 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating self-supervised features for expressive, multilingual voice conversion
May 13, 2025



Voice conversion (VC) systems are widely used for several applications, from speaker anonymisation to personalised speech synthesis. Supervised approaches learn a mapping between different speakers using parallel data, which is expensive to produce. Unsupervised approaches are typically trained to reconstruct the input signal, which is composed of the content and the speaker information. Disentangling these components is a challenge and often leads to speaker leakage or prosodic information removal. In this paper, we explore voice conversion by leveraging the potential of self-supervised learning (SSL). A combination of the latent representations of SSL models, concatenated with speaker embeddings, is fed to a vocoder which is trained to reconstruct the input. Zero-shot voice conversion results show that this approach allows to keep the prosody and content of the source speaker while matching the speaker similarity of a VC system based on phonetic posteriorgrams (PPGs).
* Published as a conference paper at ICASSP 2024
The devil is in discretization discrepancy. Robustifying Differentiable NAS with Single-Stage Searching Protocol
May 26, 2024Neural Architecture Search (NAS) has been widely adopted to design neural networks for various computer vision tasks. One of its most promising subdomains is differentiable NAS (DNAS), where the optimal architecture is found in a differentiable manner. However, gradient-based methods suffer from the discretization error, which can severely damage the process of obtaining the final architecture. In our work, we first study the risk of discretization error and show how it affects an unregularized supernet. Then, we present that penalizing high entropy, a common technique of architecture regularization, can hinder the supernet's performance. Therefore, to robustify the DNAS framework, we introduce a novel single-stage searching protocol, which is not reliant on decoding a continuous architecture. Our results demonstrate that this approach outperforms other DNAS methods by achieving 75.3% in the searching stage on the Cityscapes validation dataset and attains performance 1.1% higher than the optimal network of DCNAS on the non-dense search space comprising short connections. The entire training process takes only 5.5 GPU days due to the weight reuse, and yields a computationally efficient architecture. Additionally, we propose a new dataset split procedure, which substantially improves results and prevents architecture degeneration in DARTS.
Creating New Voices using Normalizing Flows
Dec 22, 2023



Creating realistic and natural-sounding synthetic speech remains a big challenge for voice identities unseen during training. As there is growing interest in synthesizing voices of new speakers, here we investigate the ability of normalizing flows in text-to-speech (TTS) and voice conversion (VC) modes to extrapolate from speakers observed during training to create unseen speaker identities. Firstly, we create an approach for TTS and VC, and then we comprehensively evaluate our methods and baselines in terms of intelligibility, naturalness, speaker similarity, and ability to create new voices. We use both objective and subjective metrics to benchmark our techniques on 2 evaluation tasks: zero-shot and new voice speech synthesis. The goal of the former task is to measure the precision of the conversion to an unseen voice. The goal of the latter is to measure the ability to create new voices. Extensive evaluations demonstrate that the proposed approach systematically allows to obtain state-of-the-art performance in zero-shot speech synthesis and creates various new voices, unobserved in the training set. We consider this work to be the first attempt to synthesize new voices based on mel-spectrograms and normalizing flows, along with a comprehensive analysis and comparison of the TTS and VC modes.
* Interspeech 2022
Comparing normalizing flows and diffusion models for prosody and acoustic modelling in text-to-speech
Jul 31, 2023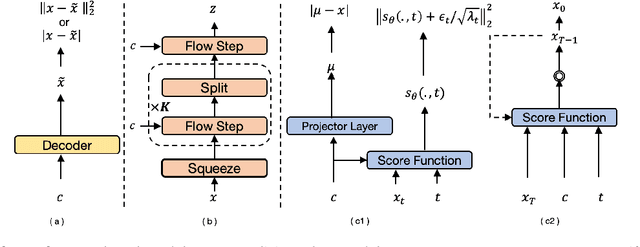
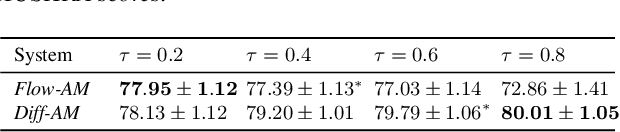
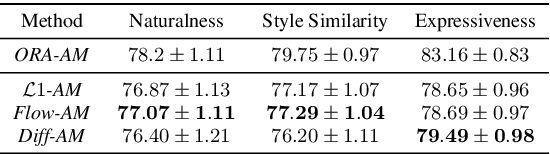
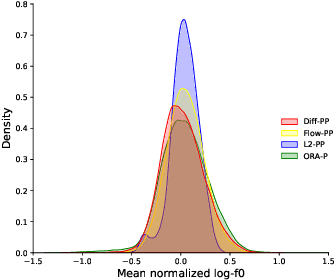
Neural text-to-speech systems are often optimized on L1/L2 losses, which make strong assumptions about the distributions of the target data space. Aiming to improve those assumptions, Normalizing Flows and Diffusion Probabilistic Models were recently proposed as alternatives. In this paper, we compare traditional L1/L2-based approaches to diffusion and flow-based approaches for the tasks of prosody and mel-spectrogram prediction for text-to-speech synthesis. We use a prosody model to generate log-f0 and duration features, which are used to condition an acoustic model that generates mel-spectrograms. Experimental results demonstrate that the flow-based model achieves the best performance for spectrogram prediction, improving over equivalent diffusion and L1 models. Meanwhile, both diffusion and flow-based prosody predictors result in significant improvements over a typical L2-trained prosody models.
SCRAPS: Speech Contrastive Representations of Acoustic and Phonetic Spaces
Jul 23, 2023



Numerous examples in the literature proved that deep learning models have the ability to work well with multimodal data. Recently, CLIP has enabled deep learning systems to learn shared latent spaces between images and text descriptions, with outstanding zero- or few-shot results in downstream tasks. In this paper we explore the same idea proposed by CLIP but applied to the speech domain, where the phonetic and acoustic spaces usually coexist. We train a CLIP-based model with the aim to learn shared representations of phonetic and acoustic spaces. The results show that the proposed model is sensible to phonetic changes, with a 91% of score drops when replacing 20% of the phonemes at random, while providing substantial robustness against different kinds of noise, with a 10% performance drop when mixing the audio with 75% of Gaussian noise. We also provide empirical evidence showing that the resulting embeddings are useful for a variety of downstream applications, such as intelligibility evaluation and the ability to leverage rich pre-trained phonetic embeddings in speech generation task. Finally, we discuss potential applications with interesting implications for the speech generation and recognition fields.
Remap, warp and attend: Non-parallel many-to-many accent conversion with Normalizing Flows
Nov 10, 2022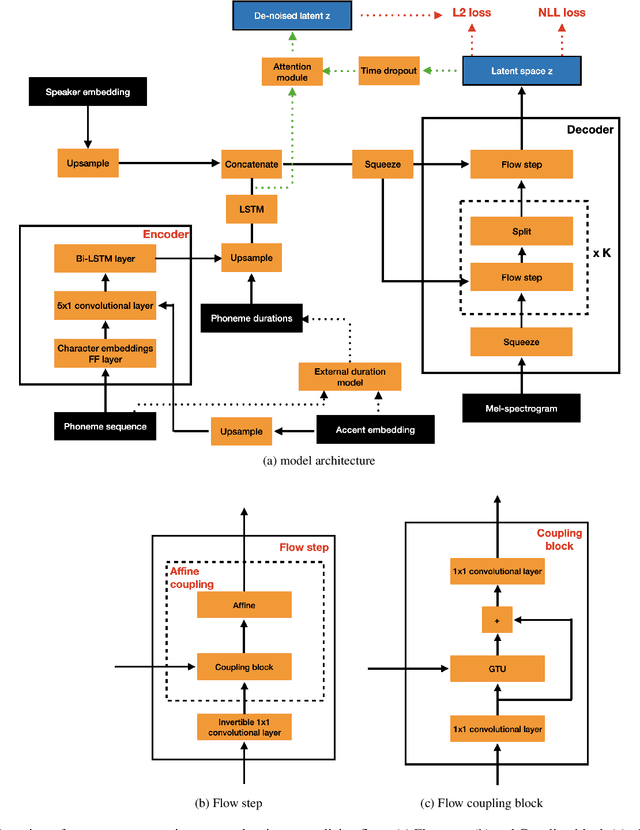

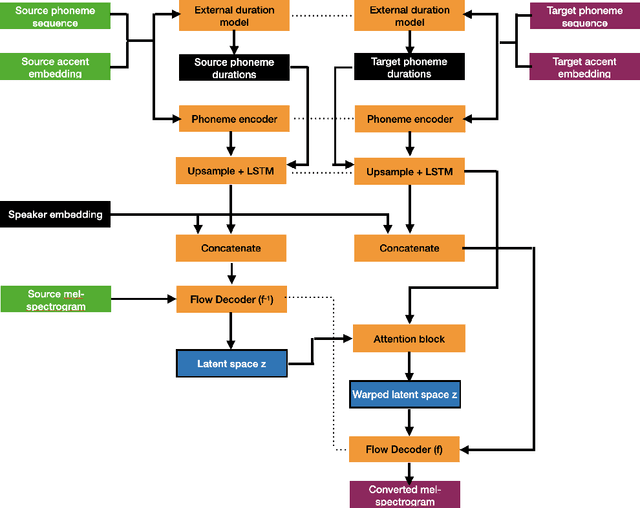

Regional accents of the same language affect not only how words are pronounced (i.e., phonetic content), but also impact prosodic aspects of speech such as speaking rate and intonation. This paper investigates a novel flow-based approach to accent conversion using normalizing flows. The proposed approach revolves around three steps: remapping the phonetic conditioning, to better match the target accent, warping the duration of the converted speech, to better suit the target phonemes, and an attention mechanism that implicitly aligns source and target speech sequences. The proposed remap-warp-attend system enables adaptation of both phonetic and prosodic aspects of speech while allowing for source and converted speech signals to be of different lengths. Objective and subjective evaluations show that the proposed approach significantly outperforms a competitive CopyCat baseline model in terms of similarity to the target accent, naturalness and intelligibility.
RainBench: Towards Global Precipitation Forecasting from Satellite Imagery
Dec 17, 2020
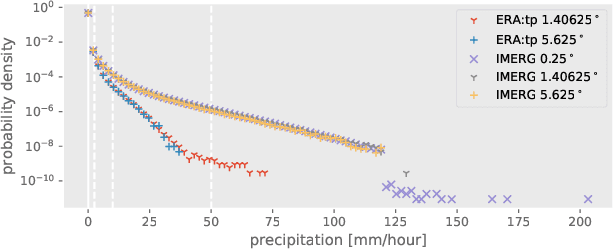
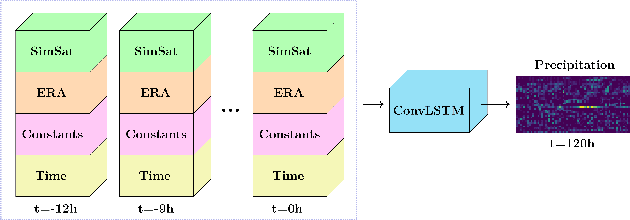
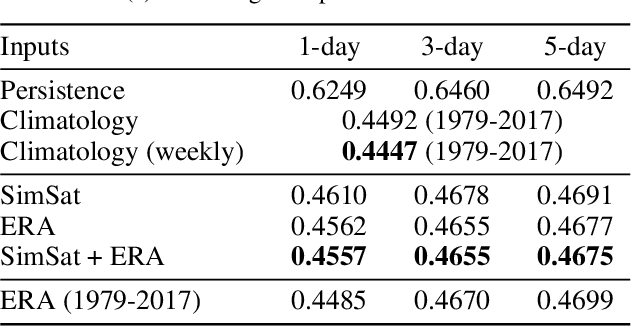
Extreme precipitation events, such as violent rainfall and hail storms, routinely ravage economies and livelihoods around the developing world. Climate change further aggravates this issue. Data-driven deep learning approaches could widen the access to accurate multi-day forecasts, to mitigate against such events. However, there is currently no benchmark dataset dedicated to the study of global precipitation forecasts. In this paper, we introduce \textbf{RainBench}, a new multi-modal benchmark dataset for data-driven precipitation forecasting. It includes simulated satellite data, a selection of relevant meteorological data from the ERA5 reanalysis product, and IMERG precipitation data. We also release \textbf{PyRain}, a library to process large precipitation datasets efficiently. We present an extensive analysis of our novel dataset and establish baseline results for two benchmark medium-range precipitation forecasting tasks. Finally, we discuss existing data-driven weather forecasting methodologies and suggest future research avenues.
$\mathbf{G^{3}AN}$: This video does not exist. Disentangling motion and appearance for video generation
Dec 11, 2019
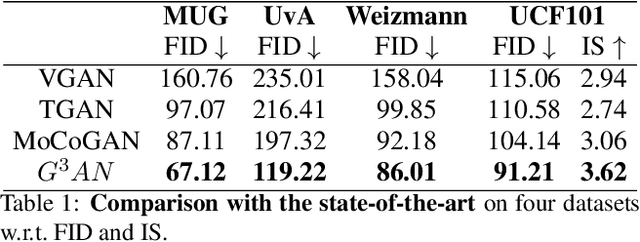
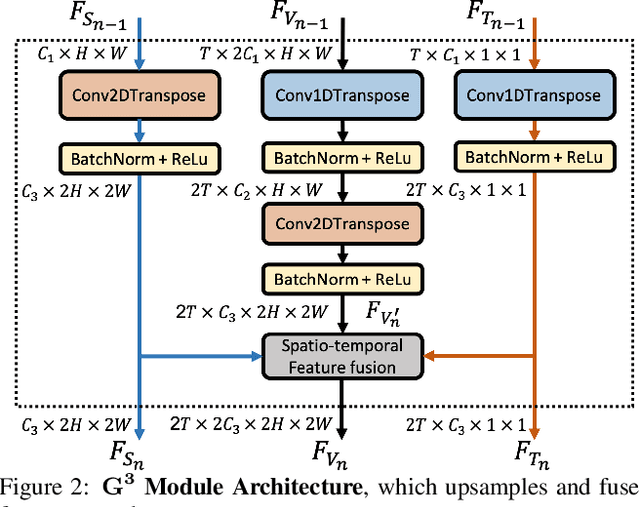
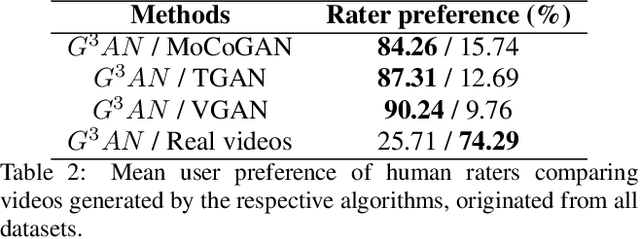
Creating realistic human videos introduces the challenge of being able to simultaneously generate both appearance, as well as motion. To tackle this challenge, we propose the novel spatio-temporal GAN-architecture $G^3AN$, which seeks to capture the distribution of high dimensional video data and to model appearance and motion in disentangled manner. The latter is achieved by decomposing appearance and motion in a three-stream Generator, where the main stream aims to model spatio-temporal consistency, whereas the two auxiliary streams augment the main stream with multi-scale appearance and motion features, respectively. An extensive quantitative and qualitative analysis shows that our model systematically and significantly outperforms state-of-the-art methods on the facial expression datasets MUG and UvA-NEMO, as well as the Weizmann and UCF101 datasets on human action. Additional analysis on the learned latent representations confirms the successful decomposition of appearance and motion.
Mapping Informal Settlements in Developing Countries using Machine Learning and Low Resolution Multi-spectral Data
Jan 03, 2019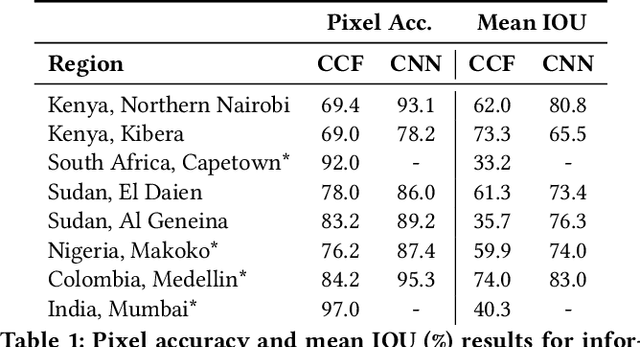

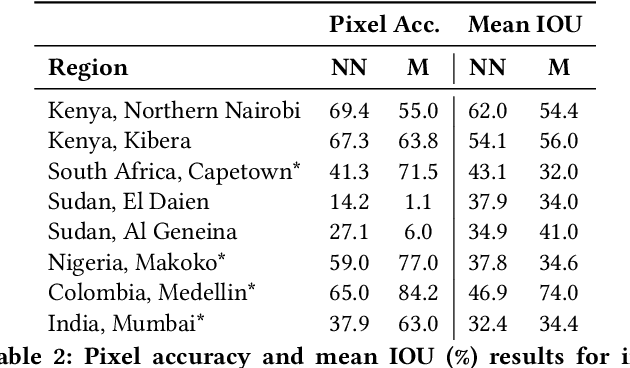

Informal settlements are home to the most socially and economically vulnerable people on the planet. In order to deliver effective economic and social aid, non-government organizations (NGOs), such as the United Nations Children's Fund (UNICEF), require detailed maps of the locations of informal settlements. However, data regarding informal and formal settlements is primarily unavailable and if available is often incomplete. This is due, in part, to the cost and complexity of gathering data on a large scale. An additional complication is that the definition of an informal settlement is also very broad, which makes it a non-trivial task to collect data. This also makes it challenging to teach a machine what to look for. Due to these challenges we provide three contributions in this work. 1) A brand new machine learning data-set, purposely developed for informal settlement detection that contains a series of low and very-high resolution imagery, with accompanying ground truth annotations marking the locations of known informal settlements. 2) We demonstrate that it is possible to detect informal settlements using freely available low-resolution (LR) data, in contrast to previous studies that use very-high resolution (VHR) satellite and aerial imagery, which is typically cost-prohibitive for NGOs. 3) We demonstrate two effective classification schemes on our curated data set, one that is cost-efficient for NGOs and another that is cost-prohibitive for NGOs, but has additional utility. We integrate these schemes into a semi-automated pipeline that converts either a LR or VHR satellite image into a binary map that encodes the locations of informal settlements. We evaluate and compare our methods.
Multi$^{\mathbf{3}}$Net: Segmenting Flooded Buildings via Fusion of Multiresolution, Multisensor, and Multitemporal Satellite Imagery
Dec 05, 2018
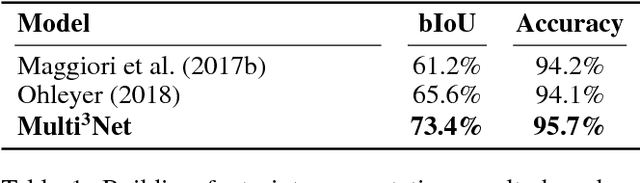
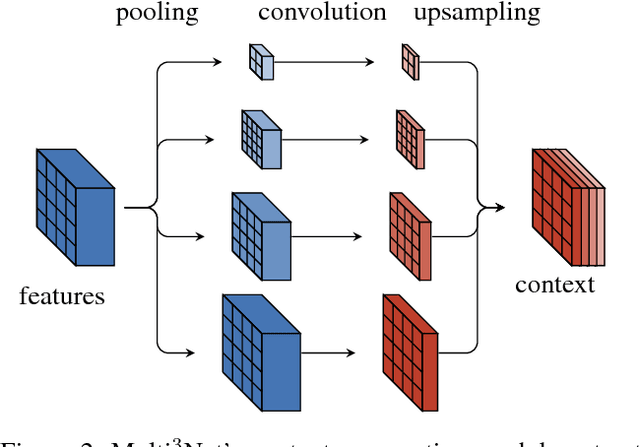
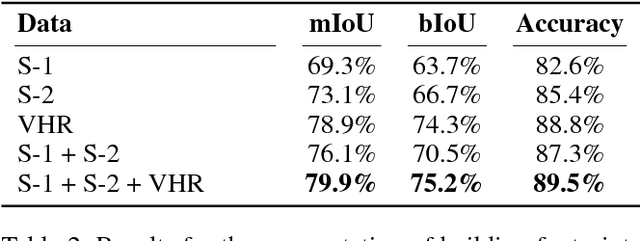
We propose a novel approach for rapid segmentation of flooded buildings by fusing multiresolution, multisensor, and multitemporal satellite imagery in a convolutional neural network. Our model significantly expedites the generation of satellite imagery-based flood maps, crucial for first responders and local authorities in the early stages of flood events. By incorporating multitemporal satellite imagery, our model allows for rapid and accurate post-disaster damage assessment and can be used by governments to better coordinate medium- and long-term financial assistance programs for affected areas. The network consists of multiple streams of encoder-decoder architectures that extract spatiotemporal information from medium-resolution images and spatial information from high-resolution images before fusing the resulting representations into a single medium-resolution segmentation map of flooded buildings. We compare our model to state-of-the-art methods for building footprint segmentation as well as to alternative fusion approaches for the segmentation of flooded buildings and find that our model performs best on both tasks. We also demonstrate that our model produces highly accurate segmentation maps of flooded buildings using only publicly available medium-resolution data instead of significantly more detailed but sparsely available very high-resolution data. We release the first open-source dataset of fully preprocessed and labeled multiresolution, multispectral, and multitemporal satellite images of disaster sites along with our source code.