 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSPP-DAN: Deep Domain Adaptation Network for Face Recognition with Single Sample Per Person
Apr 28, 2018
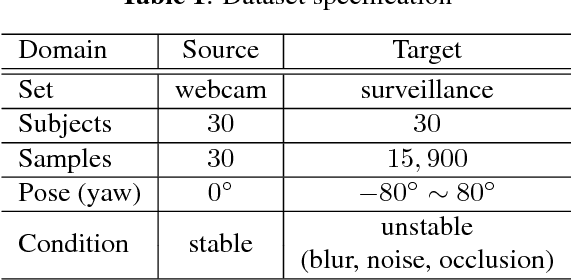
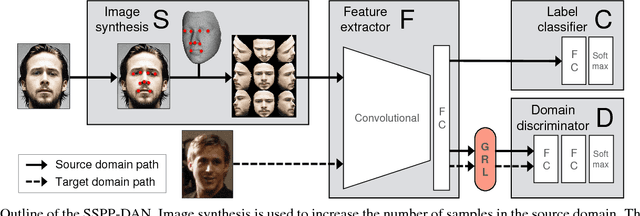
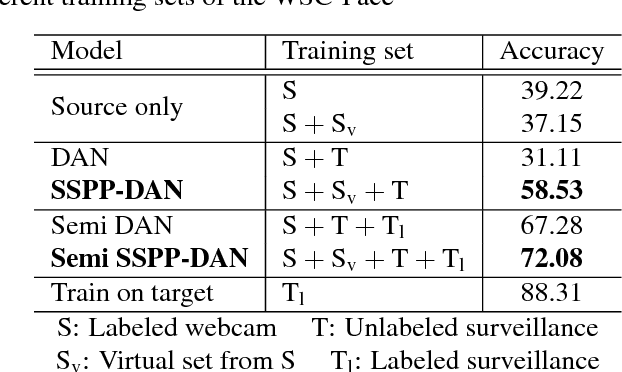
Real-world face recognition using a single sample per person (SSPP) is a challenging task. The problem is exacerbated if the conditions under which the gallery image and the probe set are captured are completely different. To address these issues from the perspective of domain adaptation, we introduce an SSPP domain adaptation network (SSPP-DAN). In the proposed approach, domain adaptation, feature extraction, and classification are performed jointly using a deep architecture with domain-adversarial training. However, the SSPP characteristic of one training sample per class is insufficient to train the deep architecture. To overcome this shortage, we generate synthetic images with varying poses using a 3D face model. Experimental evaluations using a realistic SSPP dataset show that deep domain adaptation and image synthesis complement each other and dramatically improve accuracy. Experiments on a benchmark dataset using the proposed approach show state-of-the-art performance. All the dataset and the source code can be found in our online repository (https://github.com/csehong/SSPP-DAN).
Content-Based Video-Music Retrieval Using Soft Intra-Modal Structure Constraint
Sep 01, 2017

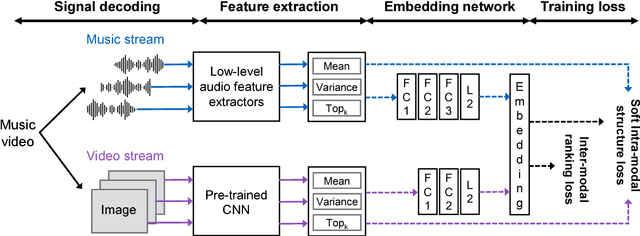
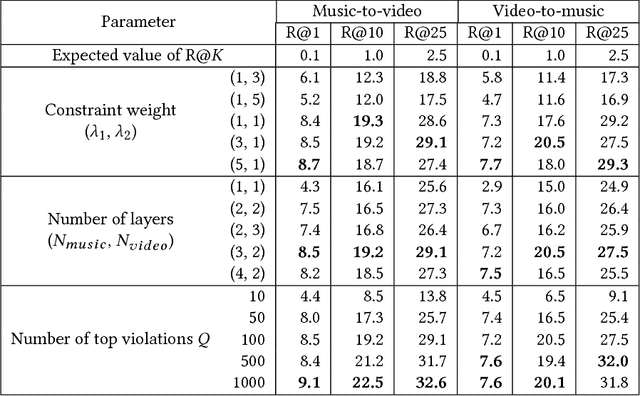
Up to now, only limited research has been conducted on cross-modal retrieval of suitable music for a specified video or vice versa. Moreover, much of the existing research relies on metadata such as keywords, tags, or associated description that must be individually produced and attached posterior. This paper introduces a new content-based, cross-modal retrieval method for video and music that is implemented through deep neural networks. We train the network via inter-modal ranking loss such that videos and music with similar semantics end up close together in the embedding space. However, if only the inter-modal ranking constraint is used for embedding, modality-specific characteristics can be lost. To address this problem, we propose a novel soft intra-modal structure loss that leverages the relative distance relationship between intra-modal samples before embedding. We also introduce reasonable quantitative and qualitative experimental protocols to solve the lack of standard protocols for less-mature video-music related tasks. Finally, we construct a large-scale 200K video-music pair benchmark. All the datasets and source code can be found in our online repository (https://github.com/csehong/VM-NET).
Recognizing Dynamic Scenes with Deep Dual Descriptor based on Key Frames and Key Segments
Feb 16, 2017
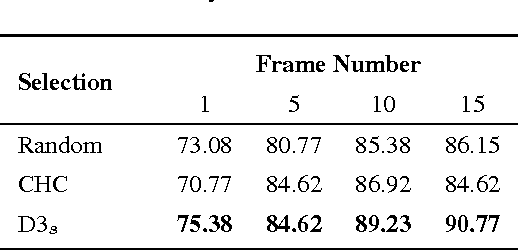
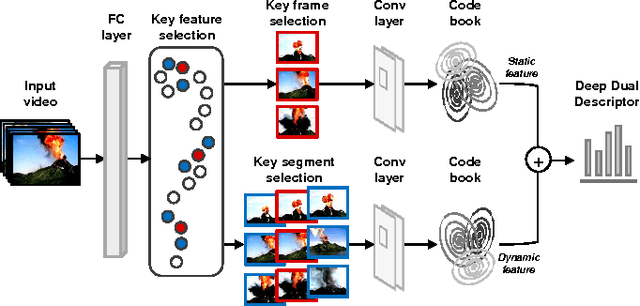

Recognizing dynamic scenes is one of the fundamental problems in scene understanding, which categorizes moving scenes such as a forest fire, landslide, or avalanche. While existing methods focus on reliable capturing of static and dynamic information, few works have explored frame selection from a dynamic scene sequence. In this paper, we propose dynamic scene recognition using a deep dual descriptor based on `key frames' and `key segments.' Key frames that reflect the feature distribution of the sequence with a small number are used for capturing salient static appearances. Key segments, which are captured from the area around each key frame, provide an additional discriminative power by dynamic patterns within short time intervals. To this end, two types of transferred convolutional neural network features are used in our approach. A fully connected layer is used to select the key frames and key segments, while the convolutional layer is used to describe them. We conducted experiments using public datasets as well as a new dataset comprised of 23 dynamic scene classes with 10 videos per class. The evaluation results demonstrated the state-of-the-art performance of the proposed method.