 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperNVD: Accelerating Neural Video Decomposition via Hypernetworks
Mar 21, 2025



Decomposing a video into a layer-based representation is crucial for easy video editing for the creative industries, as it enables independent editing of specific layers. Existing video-layer decomposition models rely on implicit neural representations (INRs) trained independently for each video, making the process time-consuming when applied to new videos. Noticing this limitation, we propose a meta-learning strategy to learn a generic video decomposition model to speed up the training on new videos. Our model is based on a hypernetwork architecture which, given a video-encoder embedding, generates the parameters for a compact INR-based neural video decomposition model. Our strategy mitigates the problem of single-video overfitting and, importantly, shortens the convergence of video decomposition on new, unseen videos. Our code is available at: https://hypernvd.github.io/
Rethinking Image Evaluation in Super-Resolution
Mar 17, 2025While recent advancing image super-resolution (SR) techniques are continually improving the perceptual quality of their outputs, they can usually fail in quantitative evaluations. This inconsistency leads to a growing distrust in existing image metrics for SR evaluations. Though image evaluation depends on both the metric and the reference ground truth (GT), researchers typically do not inspect the role of GTs, as they are generally accepted as `perfect' references. However, due to the data being collected in the early years and the ignorance of controlling other types of distortions, we point out that GTs in existing SR datasets can exhibit relatively poor quality, which leads to biased evaluations. Following this observation, in this paper, we are interested in the following questions: Are GT images in existing SR datasets 100\% trustworthy for model evaluations? How does GT quality affect this evaluation? And how to make fair evaluations if there exist imperfect GTs? To answer these questions, this paper presents two main contributions. First, by systematically analyzing seven state-of-the-art SR models across three real-world SR datasets, we show that SR performances can be consistently affected across models by low-quality GTs, and models can perform quite differently when GT quality is controlled. Second, we propose a novel perceptual quality metric, Relative Quality Index (RQI), that measures the relative quality discrepancy of image pairs, thus issuing the biased evaluations caused by unreliable GTs. Our proposed model achieves significantly better consistency with human opinions. We expect our work to provide insights for the SR community on how future datasets, models, and metrics should be developed.
Bit-depth color recovery via off-the-shelf super-resolution models
Jan 09, 2025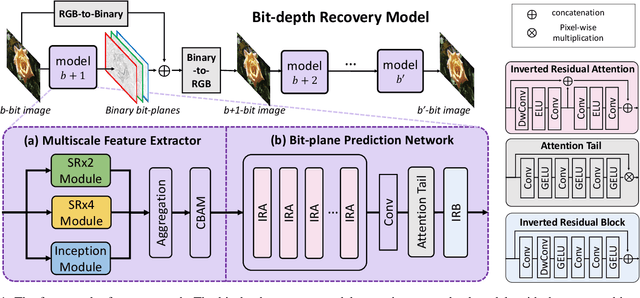

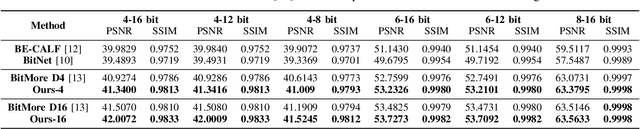
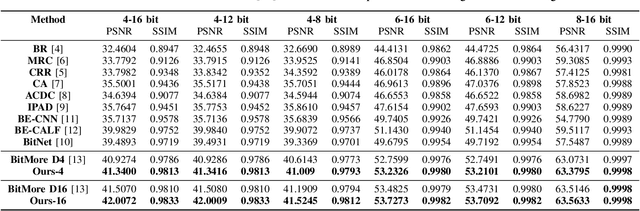
Advancements in imaging technology have enabled hardware to support 10 to 16 bits per channel, facilitating precise manipulation in applications like image editing and video processing. While deep neural networks promise to recover high bit-depth representations, existing methods often rely on scale-invariant image information, limiting performance in certain scenarios. In this paper, we introduce a novel approach that integrates a super-resolution architecture to extract detailed a priori information from images. By leveraging interpolated data generated during the super-resolution process, our method achieves pixel-level recovery of fine-grained color details. Additionally, we demonstrate that spatial features learned through the super-resolution process significantly contribute to the recovery of detailed color depth information. Experiments on benchmark datasets demonstrate that our approach outperforms state-of-the-art methods, highlighting the potential of super-resolution for high-fidelity color restoration.
Take a Prior from Other Tasks for Severe Blur Removal
Feb 14, 2023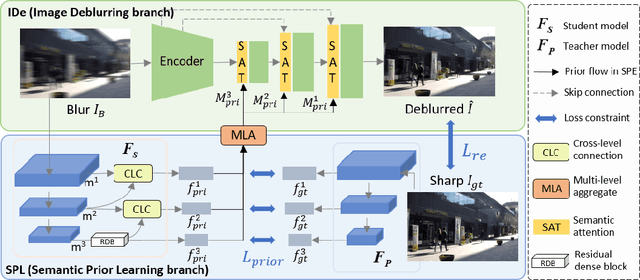
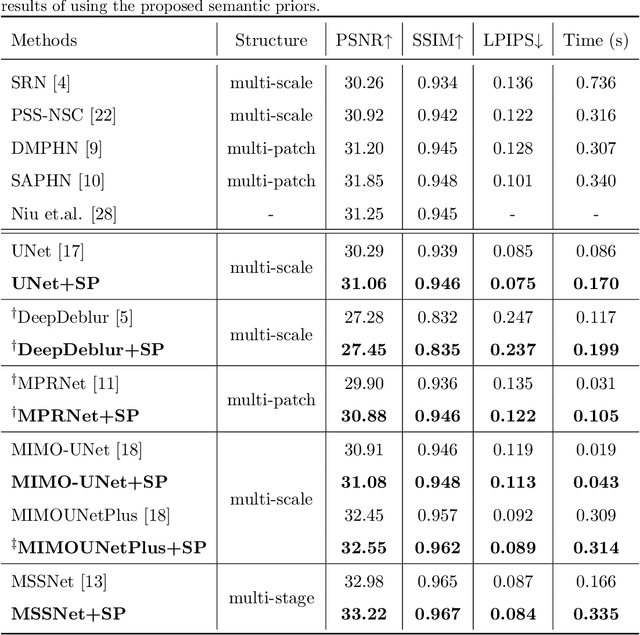
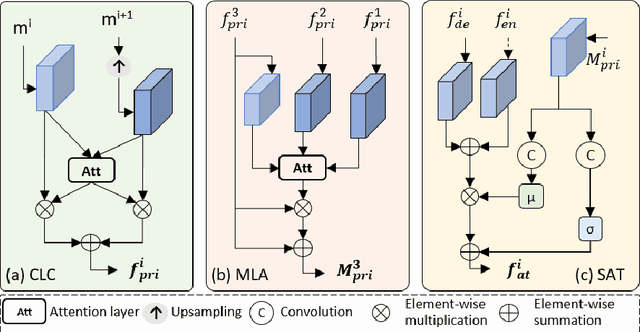
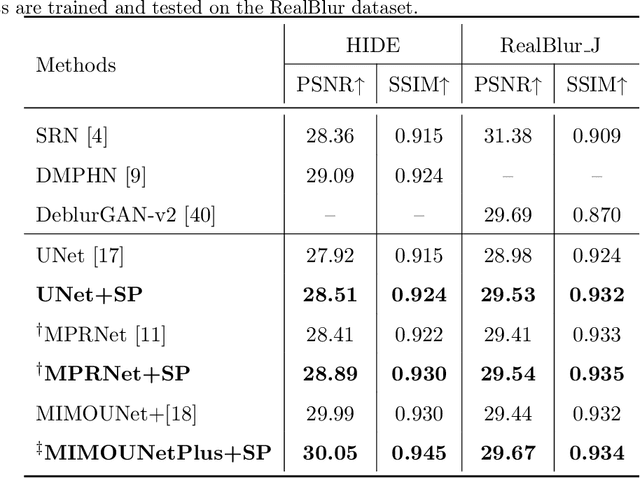
Recovering clear structures from severely blurry inputs is a challenging problem due to the large movements between the camera and the scene. Although some works apply segmentation maps on human face images for deblurring, they cannot handle natural scenes because objects and degradation are more complex, and inaccurate segmentation maps lead to a loss of details. For general scene deblurring, the feature space of the blurry image and corresponding sharp image under the high-level vision task is closer, which inspires us to rely on other tasks (e.g. classification) to learn a comprehensive prior in severe blur removal cases. We propose a cross-level feature learning strategy based on knowledge distillation to learn the priors, which include global contexts and sharp local structures for recovering potential details. In addition, we propose a semantic prior embedding layer with multi-level aggregation and semantic attention transformation to integrate the priors effectively. We introduce the proposed priors to various models, including the UNet and other mainstream deblurring baselines, leading to better performance on severe blur removal. Extensive experiments on natural image deblurring benchmarks and real-world images, such as GoPro and RealBlur datasets, demonstrate our method's effectiveness and generalization ability.
SlimSeg: Slimmable Semantic Segmentation with Boundary Supervision
Jul 13, 2022
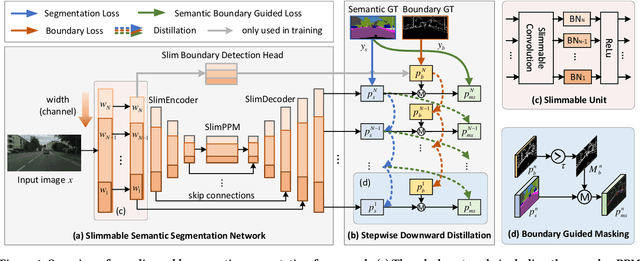

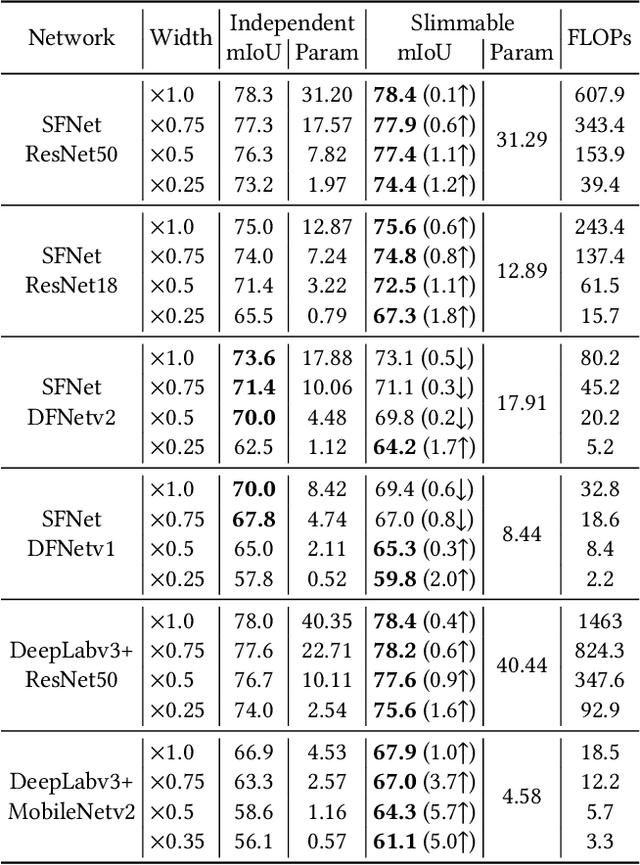
Accurate semantic segmentation models typically require significant computational resources, inhibiting their use in practical applications. Recent works rely on well-crafted lightweight models to achieve fast inference. However, these models cannot flexibly adapt to varying accuracy and efficiency requirements. In this paper, we propose a simple but effective slimmable semantic segmentation (SlimSeg) method, which can be executed at different capacities during inference depending on the desired accuracy-efficiency tradeoff. More specifically, we employ parametrized channel slimming by stepwise downward knowledge distillation during training. Motivated by the observation that the differences between segmentation results of each submodel are mainly near the semantic borders, we introduce an additional boundary guided semantic segmentation loss to further improve the performance of each submodel. We show that our proposed SlimSeg with various mainstream networks can produce flexible models that provide dynamic adjustment of computational cost and better performance than independent models. Extensive experiments on semantic segmentation benchmarks, Cityscapes and CamVid, demonstrate the generalization ability of our framework.
Learning Depth via Leveraging Semantics: Self-supervised Monocular Depth Estimation with Both Implicit and Explicit Semantic Guidance
Feb 11, 2021
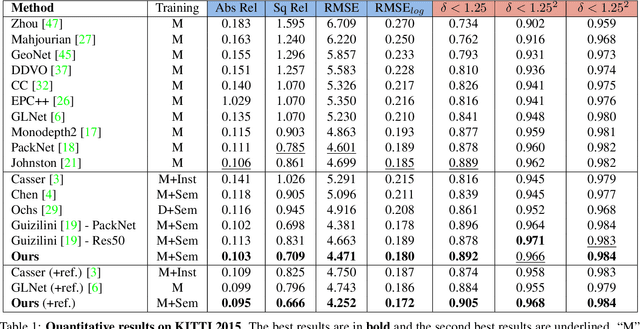
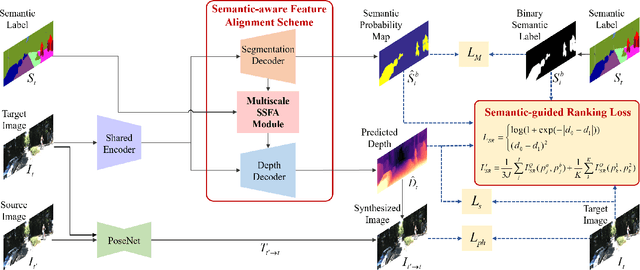

Self-supervised depth estimation has made a great success in learning depth from unlabeled image sequences. While the mappings between image and pixel-wise depth are well-studied in current methods, the correlation between image, depth and scene semantics, however, is less considered. This hinders the network to better understand the real geometry of the scene, since the contextual clues, contribute not only the latent representations of scene depth, but also the straight constraints for depth map. In this paper, we leverage the two benefits by proposing the implicit and explicit semantic guidance for accurate self-supervised depth estimation. We propose a Semantic-aware Spatial Feature Alignment (SSFA) scheme to effectively align implicit semantic features with depth features for scene-aware depth estimation. We also propose a semantic-guided ranking loss to explicitly constrain the estimated depth maps to be consistent with real scene contextual properties. Both semantic label noise and prediction uncertainty is considered to yield reliable depth supervisions. Extensive experimental results show that our method produces high quality depth maps which are consistently superior either on complex scenes or diverse semantic categories, and outperforms the state-of-the-art methods by a significant margin.