 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-Based Video-Music Retrieval Using Soft Intra-Modal Structure Constraint
Paper and Code

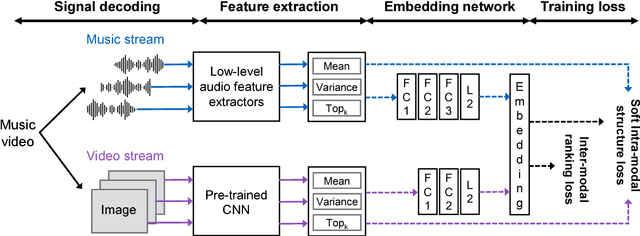
Up to now, only limited research has been conducted on cross-modal retrieval of suitable music for a specified video or vice versa. Moreover, much of the existing research relies on metadata such as keywords, tags, or associated description that must be individually produced and attached posterior. This paper introduces a new content-based, cross-modal retrieval method for video and music that is implemented through deep neural networks. We train the network via inter-modal ranking loss such that videos and music with similar semantics end up close together in the embedding space. However, if only the inter-modal ranking constraint is used for embedding, modality-specific characteristics can be lost. To address this problem, we propose a novel soft intra-modal structure loss that leverages the relative distance relationship between intra-modal samples before embedding. We also introduce reasonable quantitative and qualitative experimental protocols to solve the lack of standard protocols for less-mature video-music related tasks. Finally, we construct a large-scale 200K video-music pair benchmark. All the datasets and source code can be found in our online repository (https://github.com/csehong/VM-NET).