 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Semi-supervised Knowledge Distillation from Vision-Language Models via $\mathbf{\texttt{D}}$ual-$\mathbf{\texttt{H}}$ead $\mathbf{\texttt{O}}$ptimization
May 12, 2025Vision-language models (VLMs) have achieved remarkable success across diverse tasks by leveraging rich textual information with minimal labeled data. However, deploying such large models remains challenging, particularly in resource-constrained environments. Knowledge distillation (KD) offers a well-established solution to this problem; however, recent KD approaches from VLMs often involve multi-stage training or additional tuning, increasing computational overhead and optimization complexity. In this paper, we propose $\mathbf{\texttt{D}}$ual-$\mathbf{\texttt{H}}$ead $\mathbf{\texttt{O}}$ptimization ($\mathbf{\texttt{DHO}}$) -- a simple yet effective KD framework that transfers knowledge from VLMs to compact, task-specific models in semi-supervised settings. Specifically, we introduce dual prediction heads that independently learn from labeled data and teacher predictions, and propose to linearly combine their outputs during inference. We observe that $\texttt{DHO}$ mitigates gradient conflicts between supervised and distillation signals, enabling more effective feature learning than single-head KD baselines. As a result, extensive experiments show that $\texttt{DHO}$ consistently outperforms baselines across multiple domains and fine-grained datasets. Notably, on ImageNet, it achieves state-of-the-art performance, improving accuracy by 3% and 0.1% with 1% and 10% labeled data, respectively, while using fewer parameters.
Virtual Piano using Computer Vision
Oct 28, 2019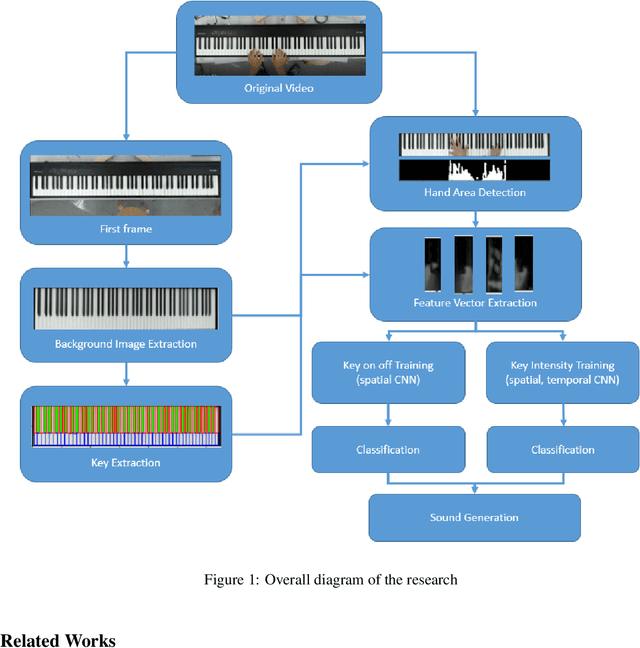



In this research, Piano performances have been analyzed only based on visual information. Computer vision algorithms, e.g., Hough transform and binary thresholding, have been applied to find where the keyboard and specific keys are located. At the same time, Convolutional Neural Networks(CNNs) has been also utilized to find whether specific keys are pressed or not, and how much intensity the keys are pressed only based on visual information. Especially for detecting intensity, a new method of utilizing spatial, temporal CNNs model is devised. Early fusion technique is especially applied in temporal CNNs architecture to analyze hand movement. We also make a new dataset for training each model. Especially when finding an intensity of a pressed key, both of video frames and their optical flow images are used to train models to find effectiveness.