 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Image Authenticity When Cameras Use Generative AI
Apr 23, 2026The ability of generative AI (GenAI) methods to photorealistically alter camera images has raised awareness about the authenticity of images shared online. Interestingly, images captured directly by our cameras are considered authentic and faithful. However, with the increasing integration of deep-learning modules into cameras' capture-time hardware -- namely, the image signal processor (ISP) -- there is now a potential for hallucinated content in images directly output by our cameras. Hallucinated capture-time image content is typically benign, such as enhanced edges or texture, but in certain operations, such as AI-based digital zoom or low-light image enhancement, hallucinations can potentially alter the semantics and interpretation of the image content. As a result, users may not realize that the content in their camera images is not authentic. This paper addresses this issue by enabling users to recover the 'unhallucinated' version of the camera image to avoid misinterpretation of the image content. Our approach works by optimizing an image-specific multi-layer perceptron (MLP) decoder together with a modality-specific encoder so that, given the camera image, we can recover the image before hallucinated content was added. The encoder and MLP are self-contained and can be applied post-capture to the image without requiring access to the camera ISP. Moreover, the encoder and MLP decoder require only 180 KB of storage and can be readily saved as metadata within standard image formats such as JPEG and HEIC.
RawGen: Learning Camera Raw Image Generation
Mar 31, 2026Cameras capture scene-referred linear raw images, which are processed by onboard image signal processors (ISPs) into display-referred 8-bit sRGB outputs. Although raw data is more faithful for low-level vision tasks, collecting large-scale raw datasets remains a major bottleneck, as existing datasets are limited and tied to specific camera hardware. Generative models offer a promising way to address this scarcity -- however, existing diffusion frameworks are designed to synthesize photo-finished sRGB images rather than physically consistent linear representations. This paper presents RawGen, to our knowledge the first diffusion-based framework enabling text-to-raw generation for arbitrary target cameras, alongside sRGB-to-raw inversion. RawGen leverages the generative priors of large-scale sRGB diffusion models to synthesize physically meaningful linear outputs, such as CIE XYZ or camera-specific raw representations, via specialized processing in latent and pixel spaces. To handle unknown and diverse ISP pipelines and photo-finishing effects in diffusion-model training data, we build a many-to-one inverse-ISP dataset where multiple sRGB renditions of the same scene generated using diverse ISP parameters are anchored to a common scene-referred target. Fine-tuning a conditional denoiser and specialized decoder on this dataset allows RawGen to obtain camera-centric linear reconstructions that effectively invert the rendering pipeline. We demonstrate RawGen's superior performance over traditional inverse-ISP methods that assume a fixed ISP. Furthermore, we show that augmenting training pipelines with RawGen's scalable, text-driven synthetic data can benefit downstream low-level vision tasks.
Underwater imaging without color distortions requires RAW capture
Mar 21, 2026Consumer cameras are ubiquitous in aquatic sciences because they are affordable and easy to use, generating vast collections of underwater imagery for ecosystem surveys, monitoring, mapping, and animal behavior studies. Yet when color is the variable of interest, such as in coral-bleaching research, most of these images cannot be used quantitatively if captured in JPEG format. The limitation is not due to JPEG compression itself, but to the in-camera processing that precedes it: as cameras produce these images, built-in algorithms modify colors and contrast not to ensure color accuracy but to produce visually pleasing pictures. These irreversible in-camera operations break the linear relationship between pixel values and scene radiance, making colors impossible to standardize, reproduce, or compare across cameras, locations, or time. This essay explains the scientific costs of this practice and offers pragmatic guidance to prevent irreversible data loss, beginning with the capture and archiving of minimally processed RAW images.
RAW-Domain Degradation Models for Realistic Smartphone Super-Resolution
Mar 12, 2026Digital zoom on smartphones relies on learning-based super-resolution (SR) models that operate on RAW sensor images, but obtaining sensor-specific training data is challenging due to the lack of ground-truth images. Synthetic data generation via ``unprocessing'' pipelines offers a potential solution by simulating the degradations that transform high-resolution (HR) images into their low-resolution (LR) counterparts. However, these pipelines can introduce domain gaps due to incomplete or unrealistic degradation modeling. In this paper, we demonstrate that principled and carefully designed degradation modeling can enhance SR performance in real-world conditions. Instead of relying on generic priors for camera blur and noise, we model device-specific degradations through calibration and unprocess publicly available rendered images into the RAW domain of different smartphones. Using these image pairs, we train a single-image RAW-to-RGB SR model and evaluate it on real data from a held-out device. Our experiments show that accurate degradation modeling leads to noticeable improvements, with our SR model outperforming baselines trained on large pools of arbitrarily chosen degradations.
Generating the Past, Present and Future from a Motion-Blurred Image
Dec 22, 2025We seek to answer the question: what can a motion-blurred image reveal about a scene's past, present, and future? Although motion blur obscures image details and degrades visual quality, it also encodes information about scene and camera motion during an exposure. Previous techniques leverage this information to estimate a sharp image from an input blurry one, or to predict a sequence of video frames showing what might have occurred at the moment of image capture. However, they rely on handcrafted priors or network architectures to resolve ambiguities in this inverse problem, and do not incorporate image and video priors on large-scale datasets. As such, existing methods struggle to reproduce complex scene dynamics and do not attempt to recover what occurred before or after an image was taken. Here, we introduce a new technique that repurposes a pre-trained video diffusion model trained on internet-scale datasets to recover videos revealing complex scene dynamics during the moment of capture and what might have occurred immediately into the past or future. Our approach is robust and versatile; it outperforms previous methods for this task, generalizes to challenging in-the-wild images, and supports downstream tasks such as recovering camera trajectories, object motion, and dynamic 3D scene structure. Code and data are available at https://blur2vid.github.io
* Code and data are available at https://blur2vid.github.io
Modular Neural Image Signal Processing
Dec 09, 2025
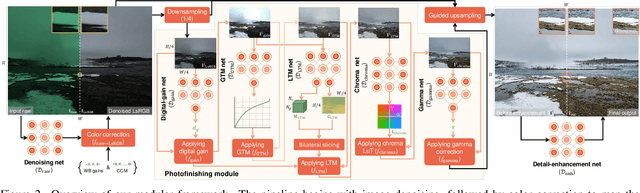
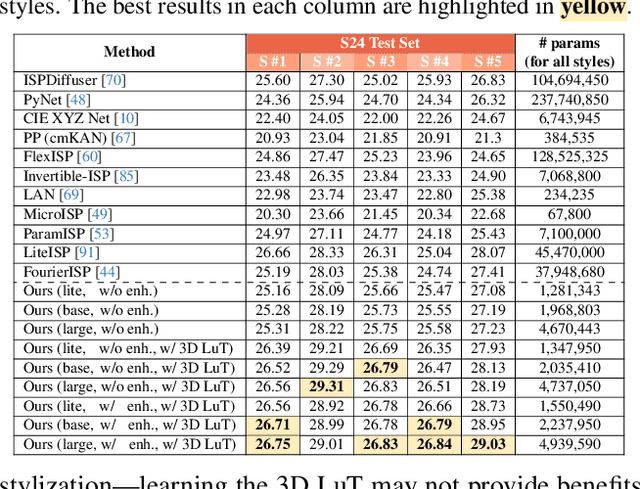
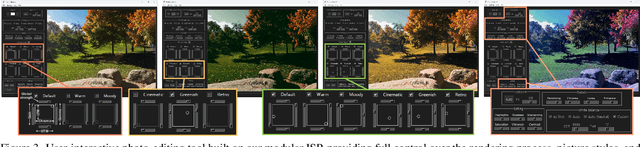
This paper presents a modular neural image signal processing (ISP) framework that processes raw inputs and renders high-quality display-referred images. Unlike prior neural ISP designs, our method introduces a high degree of modularity, providing full control over multiple intermediate stages of the rendering process.~This modular design not only achieves high rendering accuracy but also improves scalability, debuggability, generalization to unseen cameras, and flexibility to match different user-preference styles. To demonstrate the advantages of this design, we built a user-interactive photo-editing tool that leverages our neural ISP to support diverse editing operations and picture styles. The tool is carefully engineered to take advantage of the high-quality rendering of our neural ISP and to enable unlimited post-editable re-rendering. Our method is a fully learning-based framework with variants of different capacities, all of moderate size (ranging from ~0.5 M to ~3.9 M parameters for the entire pipeline), and consistently delivers competitive qualitative and quantitative results across multiple test sets. Watch the supplemental video at: https://youtu.be/ByhQjQSjxVM
Evaluating Low-Light Image Enhancement Across Multiple Intensity Levels
Nov 19, 2025Imaging in low-light environments is challenging due to reduced scene radiance, which leads to elevated sensor noise and reduced color saturation. Most learning-based low-light enhancement methods rely on paired training data captured under a single low-light condition and a well-lit reference. The lack of radiance diversity limits our understanding of how enhancement techniques perform across varying illumination intensities. We introduce the Multi-Illumination Low-Light (MILL) dataset, containing images captured at diverse light intensities under controlled conditions with fixed camera settings and precise illuminance measurements. MILL enables comprehensive evaluation of enhancement algorithms across variable lighting conditions. We benchmark several state-of-the-art methods and reveal significant performance variations across intensity levels. Leveraging the unique multi-illumination structure of our dataset, we propose improvements that enhance robustness across diverse illumination scenarios. Our modifications achieve up to 10 dB PSNR improvement for DSLR and 2 dB for the smartphone on Full HD images.
Improved Mapping Between Illuminations and Sensors for RAW Images
Aug 20, 2025RAW images are unprocessed camera sensor output with sensor-specific RGB values based on the sensor's color filter spectral sensitivities. RAW images also incur strong color casts due to the sensor's response to the spectral properties of scene illumination. The sensor- and illumination-specific nature of RAW images makes it challenging to capture RAW datasets for deep learning methods, as scenes need to be captured for each sensor and under a wide range of illumination. Methods for illumination augmentation for a given sensor and the ability to map RAW images between sensors are important for reducing the burden of data capture. To explore this problem, we introduce the first-of-its-kind dataset comprising carefully captured scenes under a wide range of illumination. Specifically, we use a customized lightbox with tunable illumination spectra to capture several scenes with different cameras. Our illumination and sensor mapping dataset has 390 illuminations, four cameras, and 18 scenes. Using this dataset, we introduce a lightweight neural network approach for illumination and sensor mapping that outperforms competing methods. We demonstrate the utility of our approach on the downstream task of training a neural ISP. Link to project page: https://github.com/SamsungLabs/illum-sensor-mapping.
Spectral Sensitivity Estimation with an Uncalibrated Diffraction Grating
Aug 01, 2025This paper introduces a practical and accurate calibration method for camera spectral sensitivity using a diffraction grating. Accurate calibration of camera spectral sensitivity is crucial for various computer vision tasks, including color correction, illumination estimation, and material analysis. Unlike existing approaches that require specialized narrow-band filters or reference targets with known spectral reflectances, our method only requires an uncalibrated diffraction grating sheet, readily available off-the-shelf. By capturing images of the direct illumination and its diffracted pattern through the grating sheet, our method estimates both the camera spectral sensitivity and the diffraction grating parameters in a closed-form manner. Experiments on synthetic and real-world data demonstrate that our method outperforms conventional reference target-based methods, underscoring its effectiveness and practicality.
Learning Camera-Agnostic White-Balance Preferences
Jul 02, 2025The image signal processor (ISP) pipeline in modern cameras consists of several modules that transform raw sensor data into visually pleasing images in a display color space. Among these, the auto white balance (AWB) module is essential for compensating for scene illumination. However, commercial AWB systems often strive to compute aesthetic white-balance preferences rather than accurate neutral color correction. While learning-based methods have improved AWB accuracy, they typically struggle to generalize across different camera sensors -- an issue for smartphones with multiple cameras. Recent work has explored cross-camera AWB, but most methods remain focused on achieving neutral white balance. In contrast, this paper is the first to address aesthetic consistency by learning a post-illuminant-estimation mapping that transforms neutral illuminant corrections into aesthetically preferred corrections in a camera-agnostic space. Once trained, our mapping can be applied after any neutral AWB module to enable consistent and stylized color rendering across unseen cameras. Our proposed model is lightweight -- containing only $\sim$500 parameters -- and runs in just 0.024 milliseconds on a typical flagship mobile CPU. Evaluated on a dataset of 771 smartphone images from three different cameras, our method achieves state-of-the-art performance while remaining fully compatible with existing cross-camera AWB techniques, introducing minimal computational and memory overhead.