 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Dynamic Radiance Fields with Kinematic Fields
Jul 19, 2024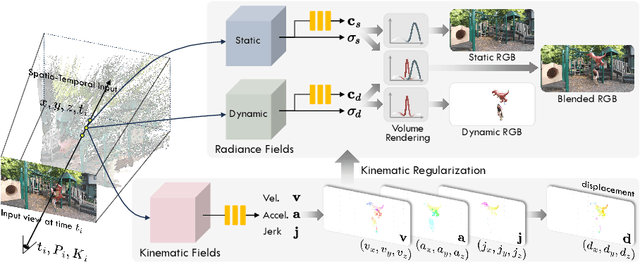

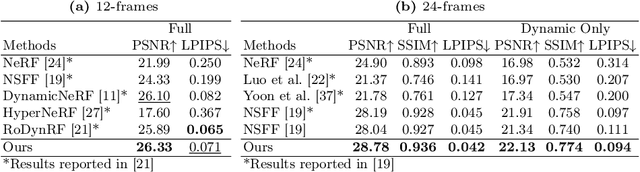

This paper presents a novel approach for reconstructing dynamic radiance fields from monocular videos. We integrate kinematics with dynamic radiance fields, bridging the gap between the sparse nature of monocular videos and the real-world physics. Our method introduces the kinematic field, capturing motion through kinematic quantities: velocity, acceleration, and jerk. The kinematic field is jointly learned with the dynamic radiance field by minimizing the photometric loss without motion ground truth. We further augment our method with physics-driven regularizers grounded in kinematics. We propose physics-driven regularizers that ensure the physical validity of predicted kinematic quantities, including advective acceleration and jerk. Additionally, we control the motion trajectory based on rigidity equations formed with the predicted kinematic quantities. In experiments, our method outperforms the state-of-the-arts by capturing physical motion patterns within challenging real-world monocular videos.
Fine-grained Background Representation for Weakly Supervised Semantic Segmentation
Jun 22, 2024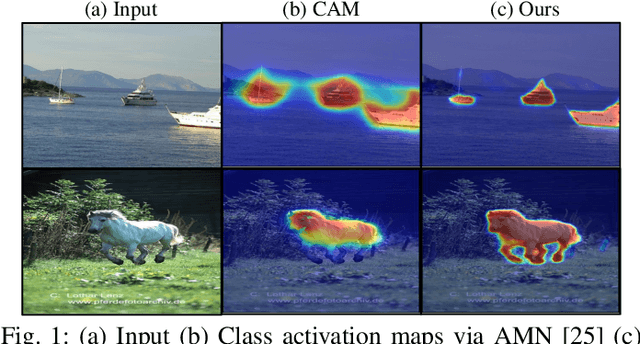
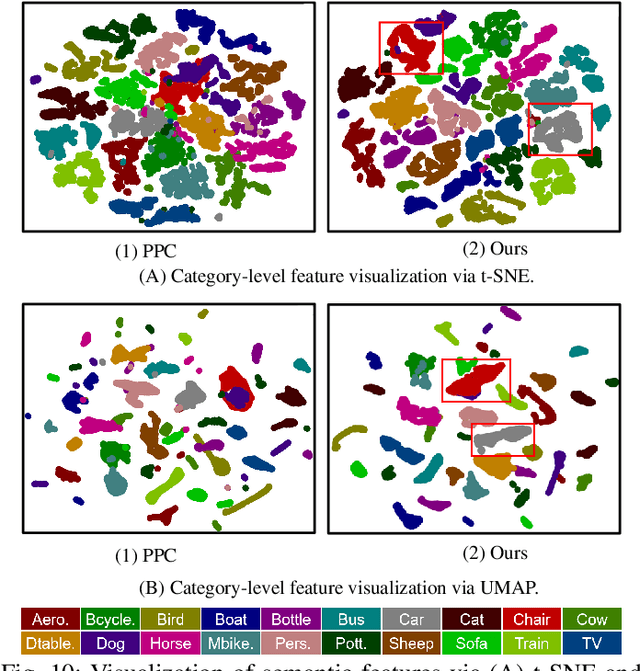

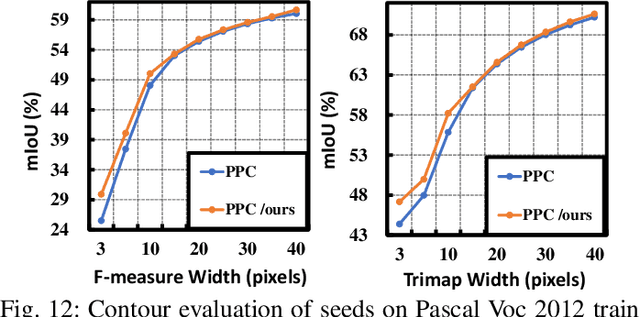
Generating reliable pseudo masks from image-level labels is challenging in the weakly supervised semantic segmentation (WSSS) task due to the lack of spatial information. Prevalent class activation map (CAM)-based solutions are challenged to discriminate the foreground (FG) objects from the suspicious background (BG) pixels (a.k.a. co-occurring) and learn the integral object regions. This paper proposes a simple fine-grained background representation (FBR) method to discover and represent diverse BG semantics and address the co-occurring problems. We abandon using the class prototype or pixel-level features for BG representation. Instead, we develop a novel primitive, negative region of interest (NROI), to capture the fine-grained BG semantic information and conduct the pixel-to-NROI contrast to distinguish the confusing BG pixels. We also present an active sampling strategy to mine the FG negatives on-the-fly, enabling efficient pixel-to-pixel intra-foreground contrastive learning to activate the entire object region. Thanks to the simplicity of design and convenience in use, our proposed method can be seamlessly plugged into various models, yielding new state-of-the-art results under various WSSS settings across benchmarks. Leveraging solely image-level (I) labels as supervision, our method achieves 73.2 mIoU and 45.6 mIoU segmentation results on Pascal Voc and MS COCO test sets, respectively. Furthermore, by incorporating saliency maps as an additional supervision signal (I+S), we attain 74.9 mIoU on Pascal Voc test set. Concurrently, our FBR approach demonstrates meaningful performance gains in weakly-supervised instance segmentation (WSIS) tasks, showcasing its robustness and strong generalization capabilities across diverse domains.
Extending Segment Anything Model into Auditory and Temporal Dimensions for Audio-Visual Segmentation
Jun 10, 2024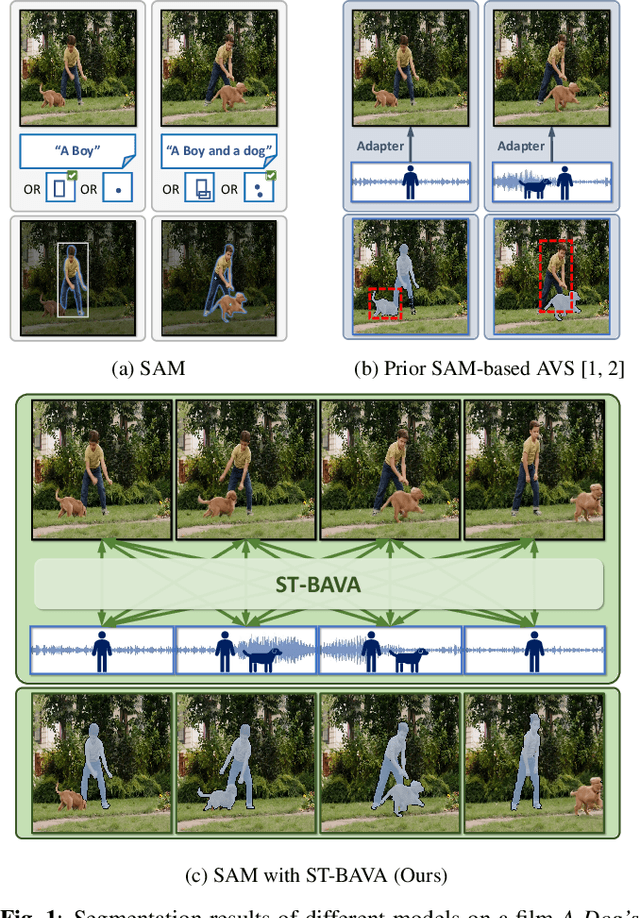
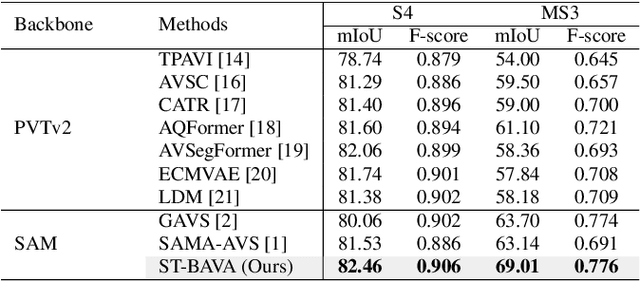
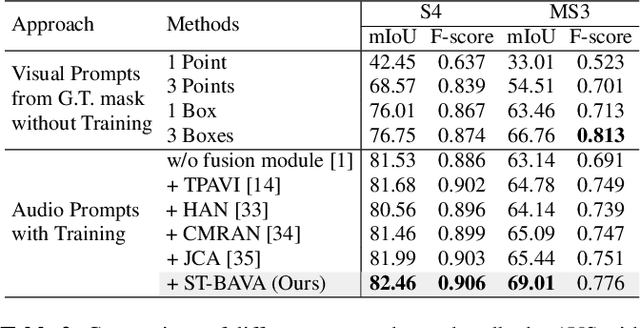
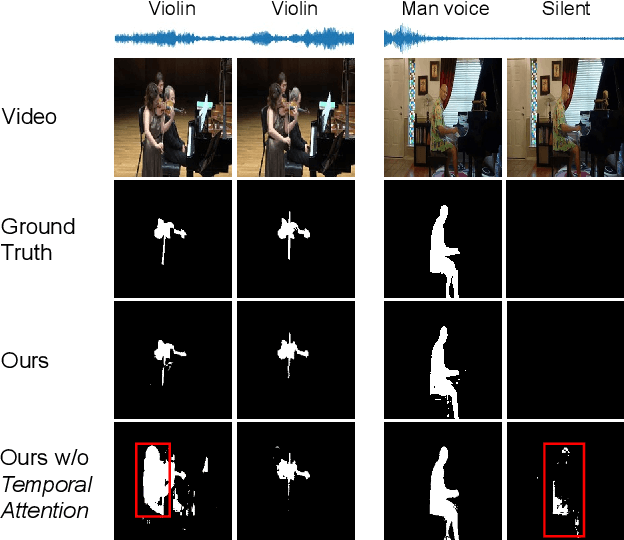
Audio-visual segmentation (AVS) aims to segment sound sources in the video sequence, requiring a pixel-level understanding of audio-visual correspondence. As the Segment Anything Model (SAM) has strongly impacted extensive fields of dense prediction problems, prior works have investigated the introduction of SAM into AVS with audio as a new modality of the prompt. Nevertheless, constrained by SAM's single-frame segmentation scheme, the temporal context across multiple frames of audio-visual data remains insufficiently utilized. To this end, we study the extension of SAM's capabilities to the sequence of audio-visual scenes by analyzing contextual cross-modal relationships across the frames. To achieve this, we propose a Spatio-Temporal, Bidirectional Audio-Visual Attention (ST-BAVA) module integrated into the middle of SAM's image encoder and mask decoder. It adaptively updates the audio-visual features to convey the spatio-temporal correspondence between the video frames and audio streams. Extensive experiments demonstrate that our proposed model outperforms the state-of-the-art methods on AVS benchmarks, especially with an 8.3% mIoU gain on a challenging multi-sources subset.
SemCity: Semantic Scene Generation with Triplane Diffusion
Mar 17, 2024



We present "SemCity," a 3D diffusion model for semantic scene generation in real-world outdoor environments. Most 3D diffusion models focus on generating a single object, synthetic indoor scenes, or synthetic outdoor scenes, while the generation of real-world outdoor scenes is rarely addressed. In this paper, we concentrate on generating a real-outdoor scene through learning a diffusion model on a real-world outdoor dataset. In contrast to synthetic data, real-outdoor datasets often contain more empty spaces due to sensor limitations, causing challenges in learning real-outdoor distributions. To address this issue, we exploit a triplane representation as a proxy form of scene distributions to be learned by our diffusion model. Furthermore, we propose a triplane manipulation that integrates seamlessly with our triplane diffusion model. The manipulation improves our diffusion model's applicability in a variety of downstream tasks related to outdoor scene generation such as scene inpainting, scene outpainting, and semantic scene completion refinements. In experimental results, we demonstrate that our triplane diffusion model shows meaningful generation results compared with existing work in a real-outdoor dataset, SemanticKITTI. We also show our triplane manipulation facilitates seamlessly adding, removing, or modifying objects within a scene. Further, it also enables the expansion of scenes toward a city-level scale. Finally, we evaluate our method on semantic scene completion refinements where our diffusion model enhances predictions of semantic scene completion networks by learning scene distribution. Our code is available at https://github.com/zoomin-lee/SemCity.
Diffusion Probabilistic Models for Scene-Scale 3D Categorical Data
Jan 02, 2023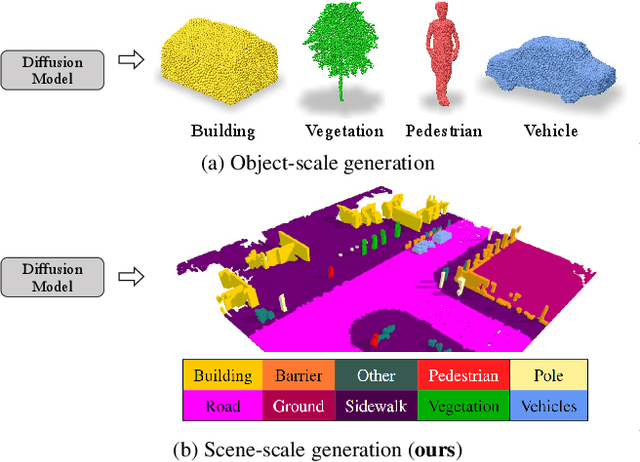
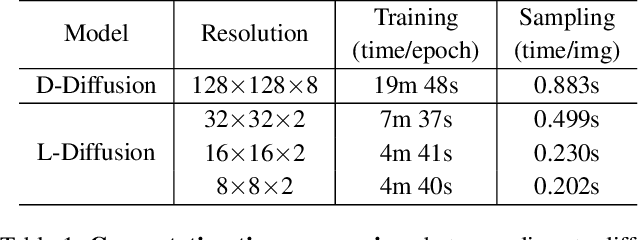
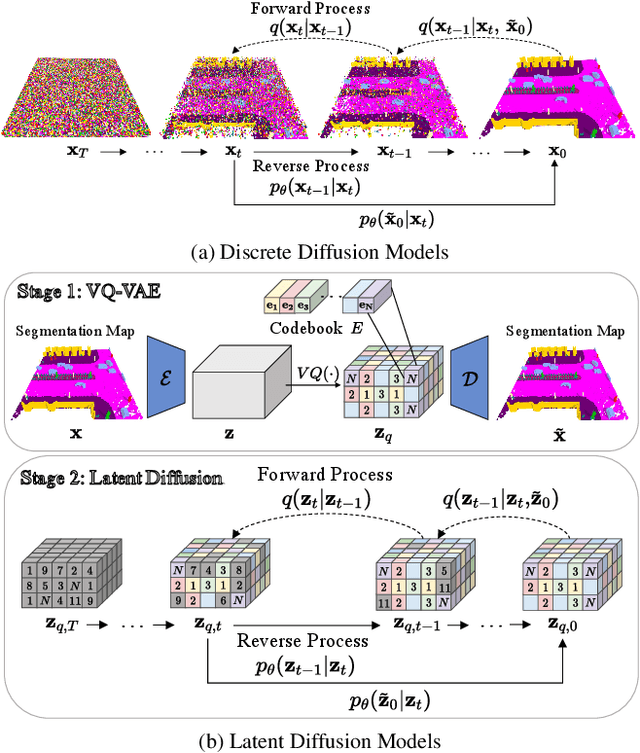
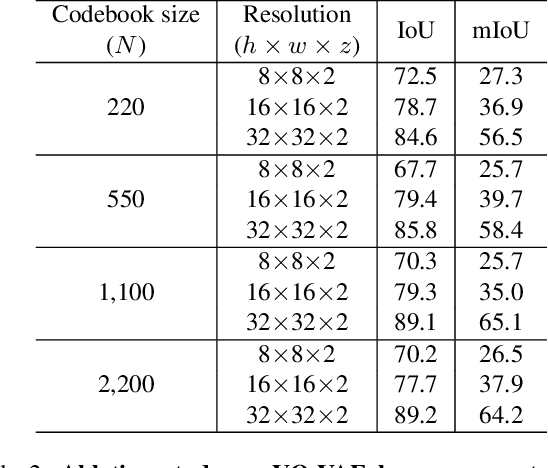
In this paper, we learn a diffusion model to generate 3D data on a scene-scale. Specifically, our model crafts a 3D scene consisting of multiple objects, while recent diffusion research has focused on a single object. To realize our goal, we represent a scene with discrete class labels, i.e., categorical distribution, to assign multiple objects into semantic categories. Thus, we extend discrete diffusion models to learn scene-scale categorical distributions. In addition, we validate that a latent diffusion model can reduce computation costs for training and deploying. To the best of our knowledge, our work is the first to apply discrete and latent diffusion for 3D categorical data on a scene-scale. We further propose to perform semantic scene completion (SSC) by learning a conditional distribution using our diffusion model, where the condition is a partial observation in a sparse point cloud. In experiments, we empirically show that our diffusion models not only generate reasonable scenes, but also perform the scene completion task better than a discriminative model. Our code and models are available at https://github.com/zoomin-lee/scene-scale-diffusion
Semi-Supervised Learning of Optical Flow by Flow Supervisor
Jul 21, 2022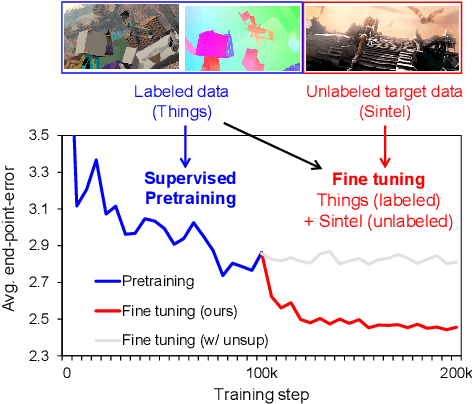
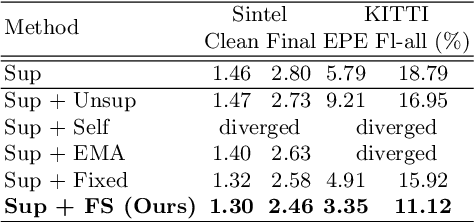
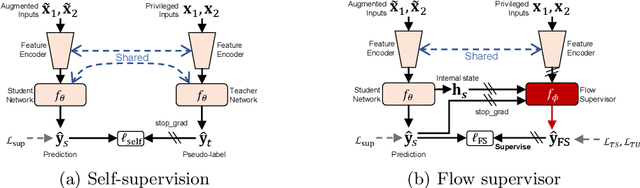
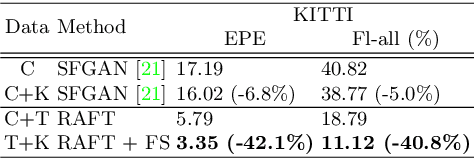
A training pipeline for optical flow CNNs consists of a pretraining stage on a synthetic dataset followed by a fine tuning stage on a target dataset. However, obtaining ground truth flows from a target video requires a tremendous effort. This paper proposes a practical fine tuning method to adapt a pretrained model to a target dataset without ground truth flows, which has not been explored extensively. Specifically, we propose a flow supervisor for self-supervision, which consists of parameter separation and a student output connection. This design is aimed at stable convergence and better accuracy over conventional self-supervision methods which are unstable on the fine tuning task. Experimental results show the effectiveness of our method compared to different self-supervision methods for semi-supervised learning. In addition, we achieve meaningful improvements over state-of-the-art optical flow models on Sintel and KITTI benchmarks by exploiting additional unlabeled datasets. Code is available at https://github.com/iwbn/flow-supervisor.
In-N-Out: Towards Good Initialization for Inpainting and Outpainting
Jun 26, 2021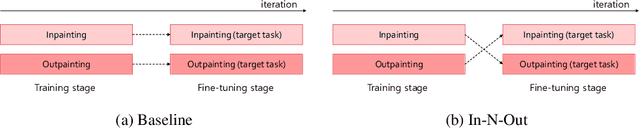
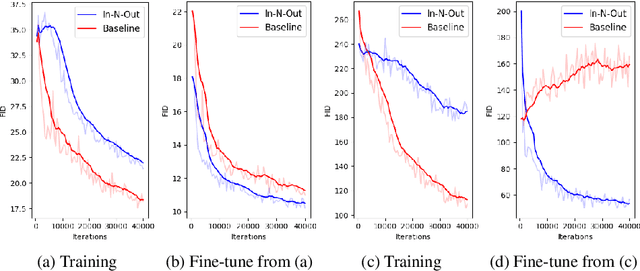

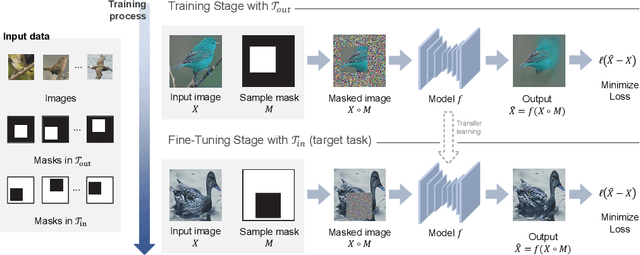
In computer vision, recovering spatial information by filling in masked regions, e.g., inpainting, has been widely investigated for its usability and wide applicability to other various applications: image inpainting, image extrapolation, and environment map estimation. Most of them are studied separately depending on the applications. Our focus, however, is on accommodating the opposite task, e.g., image outpainting, which would benefit the target applications, e.g., image inpainting. Our self-supervision method, In-N-Out, is summarized as a training approach that leverages the knowledge of the opposite task into the target model. We empirically show that In-N-Out -- which explores the complementary information -- effectively takes advantage over the traditional pipelines where only task-specific learning takes place in training. In experiments, we compare our method to the traditional procedure and analyze the effectiveness of our method on different applications: image inpainting, image extrapolation, and environment map estimation. For these tasks, we demonstrate that In-N-Out consistently improves the performance of the recent works with In-N-Out self-supervision to their training procedure. Also, we show that our approach achieves better results than an existing training approach for outpainting.
Two-stream Spatiotemporal Feature for Video QA Task
Jul 11, 2019
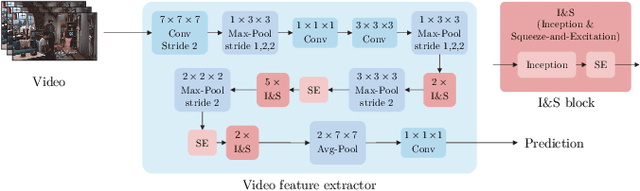
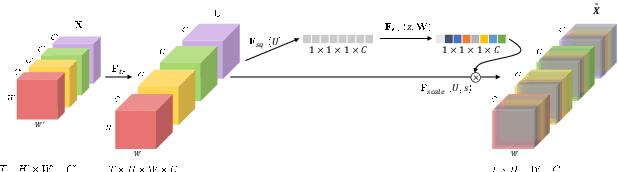

Understanding the content of videos is one of the core techniques for developing various helpful applications in the real world, such as recognizing various human actions for surveillance systems or customer behavior analysis in an autonomous shop. However, understanding the content or story of the video still remains a challenging problem due to its sheer amount of data and temporal structure. In this paper, we propose a multi-channel neural network structure that adopts a two-stream network structure, which has been shown high performance in human action recognition field, and use it as a spatiotemporal video feature extractor for solving video question and answering task. We also adopt a squeeze-and-excitation structure to two-stream network structure for achieving a channel-wise attended spatiotemporal feature. For jointly modeling the spatiotemporal features from video and the textual features from the question, we design a context matching module with a level adjusting layer to remove the gap of information between visual and textual features by applying attention mechanism on joint modeling. Finally, we adopt a scoring mechanism and smoothed ranking loss objective function for selecting the correct answer from answer candidates. We evaluate our model with TVQA dataset, and our approach shows the improved result in textual only setting, but the result with visual feature shows the limitation and possibility of our approach.
SSPP-DAN: Deep Domain Adaptation Network for Face Recognition with Single Sample Per Person
Apr 28, 2018
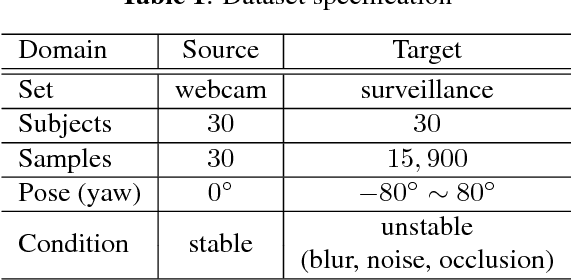
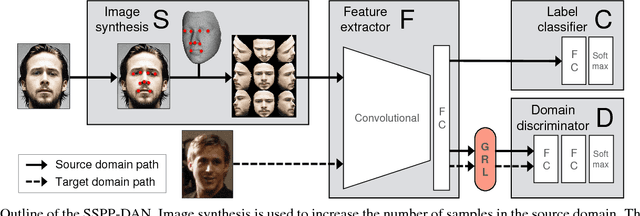
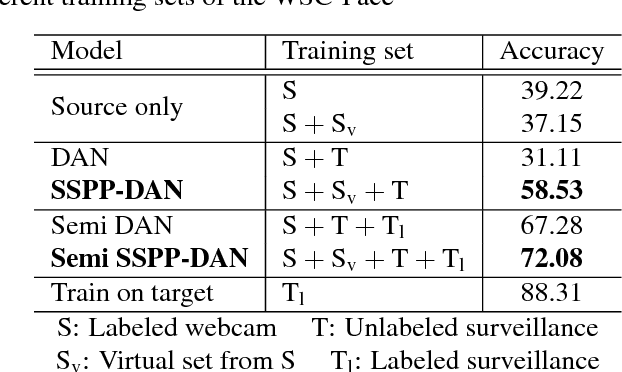
Real-world face recognition using a single sample per person (SSPP) is a challenging task. The problem is exacerbated if the conditions under which the gallery image and the probe set are captured are completely different. To address these issues from the perspective of domain adaptation, we introduce an SSPP domain adaptation network (SSPP-DAN). In the proposed approach, domain adaptation, feature extraction, and classification are performed jointly using a deep architecture with domain-adversarial training. However, the SSPP characteristic of one training sample per class is insufficient to train the deep architecture. To overcome this shortage, we generate synthetic images with varying poses using a 3D face model. Experimental evaluations using a realistic SSPP dataset show that deep domain adaptation and image synthesis complement each other and dramatically improve accuracy. Experiments on a benchmark dataset using the proposed approach show state-of-the-art performance. All the dataset and the source code can be found in our online repository (https://github.com/csehong/SSPP-DAN).
Content-Based Video-Music Retrieval Using Soft Intra-Modal Structure Constraint
Sep 01, 2017

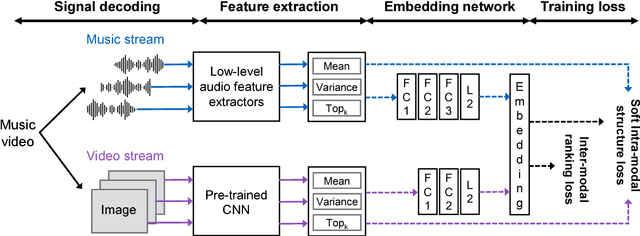
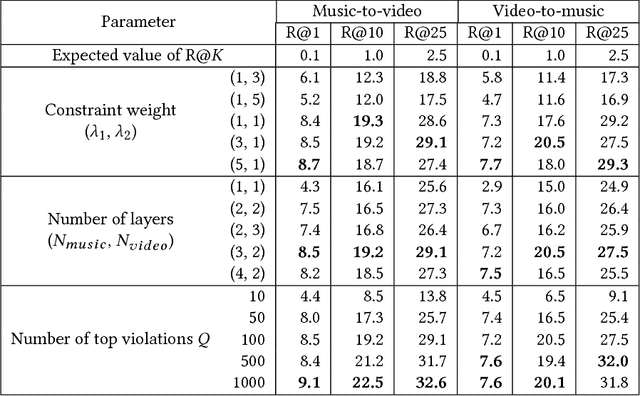
Up to now, only limited research has been conducted on cross-modal retrieval of suitable music for a specified video or vice versa. Moreover, much of the existing research relies on metadata such as keywords, tags, or associated description that must be individually produced and attached posterior. This paper introduces a new content-based, cross-modal retrieval method for video and music that is implemented through deep neural networks. We train the network via inter-modal ranking loss such that videos and music with similar semantics end up close together in the embedding space. However, if only the inter-modal ranking constraint is used for embedding, modality-specific characteristics can be lost. To address this problem, we propose a novel soft intra-modal structure loss that leverages the relative distance relationship between intra-modal samples before embedding. We also introduce reasonable quantitative and qualitative experimental protocols to solve the lack of standard protocols for less-mature video-music related tasks. Finally, we construct a large-scale 200K video-music pair benchmark. All the datasets and source code can be found in our online repository (https://github.com/csehong/VM-NET).