 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOIGS: Human-Object Interaction Gaussian Splatting
Apr 05, 2026Reconstructing dynamic scenes with complex human-object interactions is a fundamental challenge in computer vision and graphics. Existing Gaussian Splatting methods either rely on human pose priors while neglecting dynamic objects, or approximate all motions within a single field, limiting their ability to capture interaction-rich dynamics. To address this gap, we propose Human-Object Interaction Gaussian Splatting (HOIGS), which explicitly models interaction-induced deformation between humans and objects through a cross-attention-based HOI module. Distinct deformation baselines are employed to extract features: HexPlane for humans and Cubic Hermite Spline (CHS) for objects. By integrating these heterogeneous features, HOIGS effectively captures interdependent motions and improves deformation estimation in scenarios involving occlusion, contact, and object manipulation. Comprehensive experiments on multiple datasets demonstrate that our method consistently outperforms state-of-the-art human-centric and 4D Gaussian approaches, highlighting the importance of explicitly modeling human-object interactions for high-fidelity reconstruction.
Video-Oasis: Rethinking Evaluation of Video Understanding
Mar 31, 2026The inherent complexity of video understanding makes it difficult to attribute whether performance gains stem from visual perception, linguistic reasoning, or knowledge priors. While many benchmarks have emerged to assess high-level reasoning, the essential criteria that constitute video understanding remain largely overlooked. Instead of introducing yet another benchmark, we take a step back to re-examine the current landscape of video understanding. In this work, we provide Video-Oasis, a sustainable diagnostic suite designed to systematically evaluate existing evaluations and distill spatio-temporal challenges for video understanding. Our analysis reveals two critical findings: (1) 54% of existing benchmark samples are solvable without visual input or temporal context, and (2) on the remaining samples, state-of-the-art models exhibit performance barely exceeding random guessing. To bridge this gap, we investigate which algorithmic design choices contribute to robust video understanding, providing practical guidelines for future research. We hope our work serves as a standard guideline for benchmark construction and the rigorous evaluation of architecture development. Code is available at https://github.com/sejong-rcv/Video-Oasis.
Coherent Human-Scene Reconstruction from Multi-Person Multi-View Video in a Single Pass
Mar 13, 2026Recent advances in 3D foundation models have led to growing interest in reconstructing humans and their surrounding environments. However, most existing approaches focus on monocular inputs, and extending them to multi-view settings requires additional overhead modules or preprocessed data. To this end, we present CHROMM, a unified framework that jointly estimates cameras, scene point clouds, and human meshes from multi-person multi-view videos without relying on external modules or preprocessing. We integrate strong geometric and human priors from Pi3X and Multi-HMR into a single trainable neural network architecture, and introduce a scale adjustment module to solve the scale discrepancy between humans and the scene. We also introduce a multi-view fusion strategy to aggregate per-view estimates into a single representation at test-time. Finally, we propose a geometry-based multi-person association method, which is more robust than appearance-based approaches. Experiments on EMDB, RICH, EgoHumans, and EgoExo4D show that CHROMM achieves competitive performance in global human motion and multi-view pose estimation while running over 8x faster than prior optimization-based multi-view approaches. Project page: https://nstar1125.github.io/chromm.
SeaCache: Spectral-Evolution-Aware Cache for Accelerating Diffusion Models
Feb 22, 2026Diffusion models are a strong backbone for visual generation, but their inherently sequential denoising process leads to slow inference. Previous methods accelerate sampling by caching and reusing intermediate outputs based on feature distances between adjacent timesteps. However, existing caching strategies typically rely on raw feature differences that entangle content and noise. This design overlooks spectral evolution, where low-frequency structure appears early and high-frequency detail is refined later. We introduce Spectral-Evolution-Aware Cache (SeaCache), a training-free cache schedule that bases reuse decisions on a spectrally aligned representation. Through theoretical and empirical analysis, we derive a Spectral-Evolution-Aware (SEA) filter that preserves content-relevant components while suppressing noise. Employing SEA-filtered input features to estimate redundancy leads to dynamic schedules that adapt to content while respecting the spectral priors underlying the diffusion model. Extensive experiments on diverse visual generative models and the baselines show that SeaCache achieves state-of-the-art latency-quality trade-offs.
Why Can't I Open My Drawer? Mitigating Object-Driven Shortcuts in Zero-Shot Compositional Action Recognition
Jan 22, 2026We study Compositional Video Understanding (CVU), where models must recognize verbs and objects and compose them to generalize to unseen combinations. We find that existing Zero-Shot Compositional Action Recognition (ZS-CAR) models fail primarily due to an overlooked failure mode: object-driven verb shortcuts. Through systematic analysis, we show that this behavior arises from two intertwined factors: severe sparsity and skewness of compositional supervision, and the asymmetric learning difficulty between verbs and objects. As training progresses, the existing ZS-CAR model increasingly ignores visual evidence and overfits to co-occurrence statistics. Consequently, the existing model does not gain the benefit of compositional recognition in unseen verb-object compositions. To address this, we propose RCORE, a simple and effective framework that enforces temporally grounded verb learning. RCORE introduces (i) a composition-aware augmentation that diversifies verb-object combinations without corrupting motion cues, and (ii) a temporal order regularization loss that penalizes shortcut behaviors by explicitly modeling temporal structure. Across two benchmarks, Sth-com and our newly constructed EK100-com, RCORE significantly improves unseen composition accuracy, reduces reliance on co-occurrence bias, and achieves consistently positive compositional gaps. Our findings reveal object-driven shortcuts as a critical limiting factor in ZS-CAR and demonstrate that addressing them is essential for robust compositional video understanding.
Multi-Granular Spatio-Temporal Token Merging for Training-Free Acceleration of Video LLMs
Jul 10, 2025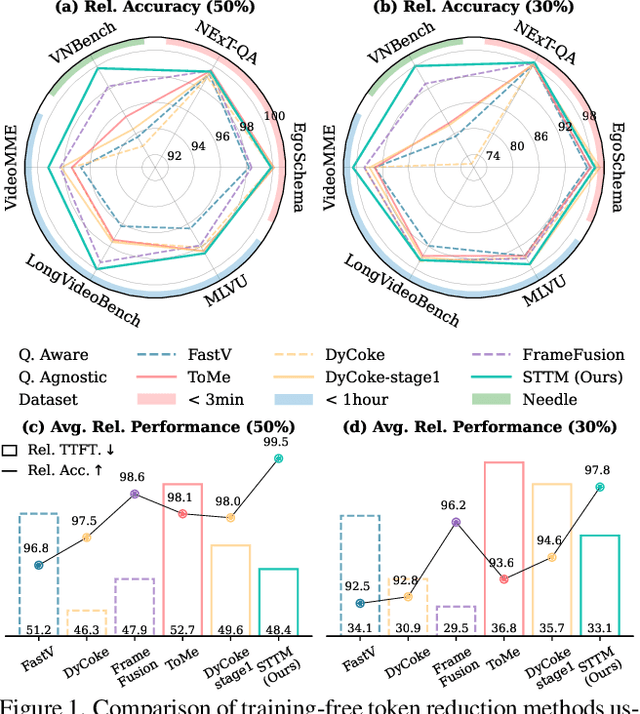

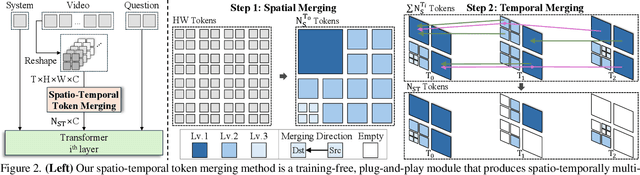

Video large language models (LLMs) achieve strong video understanding by leveraging a large number of spatio-temporal tokens, but suffer from quadratic computational scaling with token count. To address this, we propose a training-free spatio-temporal token merging method, named STTM. Our key insight is to exploit local spatial and temporal redundancy in video data which has been overlooked in prior work. STTM first transforms each frame into multi-granular spatial tokens using a coarse-to-fine search over a quadtree structure, then performs directed pairwise merging across the temporal dimension. This decomposed merging approach outperforms existing token reduction methods across six video QA benchmarks. Notably, STTM achieves a 2$\times$ speed-up with only a 0.5% accuracy drop under a 50% token budget, and a 3$\times$ speed-up with just a 2% drop under a 30% budget. Moreover, STTM is query-agnostic, allowing KV cache reuse across different questions for the same video. The project page is available at https://www.jshyun.me/projects/sttm.
Prototypes are Balanced Units for Efficient and Effective Partially Relevant Video Retrieval
Apr 17, 2025In a retrieval system, simultaneously achieving search accuracy and efficiency is inherently challenging. This challenge is particularly pronounced in partially relevant video retrieval (PRVR), where incorporating more diverse context representations at varying temporal scales for each video enhances accuracy but increases computational and memory costs. To address this dichotomy, we propose a prototypical PRVR framework that encodes diverse contexts within a video into a fixed number of prototypes. We then introduce several strategies to enhance text association and video understanding within the prototypes, along with an orthogonal objective to ensure that the prototypes capture a diverse range of content. To keep the prototypes searchable via text queries while accurately encoding video contexts, we implement cross- and uni-modal reconstruction tasks. The cross-modal reconstruction task aligns the prototypes with textual features within a shared space, while the uni-modal reconstruction task preserves all video contexts during encoding. Additionally, we employ a video mixing technique to provide weak guidance to further align prototypes and associated textual representations. Extensive evaluations on TVR, ActivityNet-Captions, and QVHighlights validate the effectiveness of our approach without sacrificing efficiency.
CoMoGaussian: Continuous Motion-Aware Gaussian Splatting from Motion-Blurred Images
Mar 07, 20253D Gaussian Splatting (3DGS) has gained significant attention for their high-quality novel view rendering, motivating research to address real-world challenges. A critical issue is the camera motion blur caused by movement during exposure, which hinders accurate 3D scene reconstruction. In this study, we propose CoMoGaussian, a Continuous Motion-Aware Gaussian Splatting that reconstructs precise 3D scenes from motion-blurred images while maintaining real-time rendering speed. Considering the complex motion patterns inherent in real-world camera movements, we predict continuous camera trajectories using neural ordinary differential equations (ODEs). To ensure accurate modeling, we employ rigid body transformations, preserving the shape and size of the object but rely on the discrete integration of sampled frames. To better approximate the continuous nature of motion blur, we introduce a continuous motion refinement (CMR) transformation that refines rigid transformations by incorporating additional learnable parameters. By revisiting fundamental camera theory and leveraging advanced neural ODE techniques, we achieve precise modeling of continuous camera trajectories, leading to improved reconstruction accuracy. Extensive experiments demonstrate state-of-the-art performance both quantitatively and qualitatively on benchmark datasets, which include a wide range of motion blur scenarios, from moderate to extreme blur.
Humans as a Calibration Pattern: Dynamic 3D Scene Reconstruction from Unsynchronized and Uncalibrated Videos
Dec 26, 2024



Recent works on dynamic neural field reconstruction assume input from synchronized multi-view videos with known poses. These input constraints are often unmet in real-world setups, making the approach impractical. We demonstrate that unsynchronized videos with unknown poses can generate dynamic neural fields if the videos capture human motion. Humans are one of the most common dynamic subjects whose poses can be estimated using state-of-the-art methods. While noisy, the estimated human shape and pose parameters provide a decent initialization for the highly non-convex and under-constrained problem of training a consistent dynamic neural representation. Given the sequences of pose and shape of humans, we estimate the time offsets between videos, followed by camera pose estimations by analyzing 3D joint locations. Then, we train dynamic NeRF employing multiresolution rids while simultaneously refining both time offsets and camera poses. The setup still involves optimizing many parameters, therefore, we introduce a robust progressive learning strategy to stabilize the process. Experiments show that our approach achieves accurate spatiotemporal calibration and high-quality scene reconstruction in challenging conditions.
CoCoGaussian: Leveraging Circle of Confusion for Gaussian Splatting from Defocused Images
Dec 20, 2024



3D Gaussian Splatting (3DGS) has attracted significant attention for its high-quality novel view rendering, inspiring research to address real-world challenges. While conventional methods depend on sharp images for accurate scene reconstruction, real-world scenarios are often affected by defocus blur due to finite depth of field, making it essential to account for realistic 3D scene representation. In this study, we propose CoCoGaussian, a Circle of Confusion-aware Gaussian Splatting that enables precise 3D scene representation using only defocused images. CoCoGaussian addresses the challenge of defocus blur by modeling the Circle of Confusion (CoC) through a physically grounded approach based on the principles of photographic defocus. Exploiting 3D Gaussians, we compute the CoC diameter from depth and learnable aperture information, generating multiple Gaussians to precisely capture the CoC shape. Furthermore, we introduce a learnable scaling factor to enhance robustness and provide more flexibility in handling unreliable depth in scenes with reflective or refractive surfaces. Experiments on both synthetic and real-world datasets demonstrate that CoCoGaussian achieves state-of-the-art performance across multiple benchmarks.