 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Knowledge Distillation via Flow-based Voice Conversion for Robust Polyglot Text-To-Speech
Sep 15, 2023In this work, we introduce a framework for cross-lingual speech synthesis, which involves an upstream Voice Conversion (VC) model and a downstream Text-To-Speech (TTS) model. The proposed framework consists of 4 stages. In the first two stages, we use a VC model to convert utterances in the target locale to the voice of the target speaker. In the third stage, the converted data is combined with the linguistic features and durations from recordings in the target language, which are then used to train a single-speaker acoustic model. Finally, the last stage entails the training of a locale-independent vocoder. Our evaluations show that the proposed paradigm outperforms state-of-the-art approaches which are based on training a large multilingual TTS model. In addition, our experiments demonstrate the robustness of our approach with different model architectures, languages, speakers and amounts of data. Moreover, our solution is especially beneficial in low-resource settings.
Remap, warp and attend: Non-parallel many-to-many accent conversion with Normalizing Flows
Nov 10, 2022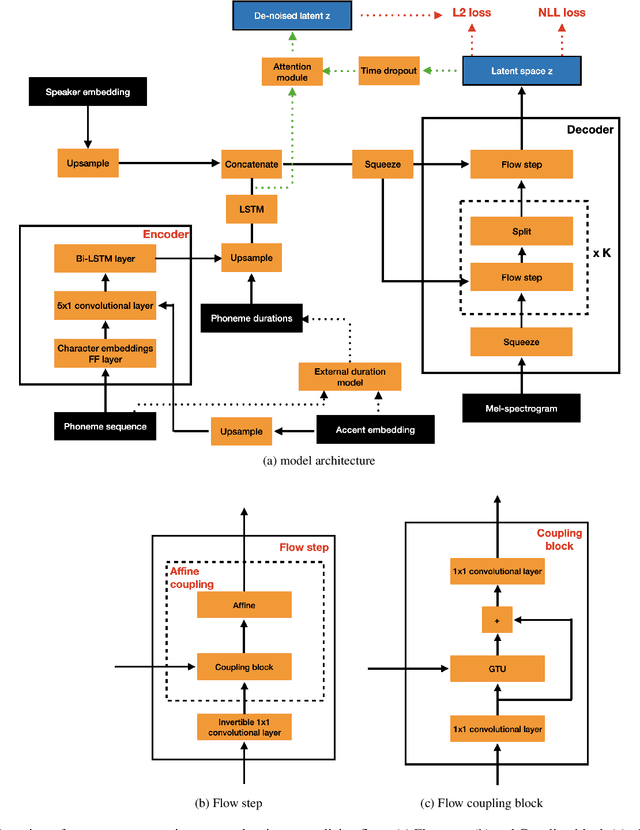

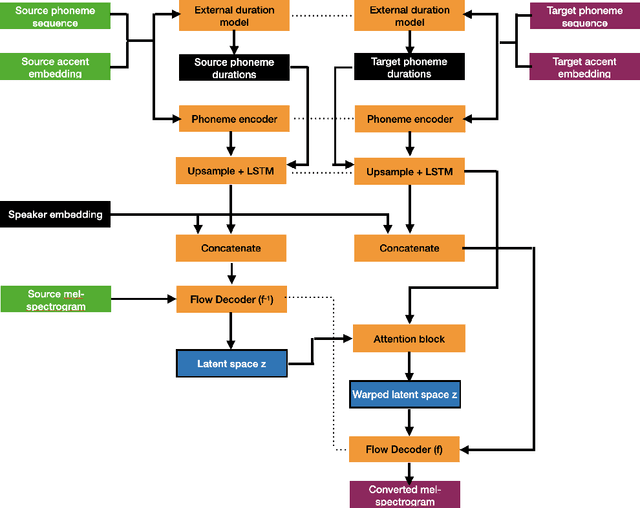

Regional accents of the same language affect not only how words are pronounced (i.e., phonetic content), but also impact prosodic aspects of speech such as speaking rate and intonation. This paper investigates a novel flow-based approach to accent conversion using normalizing flows. The proposed approach revolves around three steps: remapping the phonetic conditioning, to better match the target accent, warping the duration of the converted speech, to better suit the target phonemes, and an attention mechanism that implicitly aligns source and target speech sequences. The proposed remap-warp-attend system enables adaptation of both phonetic and prosodic aspects of speech while allowing for source and converted speech signals to be of different lengths. Objective and subjective evaluations show that the proposed approach significantly outperforms a competitive CopyCat baseline model in terms of similarity to the target accent, naturalness and intelligibility.
Exploiting Unsupervised Pre-training and Automated Feature Engineering for Low-resource Hate Speech Detection in Polish
Jun 17, 2019

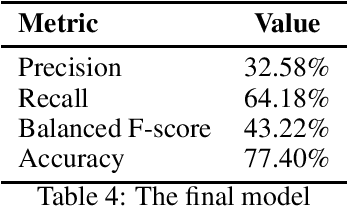
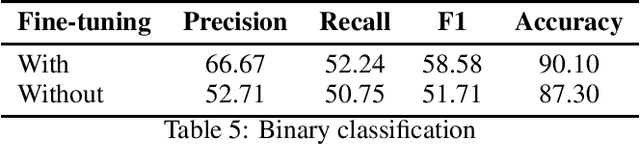
This paper presents our contribution to PolEval 2019 Task 6: Hate speech and bullying detection. We describe three parallel approaches that we followed: fine-tuning a pre-trained ULMFiT model to our classification task, fine-tuning a pre-trained BERT model to our classification task, and using the TPOT library to find the optimal pipeline. We present results achieved by these three tools and review their advantages and disadvantages in terms of user experience. Our team placed second in subtask 2 with a shallow model found by TPOT: a~logistic regression classifier with non-trivial feature engineering.
* http://poleval.pl/publication