 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImmuVis: Hyperconvolutional Foundation Model for Imaging Mass Cytometry
Feb 04, 2026We present ImmuVis, an efficient convolutional foundation model for imaging mass cytometry (IMC), a high-throughput multiplex imaging technology that handles molecular marker measurements as image channels and enables large-scale spatial tissue profiling. Unlike natural images, multiplex imaging lacks a fixed channel space, as real-world marker sets vary across studies, violating a core assumption of standard vision backbones. To address this, ImmuVis introduces marker-adaptive hyperconvolutions that generate convolutional kernels from learned marker embeddings, enabling a single model to operate on arbitrary measured marker subsets without retraining. We pretrain ImmuVis on the largest to-date dataset, IMC17M (28 cohorts, 24,405 images, 265 markers, over 17M patches), using self-supervised masked reconstruction. ImmuVis outperforms SOTA baselines and ablations in virtual staining and downstream classification tasks at substantially lower compute cost than transformer-based alternatives, and is the sole model that provides calibrated uncertainty via a heteroscedastic likelihood objective. These results position ImmuVis as a practical, efficient foundation model for real-world IMC modeling.
PepCompass: Navigating peptide embedding spaces using Riemannian Geometry
Oct 02, 2025Antimicrobial peptide discovery is challenged by the astronomical size of peptide space and the relative scarcity of active peptides. Generative models provide continuous latent "maps" of peptide space, but conventionally ignore decoder-induced geometry and rely on flat Euclidean metrics, rendering exploration and optimization distorted and inefficient. Prior manifold-based remedies assume fixed intrinsic dimensionality, which critically fails in practice for peptide data. Here, we introduce PepCompass, a geometry-aware framework for peptide exploration and optimization. At its core, we define a Union of $\kappa$-Stable Riemannian Manifolds $\mathbb{M}^{\kappa}$, a family of decoder-induced manifolds that captures local geometry while ensuring computational stability. We propose two local exploration methods: Second-Order Riemannian Brownian Efficient Sampling, which provides a convergent second-order approximation to Riemannian Brownian motion, and Mutation Enumeration in Tangent Space, which reinterprets tangent directions as discrete amino-acid substitutions. Combining these yields Local Enumeration Bayesian Optimization (LE-BO), an efficient algorithm for local activity optimization. Finally, we introduce Potential-minimizing Geodesic Search (PoGS), which interpolates between prototype embeddings along property-enriched geodesics, biasing discovery toward seeds, i.e. peptides with favorable activity. In-vitro validation confirms the effectiveness of PepCompass: PoGS yields four novel seeds, and subsequent optimization with LE-BO discovers 25 highly active peptides with broad-spectrum activity, including against resistant bacterial strains. These results demonstrate that geometry-informed exploration provides a powerful new paradigm for antimicrobial peptide design.
A generative recommender system with GMM prior for cancer drug generation and sensitivity prediction
Jun 07, 2022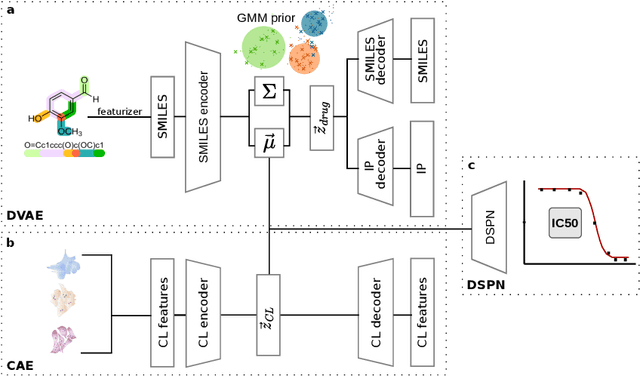

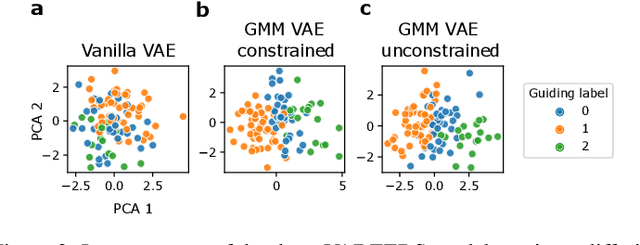
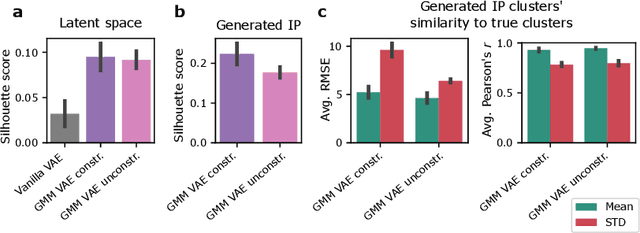
Recent emergence of high-throughput drug screening assays sparkled an intensive development of machine learning methods, including models for prediction of sensitivity of cancer cell lines to anti-cancer drugs, as well as methods for generation of potential drug candidates. However, a concept of generation of compounds with specific properties and simultaneous modeling of their efficacy against cancer cell lines has not been comprehensively explored. To address this need, we present VADEERS, a Variational Autoencoder-based Drug Efficacy Estimation Recommender System. The generation of compounds is performed by a novel variational autoencoder with a semi-supervised Gaussian Mixture Model (GMM) prior. The prior defines a clustering in the latent space, where the clusters are associated with specific drug properties. In addition, VADEERS is equipped with a cell line autoencoder and a sensitivity prediction network. The model combines data for SMILES string representations of anti-cancer drugs, their inhibition profiles against a panel of protein kinases, cell lines biological features and measurements of the sensitivity of the cell lines to the drugs. The evaluated variants of VADEERS achieve a high r=0.87 Pearson correlation between true and predicted drug sensitivity estimates. We train the GMM prior in such a way that the clusters in the latent space correspond to a pre-computed clustering of the drugs by their inhibitory profiles. We show that the learned latent representations and new generated data points accurately reflect the given clustering. In summary, VADEERS offers a comprehensive model of drugs and cell lines properties and relationships between them, as well as a guided generation of novel compounds.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020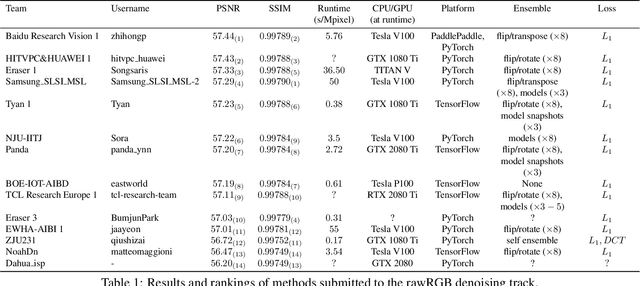
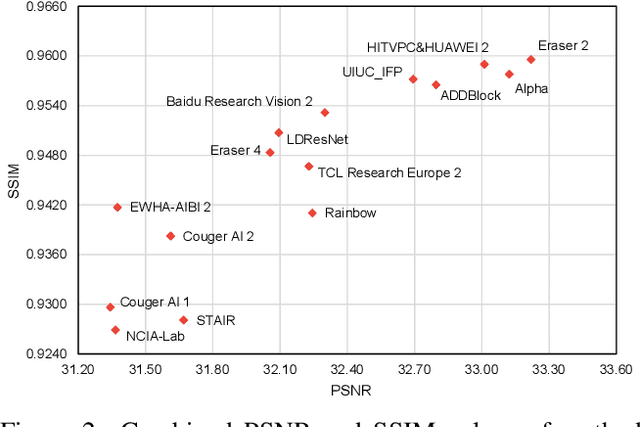
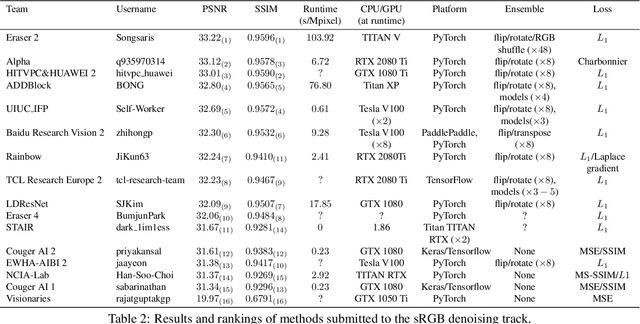
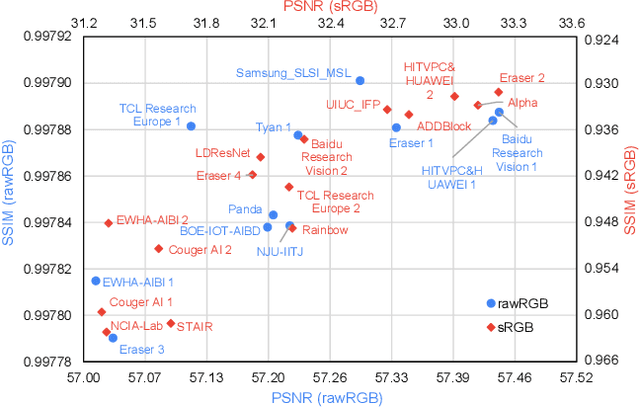
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Superkernel Neural Architecture Search for Image Denoising
Apr 19, 2020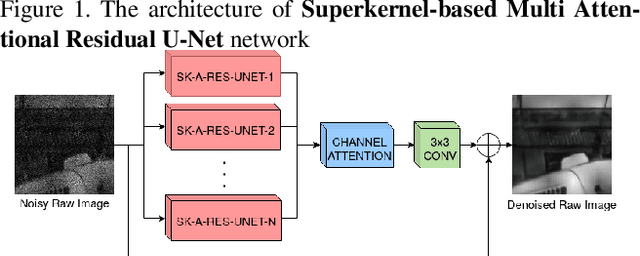
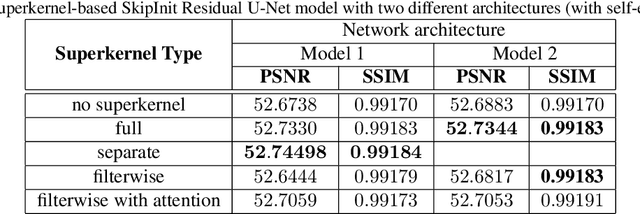
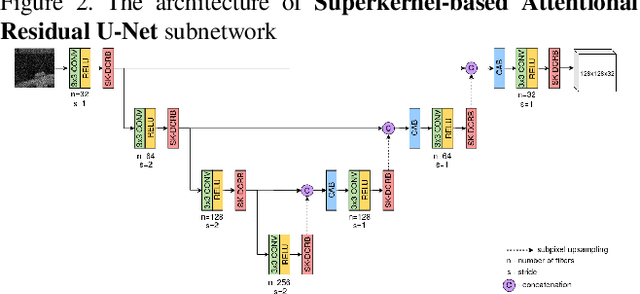
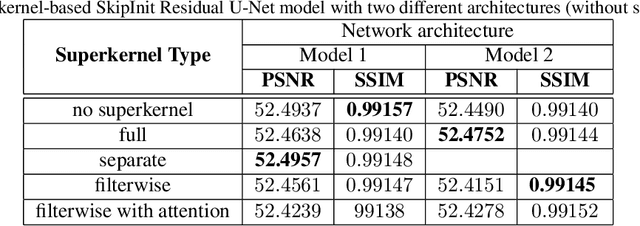
Recent advancements in Neural Architecture Search(NAS) resulted in finding new state-of-the-art Artificial Neural Network (ANN) solutions for tasks like image classification, object detection, or semantic segmentation without substantial human supervision. In this paper, we focus on exploring NAS for a dense prediction task that is image denoising. Due to a costly training procedure, most NAS solutions for image enhancement rely on reinforcement learning or evolutionary algorithm exploration, which usually take weeks (or even months) to train. Therefore, we introduce a new efficient implementation of various superkernel techniques that enable fast (6-8 RTX2080 GPU hours) single-shot training of models for dense predictions. We demonstrate the effectiveness of our method on the SIDD+ benchmark for image denoising.
Exploiting Unsupervised Pre-training and Automated Feature Engineering for Low-resource Hate Speech Detection in Polish
Jun 17, 2019

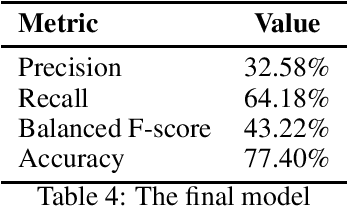
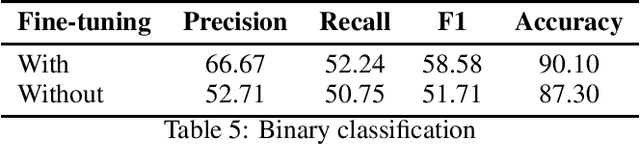
This paper presents our contribution to PolEval 2019 Task 6: Hate speech and bullying detection. We describe three parallel approaches that we followed: fine-tuning a pre-trained ULMFiT model to our classification task, fine-tuning a pre-trained BERT model to our classification task, and using the TPOT library to find the optimal pipeline. We present results achieved by these three tools and review their advantages and disadvantages in terms of user experience. Our team placed second in subtask 2 with a shallow model found by TPOT: a~logistic regression classifier with non-trivial feature engineering.
* http://poleval.pl/publication
Investigating performance of neural networks and gradient boosting models approximating microscopic traffic simulations in traffic optimization tasks
Dec 11, 2018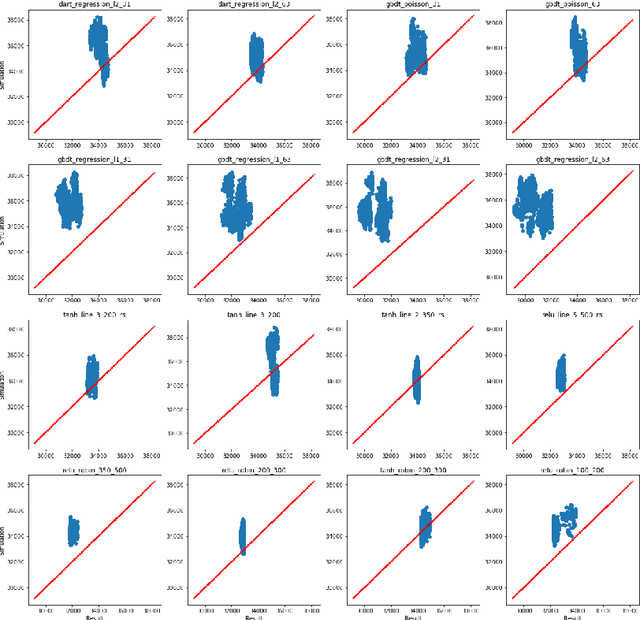
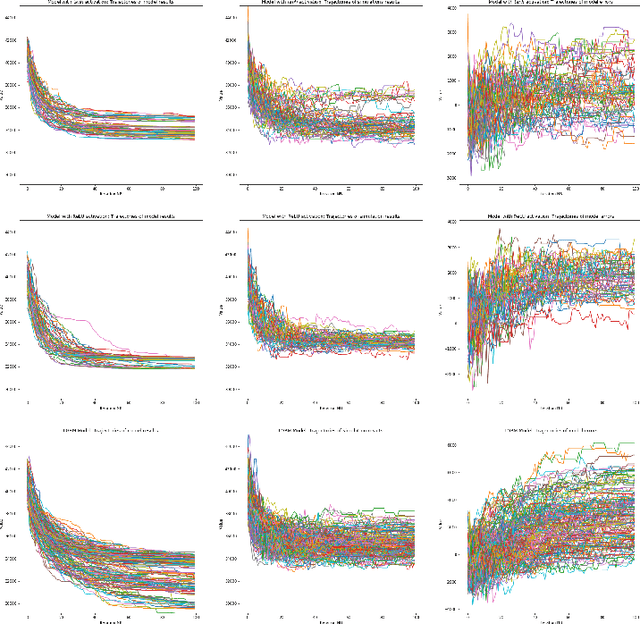
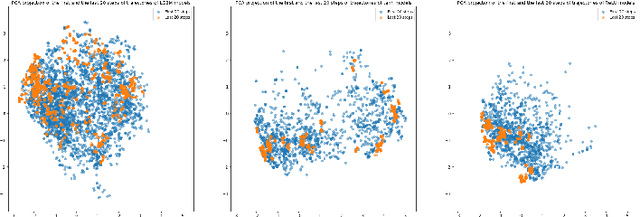
We analyze the accuracy of traffic simulations metamodels based on neural networks and gradient boosting models (LightGBM), applied to traffic optimization as fitness functions of genetic algorithms. Our metamodels approximate outcomes of traffic simulations (the total time of waiting on a red signal) taking as an input different traffic signal settings, in order to efficiently find (sub)optimal settings. Their accuracy was proven to be very good on randomly selected test sets, but it turned out that the accuracy may drop in case of settings expected (according to genetic algorithms) to be close to local optima, which makes the traffic optimization process more difficult. In this work, we investigate 16 different metamodels and 20 settings of genetic algorithms, in order to understand what are the reasons of this phenomenon, what is its scale, how it can be mitigated and what can be potentially done to design better real-time traffic optimization methods.
Inhibited Softmax for Uncertainty Estimation in Neural Networks
Oct 03, 2018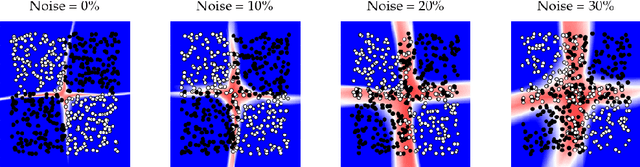

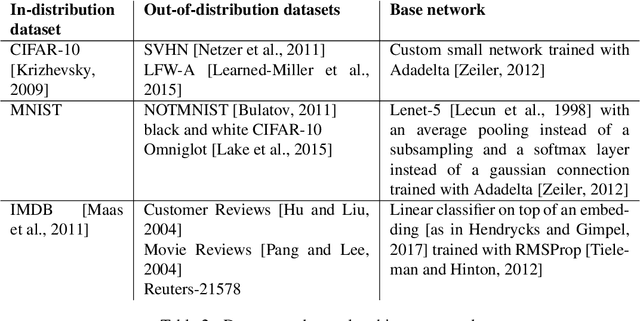
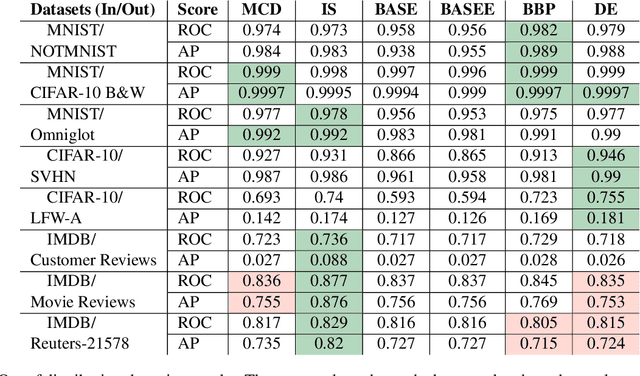
We present a new method for uncertainty estimation and out-of-distribution detection in neural networks with softmax output. We extend softmax layer with an additional constant input. The corresponding additional output is able to represent the uncertainty of the network. The proposed method requires neither additional parameters nor multiple forward passes nor input preprocessing nor out-of-distribution datasets. We show that our method performs comparably to more computationally expensive methods and outperforms baselines on our experiments from image recognition and sentiment analysis domains.