 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAMO: Category-Agnostic 3D Motion Transfer from Monocular 2D Videos
Jan 06, 2026Motion transfer from 2D videos to 3D assets is a challenging problem, due to inherent pose ambiguities and diverse object shapes, often requiring category-specific parametric templates. We propose CAMO, a category-agnostic framework that transfers motion to diverse target meshes directly from monocular 2D videos without relying on predefined templates or explicit 3D supervision. The core of CAMO is a morphology-parameterized articulated 3D Gaussian splatting model combined with dense semantic correspondences to jointly adapt shape and pose through optimization. This approach effectively alleviates shape-pose ambiguities, enabling visually faithful motion transfer for diverse categories. Experimental results demonstrate superior motion accuracy, efficiency, and visual coherence compared to existing methods, significantly advancing motion transfer in varied object categories and casual video scenarios.
Pose-free 3D Gaussian splatting via shape-ray estimation
May 29, 2025While generalizable 3D Gaussian splatting enables efficient, high-quality rendering of unseen scenes, it heavily depends on precise camera poses for accurate geometry. In real-world scenarios, obtaining accurate poses is challenging, leading to noisy pose estimates and geometric misalignments. To address this, we introduce SHARE, a pose-free, feed-forward Gaussian splatting framework that overcomes these ambiguities by joint shape and camera rays estimation. Instead of relying on explicit 3D transformations, SHARE builds a pose-aware canonical volume representation that seamlessly integrates multi-view information, reducing misalignment caused by inaccurate pose estimates. Additionally, anchor-aligned Gaussian prediction enhances scene reconstruction by refining local geometry around coarse anchors, allowing for more precise Gaussian placement. Extensive experiments on diverse real-world datasets show that our method achieves robust performance in pose-free generalizable Gaussian splatting.
Regularizing Dynamic Radiance Fields with Kinematic Fields
Jul 19, 2024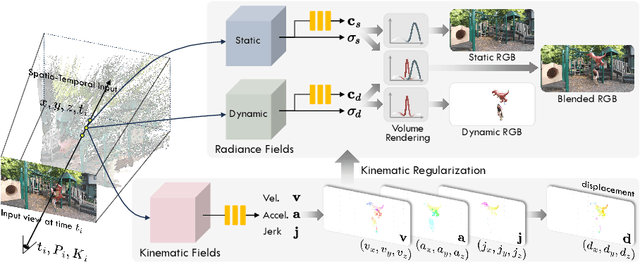

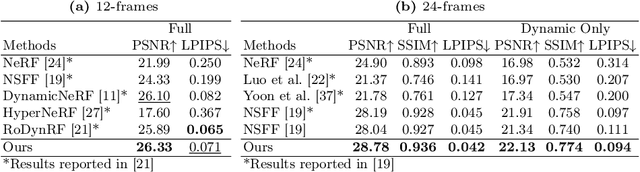

This paper presents a novel approach for reconstructing dynamic radiance fields from monocular videos. We integrate kinematics with dynamic radiance fields, bridging the gap between the sparse nature of monocular videos and the real-world physics. Our method introduces the kinematic field, capturing motion through kinematic quantities: velocity, acceleration, and jerk. The kinematic field is jointly learned with the dynamic radiance field by minimizing the photometric loss without motion ground truth. We further augment our method with physics-driven regularizers grounded in kinematics. We propose physics-driven regularizers that ensure the physical validity of predicted kinematic quantities, including advective acceleration and jerk. Additionally, we control the motion trajectory based on rigidity equations formed with the predicted kinematic quantities. In experiments, our method outperforms the state-of-the-arts by capturing physical motion patterns within challenging real-world monocular videos.
Extending Segment Anything Model into Auditory and Temporal Dimensions for Audio-Visual Segmentation
Jun 10, 2024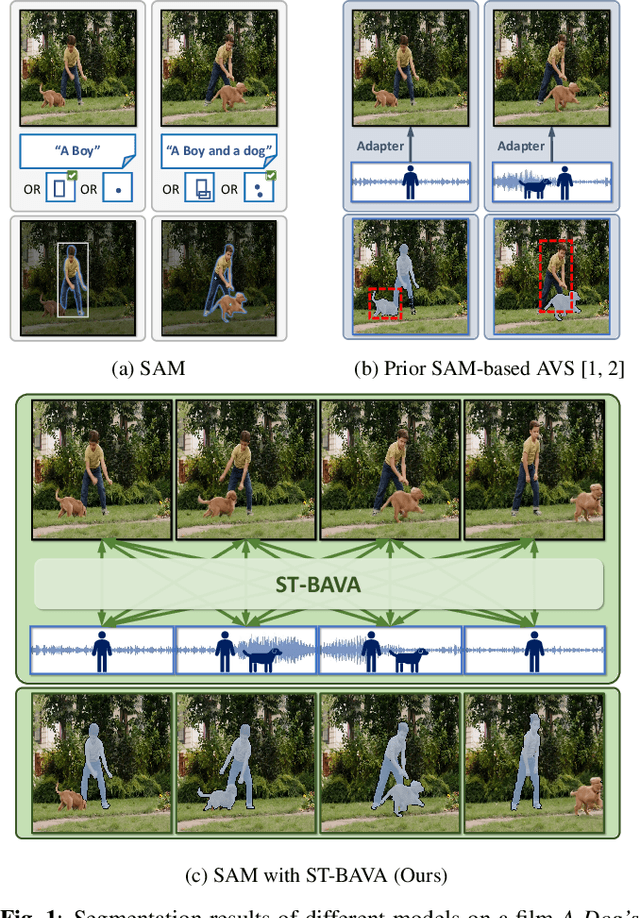
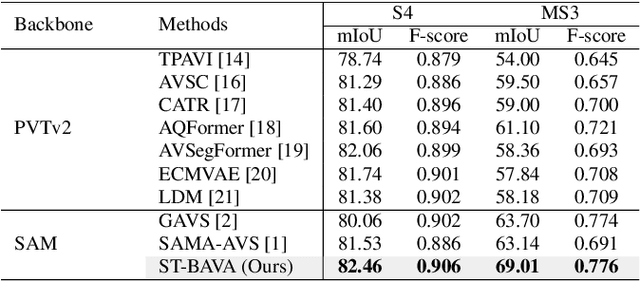
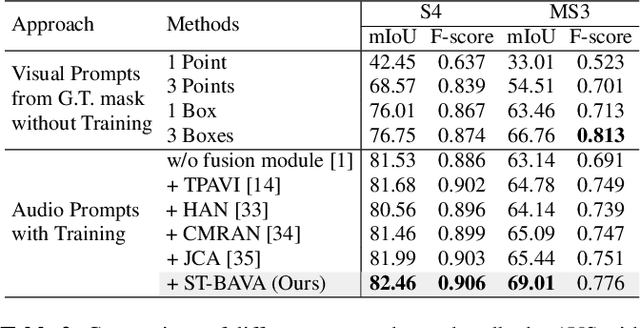
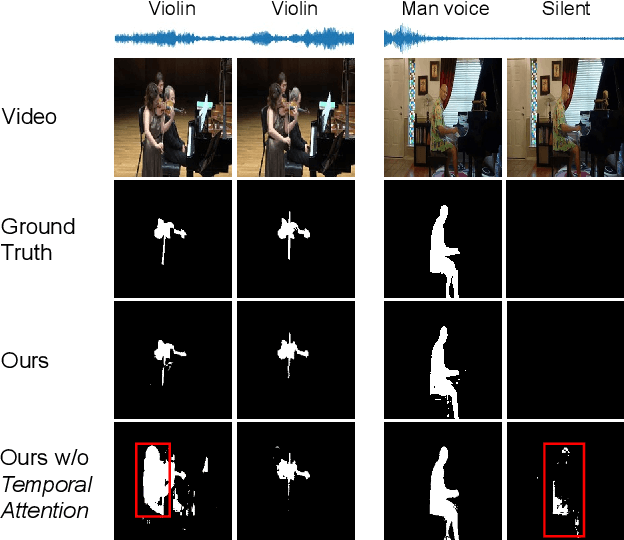
Audio-visual segmentation (AVS) aims to segment sound sources in the video sequence, requiring a pixel-level understanding of audio-visual correspondence. As the Segment Anything Model (SAM) has strongly impacted extensive fields of dense prediction problems, prior works have investigated the introduction of SAM into AVS with audio as a new modality of the prompt. Nevertheless, constrained by SAM's single-frame segmentation scheme, the temporal context across multiple frames of audio-visual data remains insufficiently utilized. To this end, we study the extension of SAM's capabilities to the sequence of audio-visual scenes by analyzing contextual cross-modal relationships across the frames. To achieve this, we propose a Spatio-Temporal, Bidirectional Audio-Visual Attention (ST-BAVA) module integrated into the middle of SAM's image encoder and mask decoder. It adaptively updates the audio-visual features to convey the spatio-temporal correspondence between the video frames and audio streams. Extensive experiments demonstrate that our proposed model outperforms the state-of-the-art methods on AVS benchmarks, especially with an 8.3% mIoU gain on a challenging multi-sources subset.
SemCity: Semantic Scene Generation with Triplane Diffusion
Mar 17, 2024



We present "SemCity," a 3D diffusion model for semantic scene generation in real-world outdoor environments. Most 3D diffusion models focus on generating a single object, synthetic indoor scenes, or synthetic outdoor scenes, while the generation of real-world outdoor scenes is rarely addressed. In this paper, we concentrate on generating a real-outdoor scene through learning a diffusion model on a real-world outdoor dataset. In contrast to synthetic data, real-outdoor datasets often contain more empty spaces due to sensor limitations, causing challenges in learning real-outdoor distributions. To address this issue, we exploit a triplane representation as a proxy form of scene distributions to be learned by our diffusion model. Furthermore, we propose a triplane manipulation that integrates seamlessly with our triplane diffusion model. The manipulation improves our diffusion model's applicability in a variety of downstream tasks related to outdoor scene generation such as scene inpainting, scene outpainting, and semantic scene completion refinements. In experimental results, we demonstrate that our triplane diffusion model shows meaningful generation results compared with existing work in a real-outdoor dataset, SemanticKITTI. We also show our triplane manipulation facilitates seamlessly adding, removing, or modifying objects within a scene. Further, it also enables the expansion of scenes toward a city-level scale. Finally, we evaluate our method on semantic scene completion refinements where our diffusion model enhances predictions of semantic scene completion networks by learning scene distribution. Our code is available at https://github.com/zoomin-lee/SemCity.
Diffusion Probabilistic Models for Scene-Scale 3D Categorical Data
Jan 02, 2023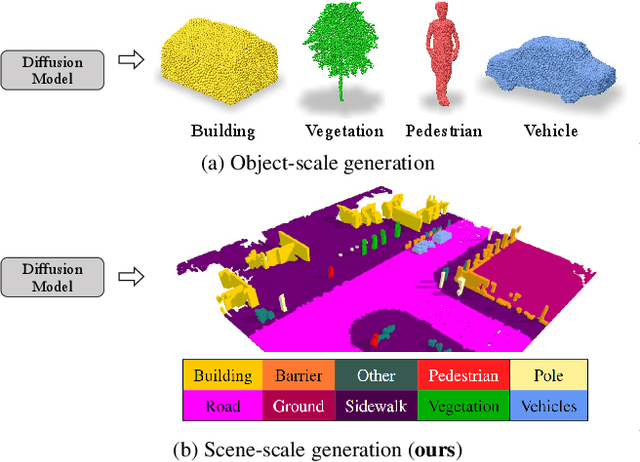
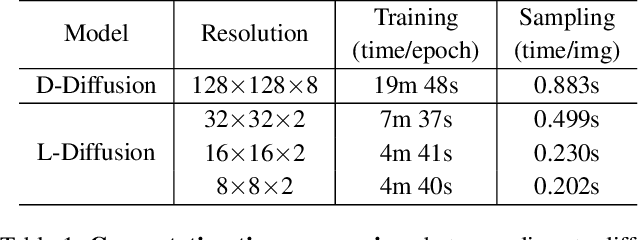
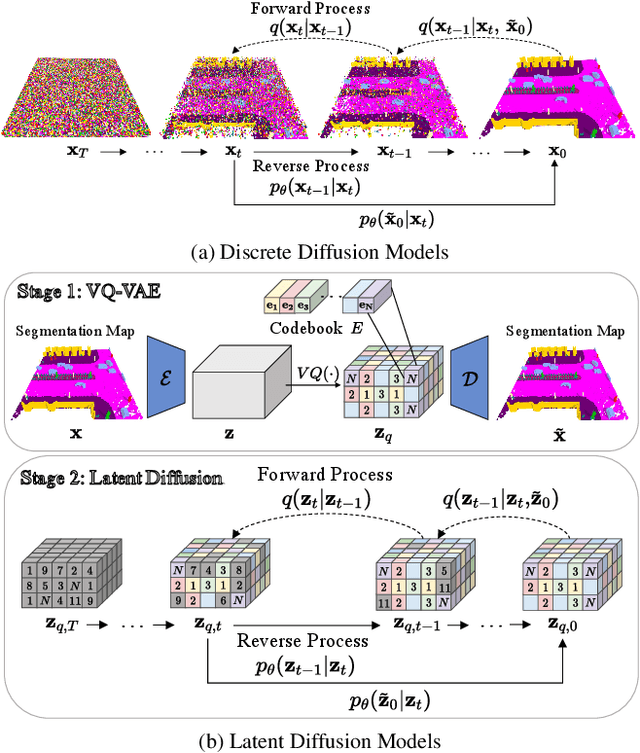
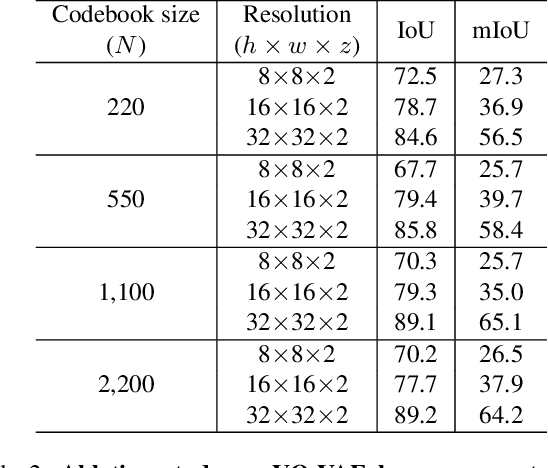
In this paper, we learn a diffusion model to generate 3D data on a scene-scale. Specifically, our model crafts a 3D scene consisting of multiple objects, while recent diffusion research has focused on a single object. To realize our goal, we represent a scene with discrete class labels, i.e., categorical distribution, to assign multiple objects into semantic categories. Thus, we extend discrete diffusion models to learn scene-scale categorical distributions. In addition, we validate that a latent diffusion model can reduce computation costs for training and deploying. To the best of our knowledge, our work is the first to apply discrete and latent diffusion for 3D categorical data on a scene-scale. We further propose to perform semantic scene completion (SSC) by learning a conditional distribution using our diffusion model, where the condition is a partial observation in a sparse point cloud. In experiments, we empirically show that our diffusion models not only generate reasonable scenes, but also perform the scene completion task better than a discriminative model. Our code and models are available at https://github.com/zoomin-lee/scene-scale-diffusion