 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemCity: Semantic Scene Generation with Triplane Diffusion
Mar 17, 2024



We present "SemCity," a 3D diffusion model for semantic scene generation in real-world outdoor environments. Most 3D diffusion models focus on generating a single object, synthetic indoor scenes, or synthetic outdoor scenes, while the generation of real-world outdoor scenes is rarely addressed. In this paper, we concentrate on generating a real-outdoor scene through learning a diffusion model on a real-world outdoor dataset. In contrast to synthetic data, real-outdoor datasets often contain more empty spaces due to sensor limitations, causing challenges in learning real-outdoor distributions. To address this issue, we exploit a triplane representation as a proxy form of scene distributions to be learned by our diffusion model. Furthermore, we propose a triplane manipulation that integrates seamlessly with our triplane diffusion model. The manipulation improves our diffusion model's applicability in a variety of downstream tasks related to outdoor scene generation such as scene inpainting, scene outpainting, and semantic scene completion refinements. In experimental results, we demonstrate that our triplane diffusion model shows meaningful generation results compared with existing work in a real-outdoor dataset, SemanticKITTI. We also show our triplane manipulation facilitates seamlessly adding, removing, or modifying objects within a scene. Further, it also enables the expansion of scenes toward a city-level scale. Finally, we evaluate our method on semantic scene completion refinements where our diffusion model enhances predictions of semantic scene completion networks by learning scene distribution. Our code is available at https://github.com/zoomin-lee/SemCity.
In-N-Out: Towards Good Initialization for Inpainting and Outpainting
Jun 26, 2021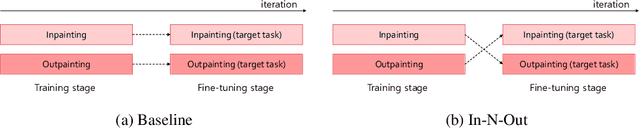
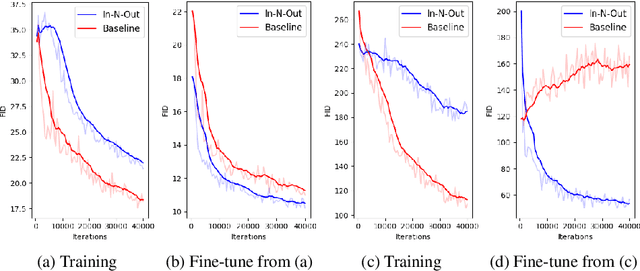

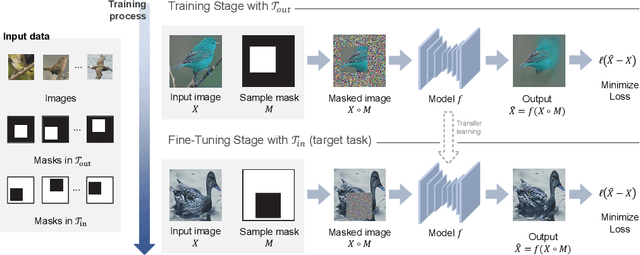
In computer vision, recovering spatial information by filling in masked regions, e.g., inpainting, has been widely investigated for its usability and wide applicability to other various applications: image inpainting, image extrapolation, and environment map estimation. Most of them are studied separately depending on the applications. Our focus, however, is on accommodating the opposite task, e.g., image outpainting, which would benefit the target applications, e.g., image inpainting. Our self-supervision method, In-N-Out, is summarized as a training approach that leverages the knowledge of the opposite task into the target model. We empirically show that In-N-Out -- which explores the complementary information -- effectively takes advantage over the traditional pipelines where only task-specific learning takes place in training. In experiments, we compare our method to the traditional procedure and analyze the effectiveness of our method on different applications: image inpainting, image extrapolation, and environment map estimation. For these tasks, we demonstrate that In-N-Out consistently improves the performance of the recent works with In-N-Out self-supervision to their training procedure. Also, we show that our approach achieves better results than an existing training approach for outpainting.