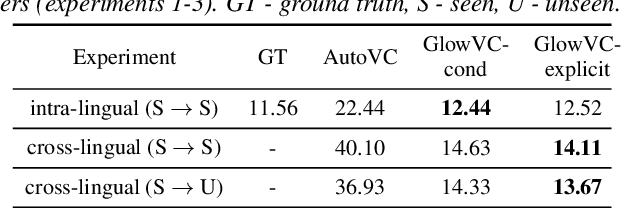
In this paper, we propose GlowVC: a multilingual multi-speaker flow-based model for language-independent text-free voice conversion. We build on Glow-TTS, which provides an architecture that enables use of linguistic features during training without the necessity of using them for VC inference. We consider two versions of our model: GlowVC-conditional and GlowVC-explicit. GlowVC-conditional models the distribution of mel-spectrograms with speaker-conditioned flow and disentangles the mel-spectrogram space into content- and pitch-relevant dimensions, while GlowVC-explicit models the explicit distribution with unconditioned flow and disentangles said space into content-, pitch- and speaker-relevant dimensions. We evaluate our models in terms of intelligibility, speaker similarity and naturalness for intra- and cross-lingual conversion in seen and unseen languages. GlowVC models greatly outperform AutoVC baseline in terms of intelligibility, while achieving just as high speaker similarity in intra-lingual VC, and slightly worse in the cross-lingual setting. Moreover, we demonstrate that GlowVC-explicit surpasses both GlowVC-conditional and AutoVC in terms of naturalness.