 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-free 3D Gaussian splatting via shape-ray estimation
May 29, 2025While generalizable 3D Gaussian splatting enables efficient, high-quality rendering of unseen scenes, it heavily depends on precise camera poses for accurate geometry. In real-world scenarios, obtaining accurate poses is challenging, leading to noisy pose estimates and geometric misalignments. To address this, we introduce SHARE, a pose-free, feed-forward Gaussian splatting framework that overcomes these ambiguities by joint shape and camera rays estimation. Instead of relying on explicit 3D transformations, SHARE builds a pose-aware canonical volume representation that seamlessly integrates multi-view information, reducing misalignment caused by inaccurate pose estimates. Additionally, anchor-aligned Gaussian prediction enhances scene reconstruction by refining local geometry around coarse anchors, allowing for more precise Gaussian placement. Extensive experiments on diverse real-world datasets show that our method achieves robust performance in pose-free generalizable Gaussian splatting.
AdvPaint: Protecting Images from Inpainting Manipulation via Adversarial Attention Disruption
Mar 13, 2025
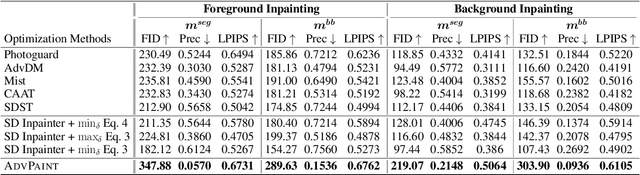
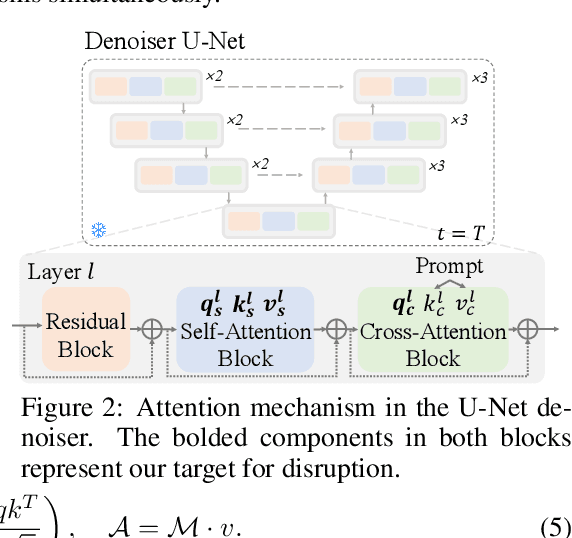

The outstanding capability of diffusion models in generating high-quality images poses significant threats when misused by adversaries. In particular, we assume malicious adversaries exploiting diffusion models for inpainting tasks, such as replacing a specific region with a celebrity. While existing methods for protecting images from manipulation in diffusion-based generative models have primarily focused on image-to-image and text-to-image tasks, the challenge of preventing unauthorized inpainting has been rarely addressed, often resulting in suboptimal protection performance. To mitigate inpainting abuses, we propose ADVPAINT, a novel defensive framework that generates adversarial perturbations that effectively disrupt the adversary's inpainting tasks. ADVPAINT targets the self- and cross-attention blocks in a target diffusion inpainting model to distract semantic understanding and prompt interactions during image generation. ADVPAINT also employs a two-stage perturbation strategy, dividing the perturbation region based on an enlarged bounding box around the object, enhancing robustness across diverse masks of varying shapes and sizes. Our experimental results demonstrate that ADVPAINT's perturbations are highly effective in disrupting the adversary's inpainting tasks, outperforming existing methods; ADVPAINT attains over a 100-point increase in FID and substantial decreases in precision.
UFORecon: Generalizable Sparse-View Surface Reconstruction from Arbitrary and UnFavOrable Sets
Mar 11, 2024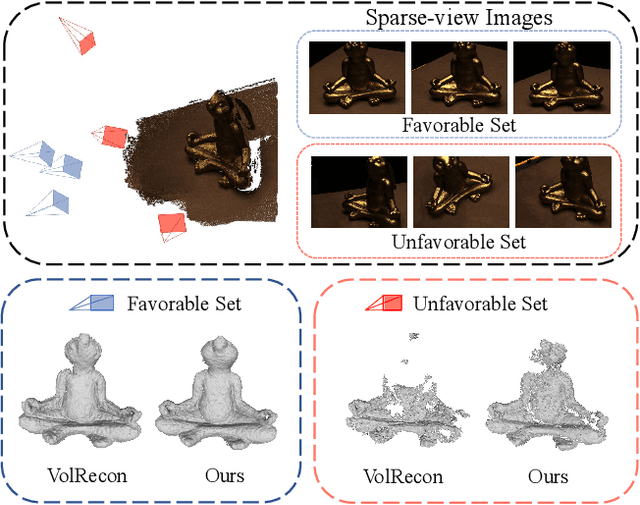
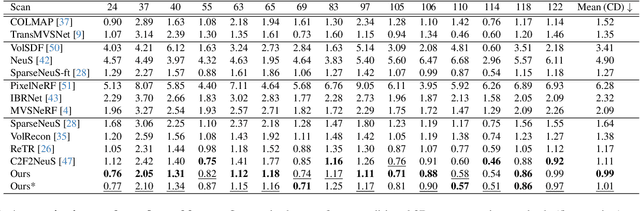
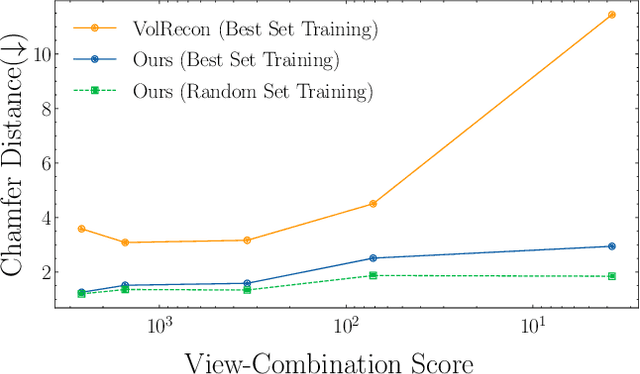

Generalizable neural implicit surface reconstruction aims to obtain an accurate underlying geometry given a limited number of multi-view images from unseen scenes. However, existing methods select only informative and relevant views using predefined scores for training and testing phases. This constraint renders the model impractical in real-world scenarios, where the availability of favorable combinations cannot always be ensured. We introduce and validate a view-combination score to indicate the effectiveness of the input view combination. We observe that previous methods output degenerate solutions under arbitrary and unfavorable sets. Building upon this finding, we propose UFORecon, a robust view-combination generalizable surface reconstruction framework. To achieve this, we apply cross-view matching transformers to model interactions between source images and build correlation frustums to capture global correlations. Additionally, we explicitly encode pairwise feature similarities as view-consistent priors. Our proposed framework significantly outperforms previous methods in terms of view-combination generalizability and also in the conventional generalizable protocol trained with favorable view-combinations. The code is available at https://github.com/Youngju-Na/UFORecon.
Take a Prior from Other Tasks for Severe Blur Removal
Feb 14, 2023Recovering clear structures from severely blurry inputs is a challenging problem due to the large movements between the camera and the scene. Although some works apply segmentation maps on human face images for deblurring, they cannot handle natural scenes because objects and degradation are more complex, and inaccurate segmentation maps lead to a loss of details. For general scene deblurring, the feature space of the blurry image and corresponding sharp image under the high-level vision task is closer, which inspires us to rely on other tasks (e.g. classification) to learn a comprehensive prior in severe blur removal cases. We propose a cross-level feature learning strategy based on knowledge distillation to learn the priors, which include global contexts and sharp local structures for recovering potential details. In addition, we propose a semantic prior embedding layer with multi-level aggregation and semantic attention transformation to integrate the priors effectively. We introduce the proposed priors to various models, including the UNet and other mainstream deblurring baselines, leading to better performance on severe blur removal. Extensive experiments on natural image deblurring benchmarks and real-world images, such as GoPro and RealBlur datasets, demonstrate our method's effectiveness and generalization ability.
A Method for Estimating Reflectance map and Material using Deep Learning with Synthetic Dataset
Jan 15, 2020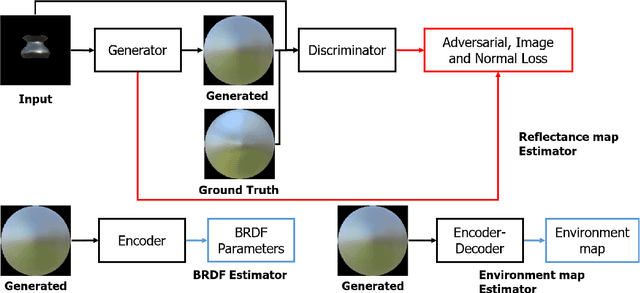
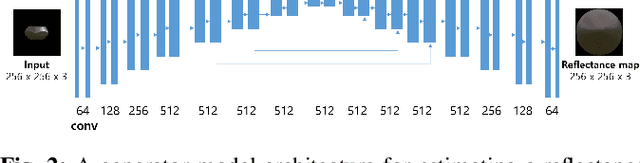
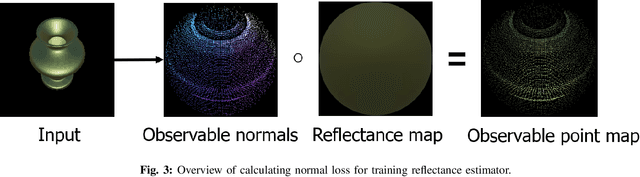
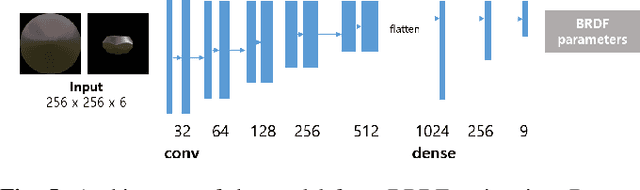
The process of decomposing target images into their internal properties is a difficult task due to the inherent ill-posed nature of the problem. The lack of data required to train a network is a one of the reasons why the decomposing appearance task is difficult. In this paper, we propose a deep learning-based reflectance map prediction system for material estimation of target objects in the image, so as to alleviate the ill-posed problem that occurs in this image decomposition operation. We also propose a network architecture for Bidirectional Reflectance Distribution Function (BRDF) parameter estimation, environment map estimation. We also use synthetic data to solve the lack of data problems. We get out of the previously proposed Deep Learning-based network architecture for reflectance map, and we newly propose to use conditional Generative Adversarial Network (cGAN) structures for estimating the reflectance map, which enables better results in many applications. To improve the efficiency of learning in this structure, we newly utilized the loss function using the normal map of the target object.
Virtual Piano using Computer Vision
Oct 28, 2019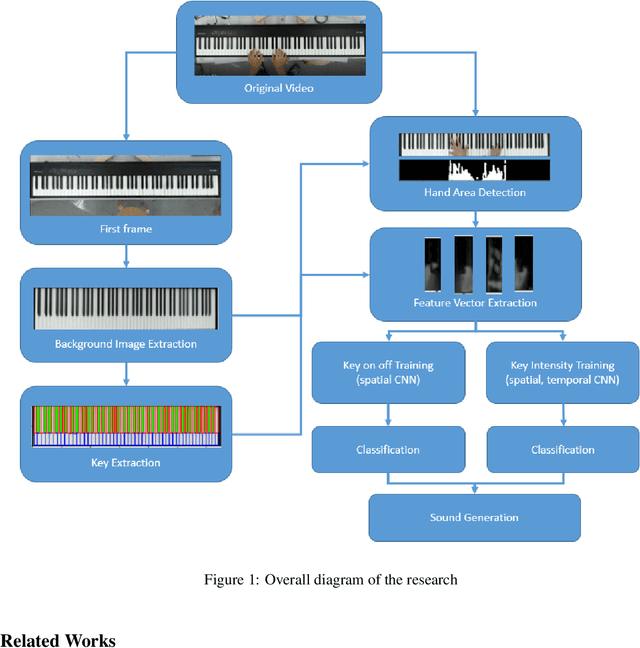



In this research, Piano performances have been analyzed only based on visual information. Computer vision algorithms, e.g., Hough transform and binary thresholding, have been applied to find where the keyboard and specific keys are located. At the same time, Convolutional Neural Networks(CNNs) has been also utilized to find whether specific keys are pressed or not, and how much intensity the keys are pressed only based on visual information. Especially for detecting intensity, a new method of utilizing spatial, temporal CNNs model is devised. Early fusion technique is especially applied in temporal CNNs architecture to analyze hand movement. We also make a new dataset for training each model. Especially when finding an intensity of a pressed key, both of video frames and their optical flow images are used to train models to find effectiveness.
Real-time 3-D Mapping with Estimating Acoustic Materials
Sep 16, 2019

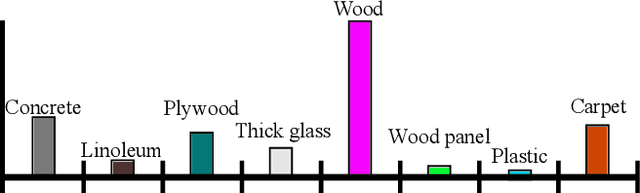

This paper proposes a real-time system integrating an acoustic material estimation from visual appearance and an on-the-fly mapping in the 3-dimension. The proposed method estimates the acoustic materials of surroundings in indoor scenes and incorporates them to a 3-D occupancy map, as a robot moves around the environment. To estimate the acoustic material from the visual cue, we apply the state-of-the-art semantic segmentation CNN network based on the assumption that the visual appearance and the acoustic materials have a strong association. Furthermore, we introduce an update policy to handle the material estimations during the online mapping process. As a result, our environment map with acoustic material can be used for sound-related robotics applications, such as sound source localization taking into account various acoustic propagation (e.g., reflection).
An Objectness Score for Accurate and Fast Detection during Navigation
Aug 26, 2019

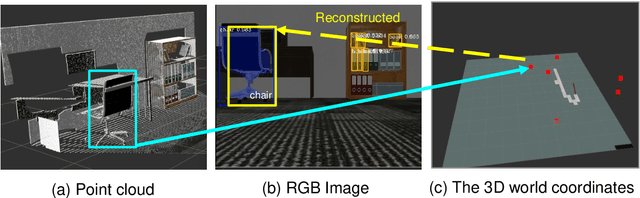

We propose a novel method utilizing an objectness score for maintaining the locations and classes of objects detected from Mask R-CNN during mobile robot navigation. The objectness score is defined to measure how well the detector identifies the locations and classes of objects during navigation. Specifically, it is designed to increase when there is sufficient distance between a detected object and the camera. During the navigation process, we transform the locations of objects in 3D world coordinates into 2D image coordinates through an affine projection and decide whether to retain the classes of detected objects using the objectness score. We conducted experiments to determine how well the locations and classes of detected objects are maintained at various angles and positions. Experimental results showed that our approach is efficient and robust, regardless of changing angles and distances.
Learning Embedding of 3D models with Quadric Loss
Jul 24, 2019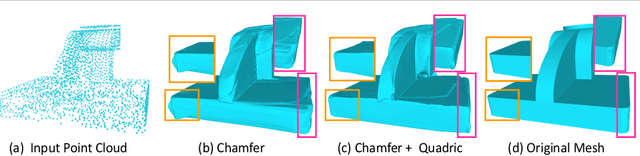
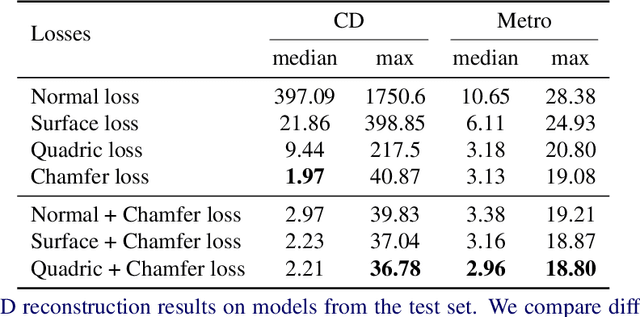
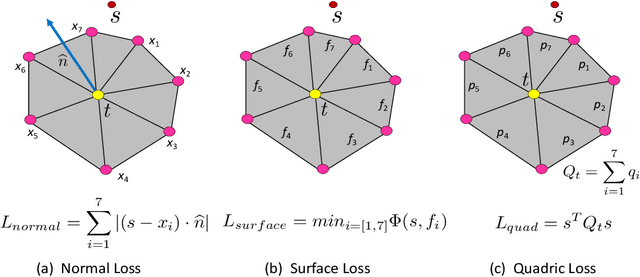
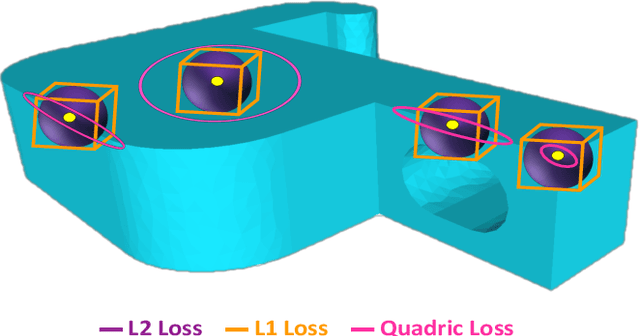
Sharp features such as edges and corners play an important role in the perception of 3D models. In order to capture them better, we propose quadric loss, a point-surface loss function, which minimizes the quadric error between the reconstructed points and the input surface. Computation of Quadric loss is easy, efficient since the quadric matrices can be computed apriori, and is fully differentiable, making quadric loss suitable for training point and mesh based architectures. Through extensive experiments we show the merits and demerits of quadric loss. When combined with Chamfer loss, quadric loss achieves better reconstruction results as compared to any one of them or other point-surface loss functions.
Two-stream Spatiotemporal Feature for Video QA Task
Jul 11, 2019
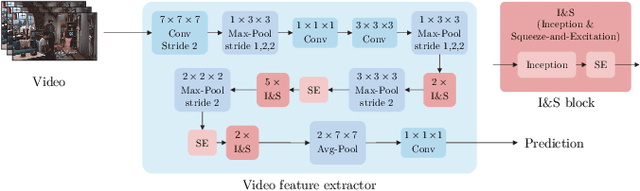
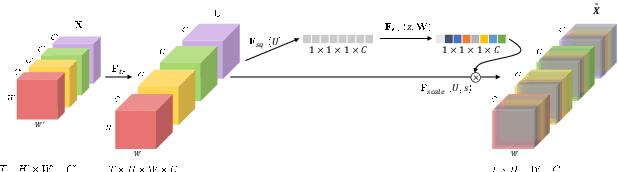

Understanding the content of videos is one of the core techniques for developing various helpful applications in the real world, such as recognizing various human actions for surveillance systems or customer behavior analysis in an autonomous shop. However, understanding the content or story of the video still remains a challenging problem due to its sheer amount of data and temporal structure. In this paper, we propose a multi-channel neural network structure that adopts a two-stream network structure, which has been shown high performance in human action recognition field, and use it as a spatiotemporal video feature extractor for solving video question and answering task. We also adopt a squeeze-and-excitation structure to two-stream network structure for achieving a channel-wise attended spatiotemporal feature. For jointly modeling the spatiotemporal features from video and the textual features from the question, we design a context matching module with a level adjusting layer to remove the gap of information between visual and textual features by applying attention mechanism on joint modeling. Finally, we adopt a scoring mechanism and smoothed ranking loss objective function for selecting the correct answer from answer candidates. We evaluate our model with TVQA dataset, and our approach shows the improved result in textual only setting, but the result with visual feature shows the limitation and possibility of our approach.