 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-N-Out: Towards Good Initialization for Inpainting and Outpainting
Paper and Code
Jun 26, 2021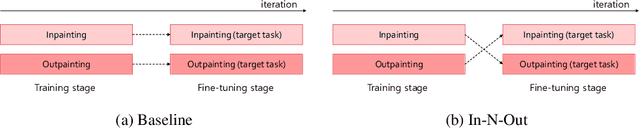
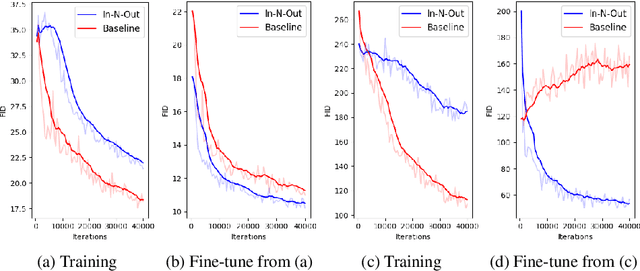

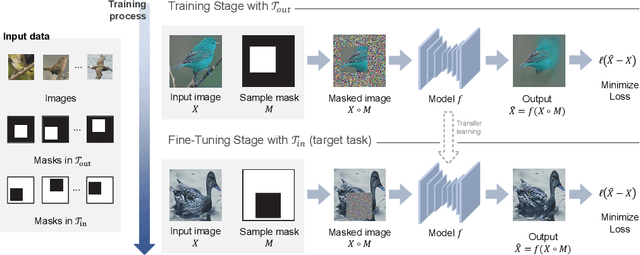
In computer vision, recovering spatial information by filling in masked regions, e.g., inpainting, has been widely investigated for its usability and wide applicability to other various applications: image inpainting, image extrapolation, and environment map estimation. Most of them are studied separately depending on the applications. Our focus, however, is on accommodating the opposite task, e.g., image outpainting, which would benefit the target applications, e.g., image inpainting. Our self-supervision method, In-N-Out, is summarized as a training approach that leverages the knowledge of the opposite task into the target model. We empirically show that In-N-Out -- which explores the complementary information -- effectively takes advantage over the traditional pipelines where only task-specific learning takes place in training. In experiments, we compare our method to the traditional procedure and analyze the effectiveness of our method on different applications: image inpainting, image extrapolation, and environment map estimation. For these tasks, we demonstrate that In-N-Out consistently improves the performance of the recent works with In-N-Out self-supervision to their training procedure. Also, we show that our approach achieves better results than an existing training approach for outpainting.