 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyncLight: Controllable and Consistent Multi-View Relighting
Jan 23, 2026We present SyncLight, the first method to enable consistent, parametric relighting across multiple uncalibrated views of a static scene. While single-view relighting has advanced significantly, existing generative approaches struggle to maintain the rigorous lighting consistency essential for multi-camera broadcasts, stereoscopic cinema, and virtual production. SyncLight addresses this by enabling precise control over light intensity and color across a multi-view capture of a scene, conditioned on a single reference edit. Our method leverages a multi-view diffusion transformer trained using a latent bridge matching formulation, achieving high-fidelity relighting of the entire image set in a single inference step. To facilitate training, we introduce a large-scale hybrid dataset comprising diverse synthetic environments -- curated from existing sources and newly designed scenes -- alongside high-fidelity, real-world multi-view captures under calibrated illumination. Surprisingly, though trained only on image pairs, SyncLight generalizes zero-shot to an arbitrary number of viewpoints, effectively propagating lighting changes across all views, without requiring camera pose information. SyncLight enables practical relighting workflows for multi-view capture systems.
Evaluating Low-Light Image Enhancement Across Multiple Intensity Levels
Nov 19, 2025Imaging in low-light environments is challenging due to reduced scene radiance, which leads to elevated sensor noise and reduced color saturation. Most learning-based low-light enhancement methods rely on paired training data captured under a single low-light condition and a well-lit reference. The lack of radiance diversity limits our understanding of how enhancement techniques perform across varying illumination intensities. We introduce the Multi-Illumination Low-Light (MILL) dataset, containing images captured at diverse light intensities under controlled conditions with fixed camera settings and precise illuminance measurements. MILL enables comprehensive evaluation of enhancement algorithms across variable lighting conditions. We benchmark several state-of-the-art methods and reveal significant performance variations across intensity levels. Leveraging the unique multi-illumination structure of our dataset, we propose improvements that enhance robustness across diverse illumination scenarios. Our modifications achieve up to 10 dB PSNR improvement for DSLR and 2 dB for the smartphone on Full HD images.
Revisiting Image Fusion for Multi-Illuminant White-Balance Correction
Mar 18, 2025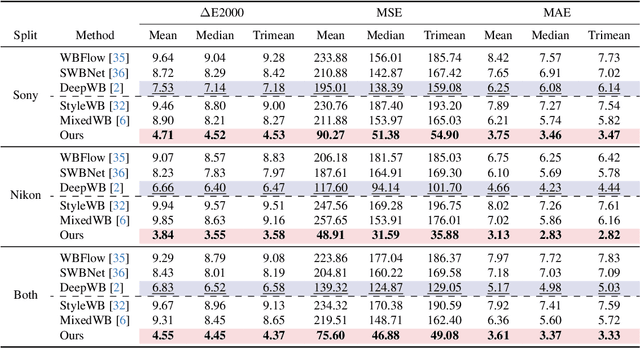

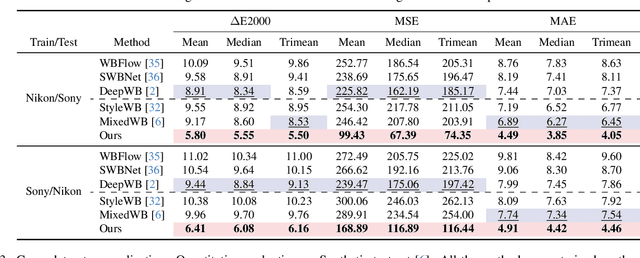
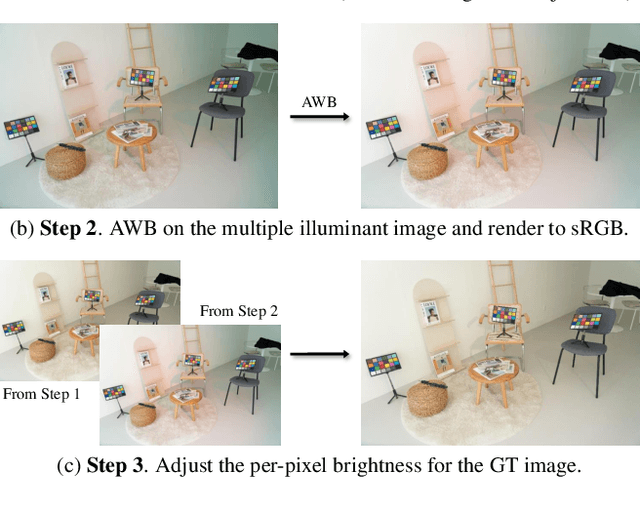
White balance (WB) correction in scenes with multiple illuminants remains a persistent challenge in computer vision. Recent methods explored fusion-based approaches, where a neural network linearly blends multiple sRGB versions of an input image, each processed with predefined WB presets. However, we demonstrate that these methods are suboptimal for common multi-illuminant scenarios. Additionally, existing fusion-based methods rely on sRGB WB datasets lacking dedicated multi-illuminant images, limiting both training and evaluation. To address these challenges, we introduce two key contributions. First, we propose an efficient transformer-based model that effectively captures spatial dependencies across sRGB WB presets, substantially improving upon linear fusion techniques. Second, we introduce a large-scale multi-illuminant dataset comprising over 16,000 sRGB images rendered with five different WB settings, along with WB-corrected images. Our method achieves up to 100\% improvement over existing techniques on our new multi-illuminant image fusion dataset.
Rethinking Image Evaluation in Super-Resolution
Mar 17, 2025While recent advancing image super-resolution (SR) techniques are continually improving the perceptual quality of their outputs, they can usually fail in quantitative evaluations. This inconsistency leads to a growing distrust in existing image metrics for SR evaluations. Though image evaluation depends on both the metric and the reference ground truth (GT), researchers typically do not inspect the role of GTs, as they are generally accepted as `perfect' references. However, due to the data being collected in the early years and the ignorance of controlling other types of distortions, we point out that GTs in existing SR datasets can exhibit relatively poor quality, which leads to biased evaluations. Following this observation, in this paper, we are interested in the following questions: Are GT images in existing SR datasets 100\% trustworthy for model evaluations? How does GT quality affect this evaluation? And how to make fair evaluations if there exist imperfect GTs? To answer these questions, this paper presents two main contributions. First, by systematically analyzing seven state-of-the-art SR models across three real-world SR datasets, we show that SR performances can be consistently affected across models by low-quality GTs, and models can perform quite differently when GT quality is controlled. Second, we propose a novel perceptual quality metric, Relative Quality Index (RQI), that measures the relative quality discrepancy of image pairs, thus issuing the biased evaluations caused by unreliable GTs. Our proposed model achieves significantly better consistency with human opinions. We expect our work to provide insights for the SR community on how future datasets, models, and metrics should be developed.
Adaptive Blind All-in-One Image Restoration
Nov 27, 2024Blind all-in-one image restoration models aim to recover a high-quality image from an input degraded with unknown distortions. However, these models require all the possible degradation types to be defined during the training stage while showing limited generalization to unseen degradations, which limits their practical application in complex cases. In this paper, we propose a simple but effective adaptive blind all-in-one restoration (ABAIR) model, which can address multiple degradations, generalizes well to unseen degradations, and efficiently incorporate new degradations by training a small fraction of parameters. First, we train our baseline model on a large dataset of natural images with multiple synthetic degradations, augmented with a segmentation head to estimate per-pixel degradation types, resulting in a powerful backbone able to generalize to a wide range of degradations. Second, we adapt our baseline model to varying image restoration tasks using independent low-rank adapters. Third, we learn to adaptively combine adapters to versatile images via a flexible and lightweight degradation estimator. Our model is both powerful in handling specific distortions and flexible in adapting to complex tasks, it not only outperforms the state-of-the-art by a large margin on five- and three-task IR setups, but also shows improved generalization to unseen degradations and also composite distortions.
NamedCurves: Learned Image Enhancement via Color Naming
Jul 13, 2024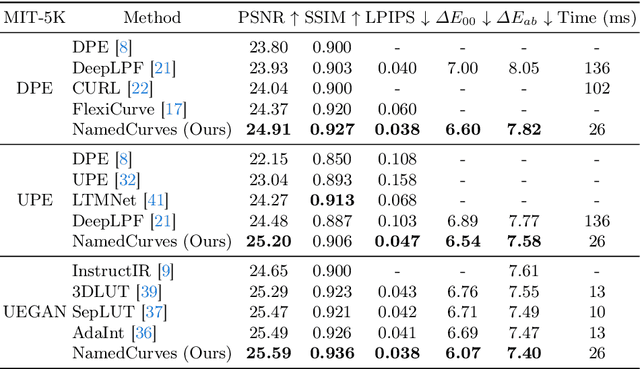



A popular method for enhancing images involves learning the style of a professional photo editor using pairs of training images comprised of the original input with the editor-enhanced version. When manipulating images, many editing tools offer a feature that allows the user to manipulate a limited selection of familiar colors. Editing by color name allows easy adjustment of elements like the "blue" of the sky or the "green" of trees. Inspired by this approach to color manipulation, we propose NamedCurves, a learning-based image enhancement technique that separates the image into a small set of named colors. Our method learns to globally adjust the image for each specific named color via tone curves and then combines the images using an attention-based fusion mechanism to mimic spatial editing. We demonstrate the effectiveness of our method against several competing methods on the well-known Adobe 5K dataset and the PPR10K dataset, showing notable improvements.