 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLaD: Planning with Grounded Foresight via Cross-Modal Latent Dynamics
Mar 31, 2026Robotic manipulation involves kinematic and semantic transitions that are inherently coupled via underlying actions. However, existing approaches plan within either semantic or latent space without explicitly aligning these cross-modal transitions. To address this, we propose CLaD, a framework that models how proprioceptive and semantic states jointly evolve under actions through asymmetric cross-attention that allows kinematic transitions to query semantic ones. CLaD predicts grounded latent foresights via self-supervised objectives with EMA target encoders and auxiliary reconstruction losses, preventing representation collapse while anchoring predictions to observable states. Predicted foresights are modulated with observations to condition a diffusion policy for action generation. On LIBERO-LONG benchmark, CLaD achieves 94.7\% success rate, competitive with large VLAs with significantly fewer parameters.
Beyond the Patch: Exploring Vulnerabilities of Visuomotor Policies via Viewpoint-Consistent 3D Adversarial Object
Mar 05, 2026Neural network-based visuomotor policies enable robots to perform manipulation tasks but remain susceptible to perceptual attacks. For example, conventional 2D adversarial patches are effective under fixed-camera setups, where appearance is relatively consistent; however, their efficacy often diminishes under dynamic viewpoints from moving cameras, such as wrist-mounted setups, due to perspective distortions. To proactively investigate potential vulnerabilities beyond 2D patches, this work proposes a viewpoint-consistent adversarial texture optimization method for 3D objects through differentiable rendering. As optimization strategies, we employ Expectation over Transformation (EOT) with a Coarse-to-Fine (C2F) curriculum, exploiting distance-dependent frequency characteristics to induce textures effective across varying camera-object distances. We further integrate saliency-guided perturbations to redirect policy attention and design a targeted loss that persistently drives robots toward adversarial objects. Our comprehensive experiments show that the proposed method is effective under various environmental conditions, while confirming its black-box transferability and real-world applicability.
Hybrid Quantum Temporal Convolutional Networks
Feb 27, 2026Quantum machine learning models for sequential data face scalability challenges with complex multivariate signals. We introduce the Hybrid Quantum Temporal Convolutional Network (HQTCN), which combines classical temporal windowing with a quantum convolutional neural network core. By applying a shared quantum circuit across temporal windows, HQTCN captures long-range dependencies while achieving significant parameter reduction. Evaluated on synthetic NARMA sequences and high-dimensional EEG time-series, HQTCN performs competitively with classical baselines on univariate data and outperforms all baselines on multivariate tasks. The model demonstrates particular strength under data-limited conditions, maintaining high performance with substantially fewer parameters than conventional approaches. These results establish HQTCN as a parameter-efficient approach for multivariate time-series analysis.
DIVER-1 : Deep Integration of Vast Electrophysiological Recordings at Scale
Dec 22, 2025



Electrophysiology signals such as EEG and iEEG are central to neuroscience, brain-computer interfaces, and clinical applications, yet existing foundation models remain limited in scale despite clear evidence that scaling improves performance. We introduce DIVER-1, a family of EEG and iEEG foundation models trained on the largest and most diverse corpus to date-5.3k hours of iEEG and 54k hours of EEG (1.6M channel-hours from over 17.7k subjects)-and scaled up to 1.82B parameters. We present the first systematic scaling law analysis for this domain, showing that they follow data-constrained scaling laws: for a given amount of data and compute, smaller models trained for extended epochs consistently outperform larger models trained briefly. This behavior contrasts with prior electrophysiology foundation models that emphasized model size over training duration. To achieve strong performance, we also design architectural innovations including any-variate attention, sliding temporal conditional positional encoding, and multi-domain reconstruction. DIVER-1 iEEG and EEG models each achieve state-of-the-art performance on their respective benchmarks, establishing a concrete guidelines for efficient scaling and resource allocation in electrophysiology foundation model development.
Regularizing Dynamic Radiance Fields with Kinematic Fields
Jul 19, 2024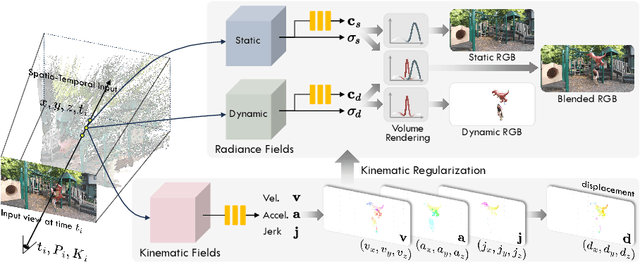

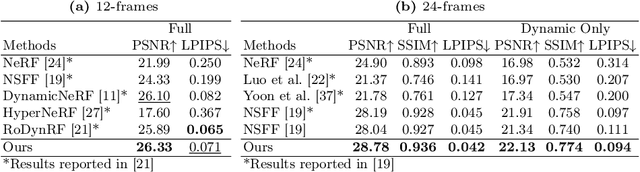

This paper presents a novel approach for reconstructing dynamic radiance fields from monocular videos. We integrate kinematics with dynamic radiance fields, bridging the gap between the sparse nature of monocular videos and the real-world physics. Our method introduces the kinematic field, capturing motion through kinematic quantities: velocity, acceleration, and jerk. The kinematic field is jointly learned with the dynamic radiance field by minimizing the photometric loss without motion ground truth. We further augment our method with physics-driven regularizers grounded in kinematics. We propose physics-driven regularizers that ensure the physical validity of predicted kinematic quantities, including advective acceleration and jerk. Additionally, we control the motion trajectory based on rigidity equations formed with the predicted kinematic quantities. In experiments, our method outperforms the state-of-the-arts by capturing physical motion patterns within challenging real-world monocular videos.
Extending Segment Anything Model into Auditory and Temporal Dimensions for Audio-Visual Segmentation
Jun 10, 2024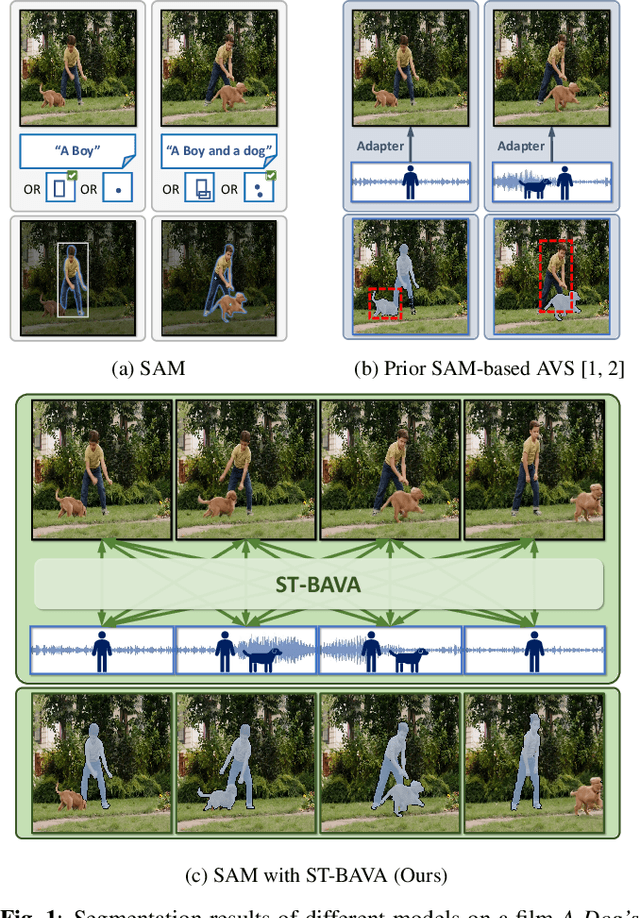
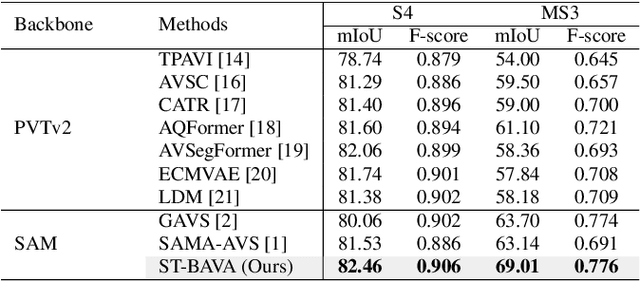
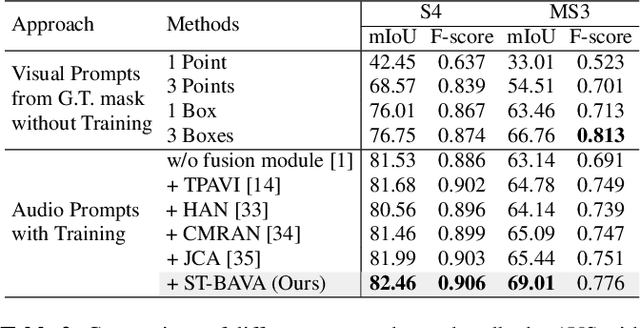
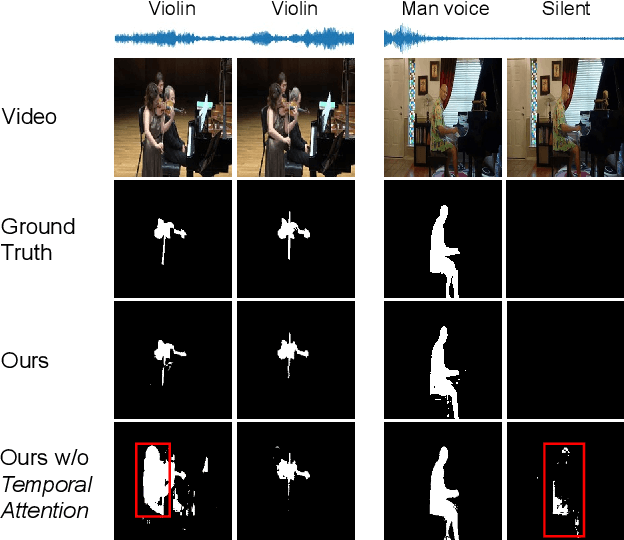
Audio-visual segmentation (AVS) aims to segment sound sources in the video sequence, requiring a pixel-level understanding of audio-visual correspondence. As the Segment Anything Model (SAM) has strongly impacted extensive fields of dense prediction problems, prior works have investigated the introduction of SAM into AVS with audio as a new modality of the prompt. Nevertheless, constrained by SAM's single-frame segmentation scheme, the temporal context across multiple frames of audio-visual data remains insufficiently utilized. To this end, we study the extension of SAM's capabilities to the sequence of audio-visual scenes by analyzing contextual cross-modal relationships across the frames. To achieve this, we propose a Spatio-Temporal, Bidirectional Audio-Visual Attention (ST-BAVA) module integrated into the middle of SAM's image encoder and mask decoder. It adaptively updates the audio-visual features to convey the spatio-temporal correspondence between the video frames and audio streams. Extensive experiments demonstrate that our proposed model outperforms the state-of-the-art methods on AVS benchmarks, especially with an 8.3% mIoU gain on a challenging multi-sources subset.
SemCity: Semantic Scene Generation with Triplane Diffusion
Mar 17, 2024



We present "SemCity," a 3D diffusion model for semantic scene generation in real-world outdoor environments. Most 3D diffusion models focus on generating a single object, synthetic indoor scenes, or synthetic outdoor scenes, while the generation of real-world outdoor scenes is rarely addressed. In this paper, we concentrate on generating a real-outdoor scene through learning a diffusion model on a real-world outdoor dataset. In contrast to synthetic data, real-outdoor datasets often contain more empty spaces due to sensor limitations, causing challenges in learning real-outdoor distributions. To address this issue, we exploit a triplane representation as a proxy form of scene distributions to be learned by our diffusion model. Furthermore, we propose a triplane manipulation that integrates seamlessly with our triplane diffusion model. The manipulation improves our diffusion model's applicability in a variety of downstream tasks related to outdoor scene generation such as scene inpainting, scene outpainting, and semantic scene completion refinements. In experimental results, we demonstrate that our triplane diffusion model shows meaningful generation results compared with existing work in a real-outdoor dataset, SemanticKITTI. We also show our triplane manipulation facilitates seamlessly adding, removing, or modifying objects within a scene. Further, it also enables the expansion of scenes toward a city-level scale. Finally, we evaluate our method on semantic scene completion refinements where our diffusion model enhances predictions of semantic scene completion networks by learning scene distribution. Our code is available at https://github.com/zoomin-lee/SemCity.
Diffusion Probabilistic Models for Scene-Scale 3D Categorical Data
Jan 02, 2023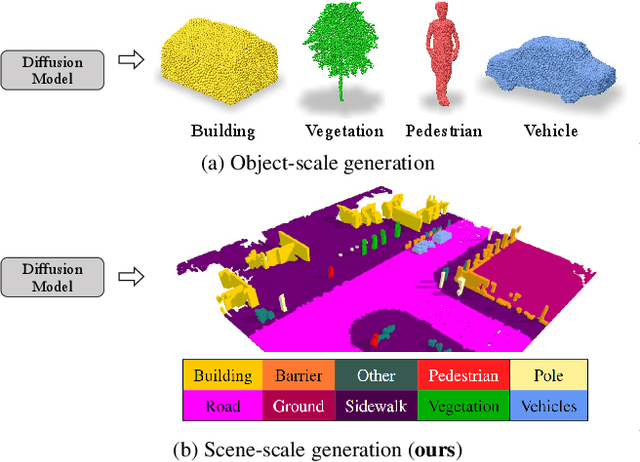
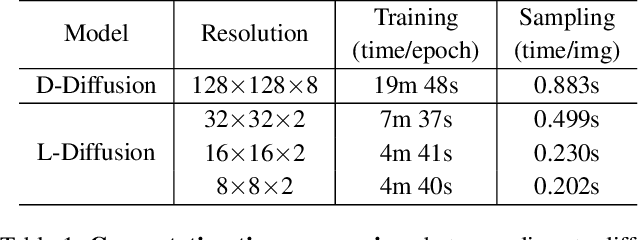
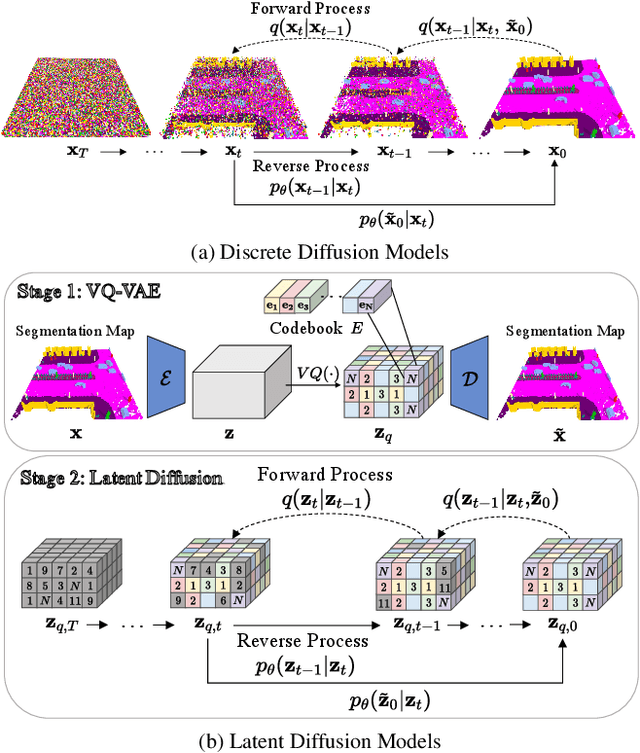
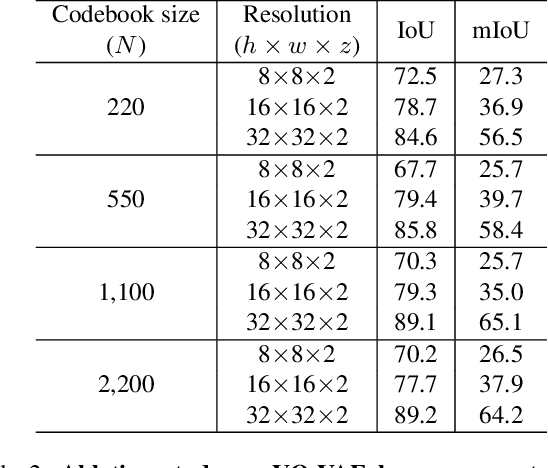
In this paper, we learn a diffusion model to generate 3D data on a scene-scale. Specifically, our model crafts a 3D scene consisting of multiple objects, while recent diffusion research has focused on a single object. To realize our goal, we represent a scene with discrete class labels, i.e., categorical distribution, to assign multiple objects into semantic categories. Thus, we extend discrete diffusion models to learn scene-scale categorical distributions. In addition, we validate that a latent diffusion model can reduce computation costs for training and deploying. To the best of our knowledge, our work is the first to apply discrete and latent diffusion for 3D categorical data on a scene-scale. We further propose to perform semantic scene completion (SSC) by learning a conditional distribution using our diffusion model, where the condition is a partial observation in a sparse point cloud. In experiments, we empirically show that our diffusion models not only generate reasonable scenes, but also perform the scene completion task better than a discriminative model. Our code and models are available at https://github.com/zoomin-lee/scene-scale-diffusion
Ordered sorting of cluttered objects using multiple mobile manipulators
Nov 23, 2022We present a search-based planning algorithm to sort objects in clutter using a multi-robot team. We consider the object rearrangement problem in which the objects must be sorted into different groups in a particular order. In clutter, the order constraints could not be easily satisfied since some objects occlude other objects. Those objects occluding others need to be moved more than once to make the occluded objects accessible. This nonmonotone class of the rearrangement prob- lem with order constraints becomes harder if multiple robots are involved, which practically mandates proper computations of robot allocations. The proposed method first finds a sequence of objects to be sorted using a search such that the order constraint in each group is satisfied. The search can solve nonmonotone instances that require temporal relocation of some objects to access the next object to be sorted. Once a complete sorting sequence is found, the objects in the sequence are assigned to multiple mobile manipulators using a greedy allocation method. We develop four versions of the method with different search strategies. In the experiments, we show that our method can find a sorting sequence quickly (e.g., 4.6 sec with 20 objects sorted into five groups) even though the solved instances include hard nonmonotone ones. The extensive tests and the experiments in simulation show the ability of the method to solve the real-world sorting problem using multiple mobile manipulators.
Semi-Supervised Learning of Optical Flow by Flow Supervisor
Jul 21, 2022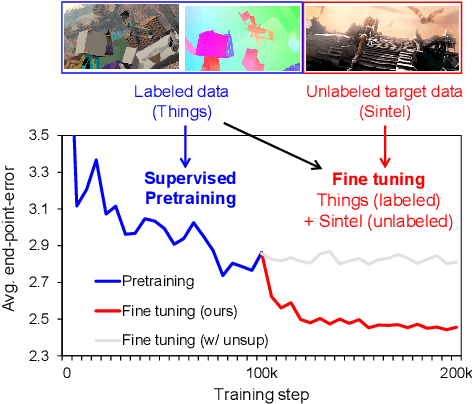
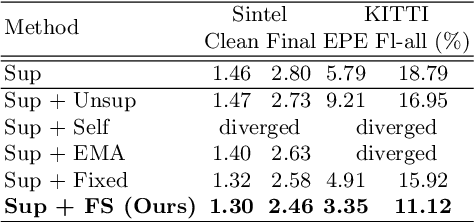
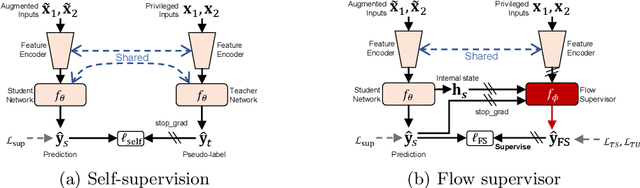
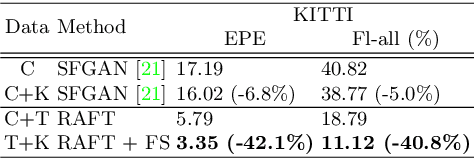
A training pipeline for optical flow CNNs consists of a pretraining stage on a synthetic dataset followed by a fine tuning stage on a target dataset. However, obtaining ground truth flows from a target video requires a tremendous effort. This paper proposes a practical fine tuning method to adapt a pretrained model to a target dataset without ground truth flows, which has not been explored extensively. Specifically, we propose a flow supervisor for self-supervision, which consists of parameter separation and a student output connection. This design is aimed at stable convergence and better accuracy over conventional self-supervision methods which are unstable on the fine tuning task. Experimental results show the effectiveness of our method compared to different self-supervision methods for semi-supervised learning. In addition, we achieve meaningful improvements over state-of-the-art optical flow models on Sintel and KITTI benchmarks by exploiting additional unlabeled datasets. Code is available at https://github.com/iwbn/flow-supervisor.