 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIMing for Standardised Explainability Evaluation in GNNs: A Framework and Case Study on Graph Kernel Networks
May 14, 2026Graph Neural Networks (GNNs) have advanced significantly in handling graph-structured data, but a comprehensive framework for evaluating explainability remains lacking. Existing evaluation frameworks primarily involve post-hoc explanations, and operate in the setting where multiple methods generate a suite of explanations for a single model. This makes comparison of explanations across models difficult. Evaluation of inherently interpretable models often targets a specific aspect of interpretability relevant to the model, but remains underdeveloped in terms of generating insight across a suite of measures. We introduce AIM, a comprehensive framework that addresses these limitations by measuring Accuracy, Instance-level explanations, and Model-level explanations. AIM is formulated with minimal constraints to enhance flexibility and facilitate broad applicability. Here, we use AIM in a pipeline, extracting explanations from inherently interpretable GNNs such as graph kernel networks (GKNs) and prototype networks (PNs), evaluating these explanations with AIM, identifying their limitations and obtaining insights to their characteristics. Taking GKNs as a case study, we show how the insights obtained from AIM can be used to develop an updated model, xGKN, that maintains high accuracy while demonstrating improved explainability. Our approach aims to advance the field of Explainable AI (XAI) for GNNs, providing more robust and practical solutions for understanding and improving complex models.
* 19 pages,4 figures, 8 tables
WavesFM: Hierarchical Representation Learning for Longitudinal Wearable Sensor Waveforms
May 09, 2026Wearable sensors enable the continuous acquisition of high-resolution physiological waveforms, such as photoplethysmography and accelerometry, under free-living conditions. However, inferring health-related phenotypes from these signals presents significant challenges due to high sampling frequencies, multimodal dependencies, and extreme sequence lengths (e.g., weeks of recordings), compounded by a scarcity of ground-truth labels. To address these challenges, existing self-supervised learning (SSL) methodologies typically follow two paradigms: (1) learning rich morphological representations from short waveform segments while collapsing longitudinal dynamics through simple aggregation, or (2) modeling behavioral patterns from coarse, hand-crafted features (e.g. heart rate, step counts) spanning longer horizons but foregoing subtle, predictive signatures in raw waveforms. To bridge this gap, we propose WavesFM, a foundation model utilizing a two-stage SSL framework for longitudinal physiological data. Specifically, we decompose the learning problem into two stages: first, a segment-level encoder is pretrained to extract local embeddings from short waveforms; subsequently, a temporal encoder is trained to model the sequence of these embeddings across a multi-day horizon. This hierarchical approach overcomes the computational complexity of high-resolution, long-sequence data, allowing the overall model to capture both local signal semantics and the complex circadian and inter-day variations governing physiological dynamics. Pretrained on over 6.8M hours (N=324k individuals) of recordings for the first stage and 5.3M hours (N=10k) for the second stage, WavesFM demonstrates superior performance across 58 diverse tasks spanning demographics, lifestyle, health conditions, and medications.
B-XAIC Dataset: Benchmarking Explainable AI for Graph Neural Networks Using Chemical Data
May 28, 2025Understanding the reasoning behind deep learning model predictions is crucial in cheminformatics and drug discovery, where molecular design determines their properties. However, current evaluation frameworks for Explainable AI (XAI) in this domain often rely on artificial datasets or simplified tasks, employing data-derived metrics that fail to capture the complexity of real-world scenarios and lack a direct link to explanation faithfulness. To address this, we introduce B-XAIC, a novel benchmark constructed from real-world molecular data and diverse tasks with known ground-truth rationales for assigned labels. Through a comprehensive evaluation using B-XAIC, we reveal limitations of existing XAI methods for Graph Neural Networks (GNNs) in the molecular domain. This benchmark provides a valuable resource for gaining deeper insights into the faithfulness of XAI, facilitating the development of more reliable and interpretable models.
Face Identity-Aware Disentanglement in StyleGAN
Sep 21, 2023



Conditional GANs are frequently used for manipulating the attributes of face images, such as expression, hairstyle, pose, or age. Even though the state-of-the-art models successfully modify the requested attributes, they simultaneously modify other important characteristics of the image, such as a person's identity. In this paper, we focus on solving this problem by introducing PluGeN4Faces, a plugin to StyleGAN, which explicitly disentangles face attributes from a person's identity. Our key idea is to perform training on images retrieved from movie frames, where a given person appears in various poses and with different attributes. By applying a type of contrastive loss, we encourage the model to group images of the same person in similar regions of latent space. Our experiments demonstrate that the modifications of face attributes performed by PluGeN4Faces are significantly less invasive on the remaining characteristics of the image than in the existing state-of-the-art models.
Remap, warp and attend: Non-parallel many-to-many accent conversion with Normalizing Flows
Nov 10, 2022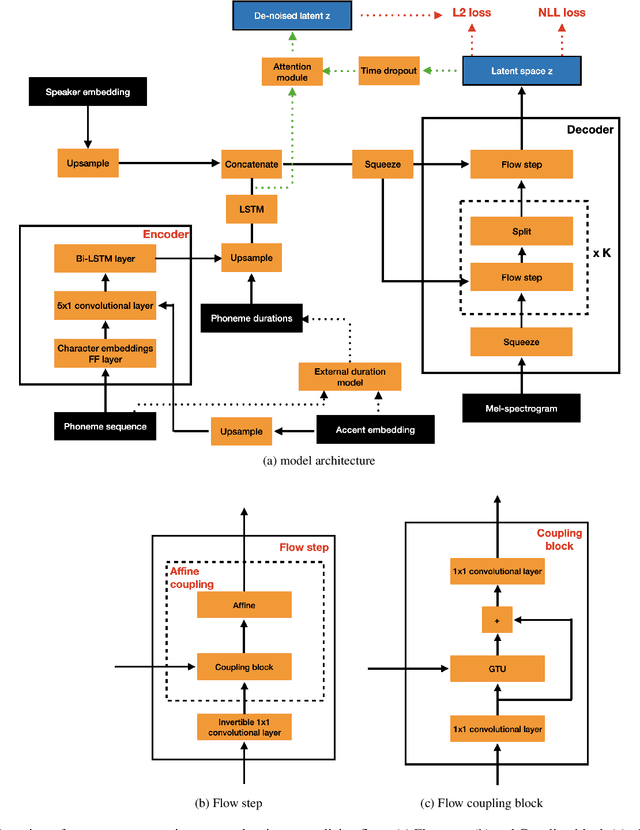

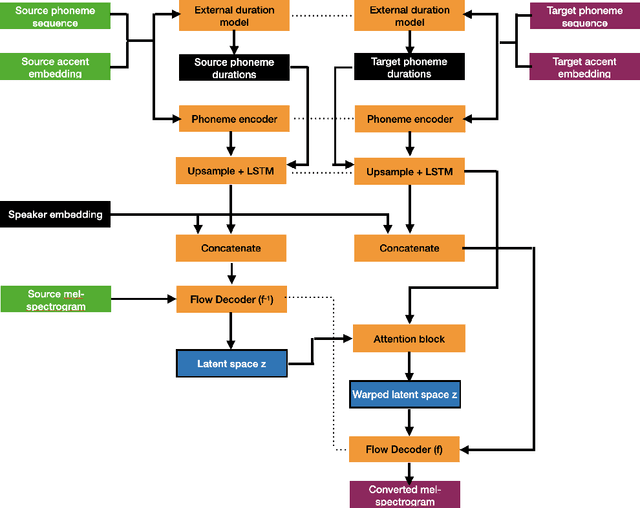

Regional accents of the same language affect not only how words are pronounced (i.e., phonetic content), but also impact prosodic aspects of speech such as speaking rate and intonation. This paper investigates a novel flow-based approach to accent conversion using normalizing flows. The proposed approach revolves around three steps: remapping the phonetic conditioning, to better match the target accent, warping the duration of the converted speech, to better suit the target phonemes, and an attention mechanism that implicitly aligns source and target speech sequences. The proposed remap-warp-attend system enables adaptation of both phonetic and prosodic aspects of speech while allowing for source and converted speech signals to be of different lengths. Objective and subjective evaluations show that the proposed approach significantly outperforms a competitive CopyCat baseline model in terms of similarity to the target accent, naturalness and intelligibility.
GlowVC: Mel-spectrogram space disentangling model for language-independent text-free voice conversion
Jul 04, 2022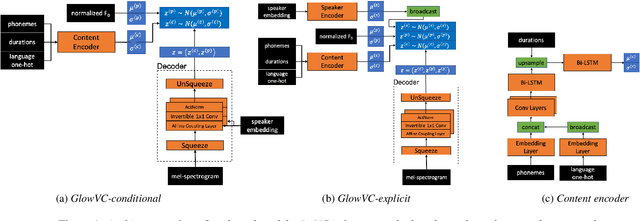

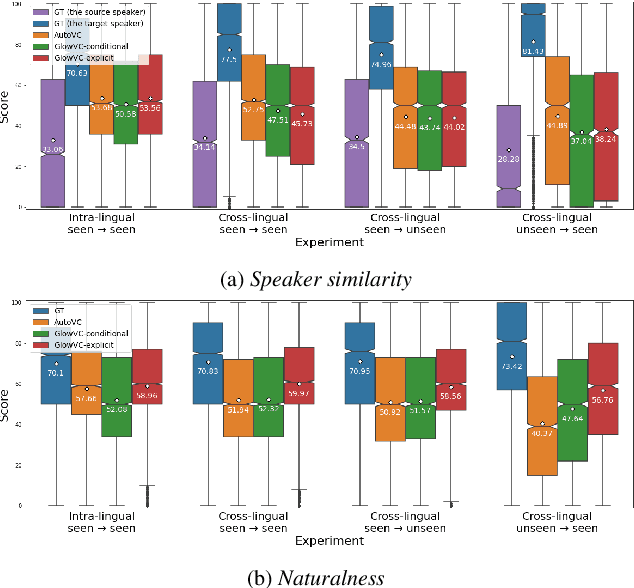
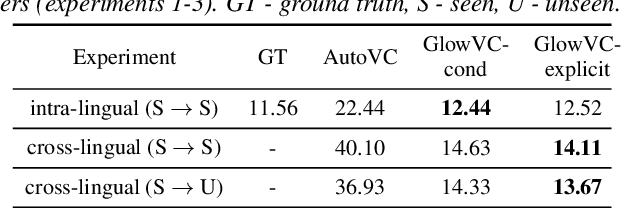
In this paper, we propose GlowVC: a multilingual multi-speaker flow-based model for language-independent text-free voice conversion. We build on Glow-TTS, which provides an architecture that enables use of linguistic features during training without the necessity of using them for VC inference. We consider two versions of our model: GlowVC-conditional and GlowVC-explicit. GlowVC-conditional models the distribution of mel-spectrograms with speaker-conditioned flow and disentangles the mel-spectrogram space into content- and pitch-relevant dimensions, while GlowVC-explicit models the explicit distribution with unconditioned flow and disentangles said space into content-, pitch- and speaker-relevant dimensions. We evaluate our models in terms of intelligibility, speaker similarity and naturalness for intra- and cross-lingual conversion in seen and unseen languages. GlowVC models greatly outperform AutoVC baseline in terms of intelligibility, while achieving just as high speaker similarity in intra-lingual VC, and slightly worse in the cross-lingual setting. Moreover, we demonstrate that GlowVC-explicit surpasses both GlowVC-conditional and AutoVC in terms of naturalness.
Text-free non-parallel many-to-many voice conversion using normalising flows
Mar 15, 2022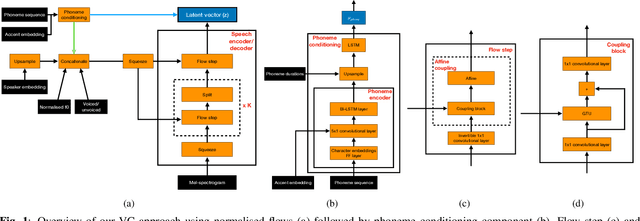
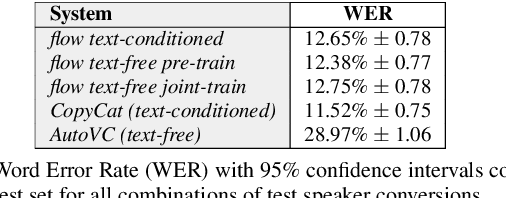
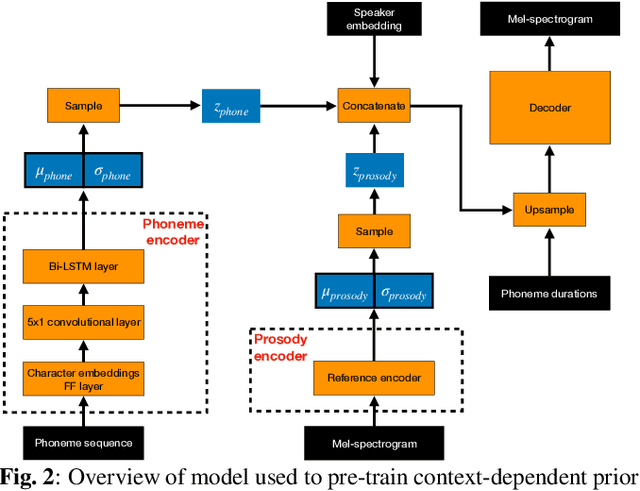
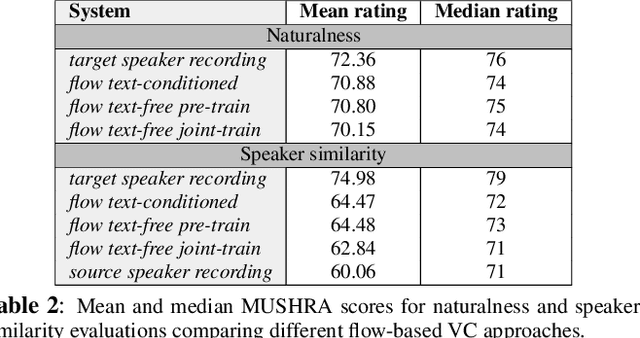
Non-parallel voice conversion (VC) is typically achieved using lossy representations of the source speech. However, ensuring only speaker identity information is dropped whilst all other information from the source speech is retained is a large challenge. This is particularly challenging in the scenario where at inference-time we have no knowledge of the text being read, i.e., text-free VC. To mitigate this, we investigate information-preserving VC approaches. Normalising flows have gained attention for text-to-speech synthesis, however have been under-explored for VC. Flows utilize invertible functions to learn the likelihood of the data, thus provide a lossless encoding of speech. We investigate normalising flows for VC in both text-conditioned and text-free scenarios. Furthermore, for text-free VC we compare pre-trained and jointly-learnt priors. Flow-based VC evaluations show no degradation between text-free and text-conditioned VC, resulting in improvements over the state-of-the-art. Also, joint-training of the prior is found to negatively impact text-free VC quality.
HyperCube: Implicit Field Representations of Voxelized 3D Models
Oct 12, 2021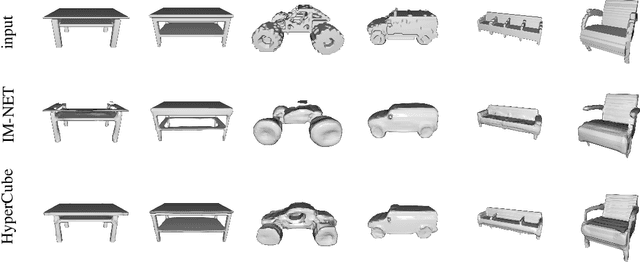
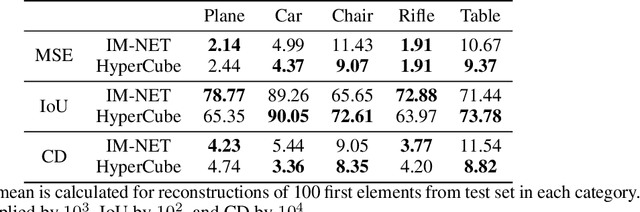
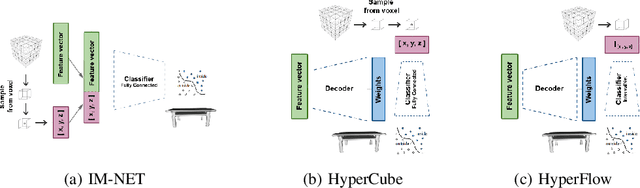
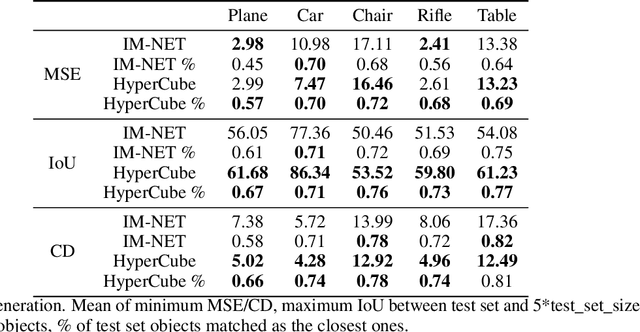
Recently introduced implicit field representations offer an effective way of generating 3D object shapes. They leverage implicit decoder trained to take a 3D point coordinate concatenated with a shape encoding and to output a value which indicates whether the point is outside the shape or not. Although this approach enables efficient rendering of visually plausible objects, it has two significant limitations. First, it is based on a single neural network dedicated for all objects from a training set which results in a cumbersome training procedure and its application in real life. More importantly, the implicit decoder takes only points sampled within voxels (and not the entire voxels) which yields problems at the classification boundaries and results in empty spaces within the rendered mesh. To solve the above limitations, we introduce a new HyperCube architecture based on interval arithmetic network, that enables direct processing of 3D voxels, trained using a hypernetwork paradigm to enforce model convergence. Instead of processing individual 3D samples from within a voxel, our approach allows to input the entire voxel (3D cube) represented with its convex hull coordinates, while the target network constructed by a hypernet assigns it to an inside or outside category. As a result our HyperCube model outperforms the competing approaches both in terms of training and inference efficiency, as well as the final mesh quality.
PluGeN: Multi-Label Conditional Generation From Pre-Trained Models
Sep 18, 2021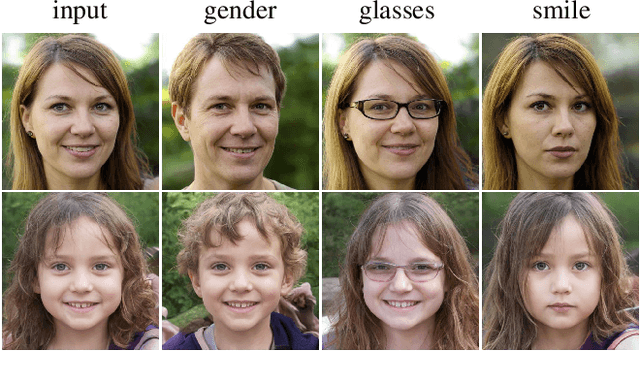
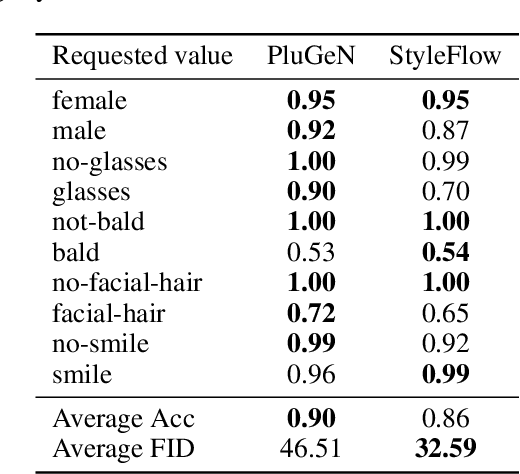
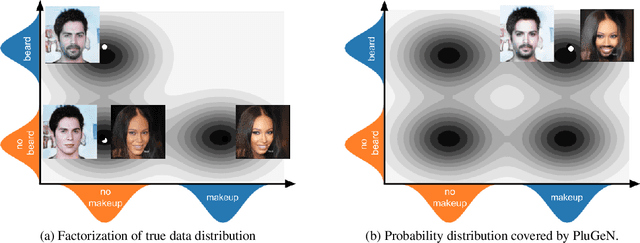
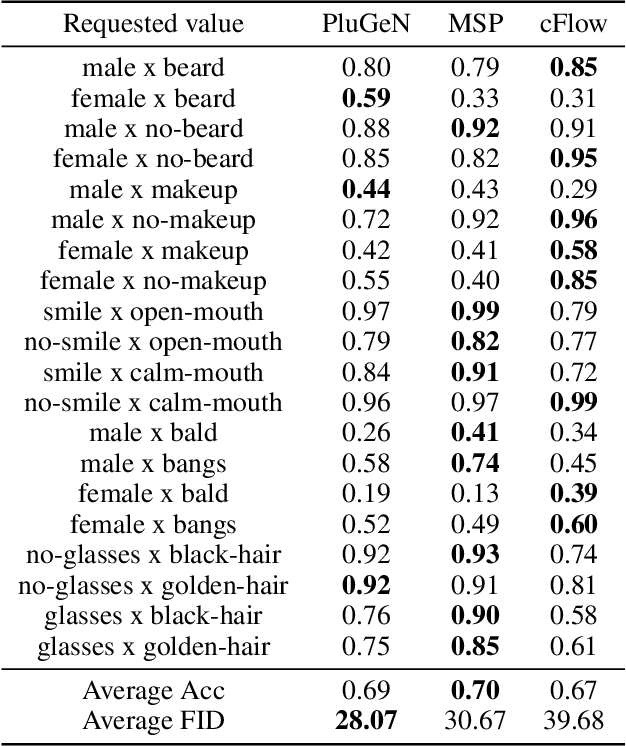
Modern generative models achieve excellent quality in a variety of tasks including image or text generation and chemical molecule modeling. However, existing methods often lack the essential ability to generate examples with requested properties, such as the age of the person in the photo or the weight of the generated molecule. Incorporating such additional conditioning factors would require rebuilding the entire architecture and optimizing the parameters from scratch. Moreover, it is difficult to disentangle selected attributes so that to perform edits of only one attribute while leaving the others unchanged. To overcome these limitations we propose PluGeN (Plugin Generative Network), a simple yet effective generative technique that can be used as a plugin to pre-trained generative models. The idea behind our approach is to transform the entangled latent representation using a flow-based module into a multi-dimensional space where the values of each attribute are modeled as an independent one-dimensional distribution. In consequence, PluGeN can generate new samples with desired attributes as well as manipulate labeled attributes of existing examples. Due to the disentangling of the latent representation, we are even able to generate samples with rare or unseen combinations of attributes in the dataset, such as a young person with gray hair, men with make-up, or women with beards. We combined PluGeN with GAN and VAE models and applied it to conditional generation and manipulation of images and chemical molecule modeling. Experiments demonstrate that PluGeN preserves the quality of backbone models while adding the ability to control the values of labeled attributes.