 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Driven Incremental Compression for Multi-Turn Dialogue Generation
Jun 10, 2026Modern conversational agents condition on an ever-growing dialogue history at each turn, incurring redundant attention and encoding costs that grow with conversation length. Naive truncation or summarization degrades fidelity, while existing context compressors lack cross-turn memory sharing or revision, causing information loss and compounding errors in long dialogues. We revisit the context compression under conversational dynamics and empirically present its fragility. To improve both efficiency and robustness, we introduce Context-Driven Incremental Compression (C-DIC), which treats a conversation as interleaved contextual threads and stores revisable per-thread compression states in a single, compact dialogue memory. At each turn, a lightweight retrieve, revise, and write-back loop shares information across turns and updates stale memories, stabilizing long-horizon behavior. In addition, we adapt truncated backpropagation-through-time (TBPTT) to our multi-turn setting, learning cross-turn dependencies without full-history backpropagation. Extensive experiments on long-form dialogue benchmarks demonstrate superior performance and efficiency of C-DIC; notably, C-DIC shows stable inference latency and perplexity over hundreds of dialogue turns, supporting a scalable path to high-quality dialogue modeling.
A Surveillance Evasion Game with Continuous Sensor Redeployment via Bilevel Optimization
May 27, 2026Uncrewed Aerial Systems (UASs) have become a growing threat to the security of critical infrastructure, exploiting spatiotemporal gaps in sensor perimeters to infiltrate restricted airspace undetected. We formulate this interaction as a two-player zero-sum differential game between an adversarial UAS and a heterogeneous sensor network of directional and omnidirectional sensors. Unlike earlier game-theoretic approaches that restrict the defender to discrete placement graphs or fixed configurations, we introduce a continuous sensor redeployment technique in which each sensor slides freely along the convex building boundaries. This is enforced via a log-sum-exp smooth approximation that preserves differentiability at polygon vertices, enabling optimization with gradient-based methods. The attacker's best response is computed via a two-step approach combining STP-RRT* for feasible trajectory initialization and nonlinear programming for detection-minimization refinement. The joint optimization converges to a Local Nash Equilibrium (LNE) via alternating bilevel optimization, with analytical first-order stationarity conditions derived for both players, thereby establishing a deployable baseline for heterogeneous sensor placements in CUAS missions.
Motion-Oriented Compositional Neural Radiance Fields for Monocular Dynamic Human Modeling
Jul 16, 2024



This paper introduces Motion-oriented Compositional Neural Radiance Fields (MoCo-NeRF), a framework designed to perform free-viewpoint rendering of monocular human videos via novel non-rigid motion modeling approach. In the context of dynamic clothed humans, complex cloth dynamics generate non-rigid motions that are intrinsically distinct from skeletal articulations and critically important for the rendering quality. The conventional approach models non-rigid motions as spatial (3D) deviations in addition to skeletal transformations. However, it is either time-consuming or challenging to achieve optimal quality due to its high learning complexity without a direct supervision. To target this problem, we propose a novel approach of modeling non-rigid motions as radiance residual fields to benefit from more direct color supervision in the rendering and utilize the rigid radiance fields as a prior to reduce the complexity of the learning process. Our approach utilizes a single multiresolution hash encoding (MHE) to concurrently learn the canonical T-pose representation from rigid skeletal motions and the radiance residual field for non-rigid motions. Additionally, to further improve both training efficiency and usability, we extend MoCo-NeRF to support simultaneous training of multiple subjects within a single framework, thanks to our effective design for modeling non-rigid motions. This scalability is achieved through the integration of a global MHE and learnable identity codes in addition to multiple local MHEs. We present extensive results on ZJU-MoCap and MonoCap, clearly demonstrating state-of-the-art performance in both single- and multi-subject settings. The code and model will be made publicly available at the project page: https://stevejaehyeok.github.io/publications/moco-nerf.
MIXED-SENSE: A Mixed Reality Sensor Emulation Framework for Test and Evaluation of UAVs Against False Data Injection Attacks
Jul 12, 2024
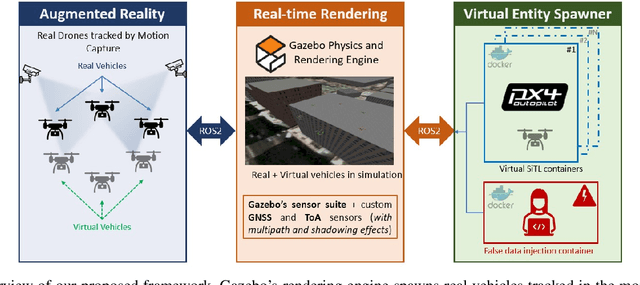
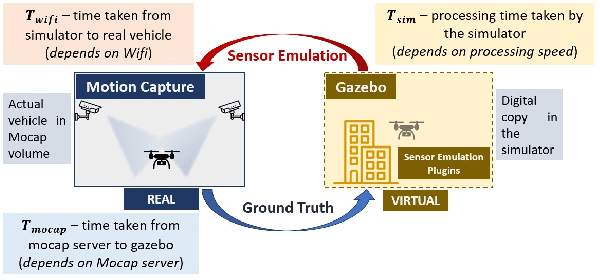

We present a high-fidelity Mixed Reality sensor emulation framework for testing and evaluating the resilience of Unmanned Aerial Vehicles (UAVs) against false data injection (FDI) attacks. The proposed approach can be utilized to assess the impact of FDI attacks, benchmark attack detector performance, and validate the effectiveness of mitigation/reconfiguration strategies in single-UAV and UAV swarm operations. Our Mixed Reality framework leverages high-fidelity simulations of Gazebo and a Motion Capture system to emulate proprioceptive (e.g., GNSS) and exteroceptive (e.g., camera) sensor measurements in real-time. We propose an empirical approach to faithfully recreate signal characteristics such as latency and noise in these measurements. Finally, we illustrate the efficacy of our proposed framework through a Mixed Reality experiment consisting of an emulated GNSS attack on an actual UAV, which (i) demonstrates the impact of false data injection attacks on GNSS measurements and (ii) validates a mitigation strategy utilizing a distributed camera network developed in our previous work. Our open-source implementation is available at \href{https://github.com/CogniPilot/mixed\_sense}{\texttt{https://github.com/CogniPilot/mixed\_sense}}
You Only Train Once: Multi-Identity Free-Viewpoint Neural Human Rendering from Monocular Videos
Mar 10, 2023We introduce You Only Train Once (YOTO), a dynamic human generation framework, which performs free-viewpoint rendering of different human identities with distinct motions, via only one-time training from monocular videos. Most prior works for the task require individualized optimization for each input video that contains a distinct human identity, leading to a significant amount of time and resources for the deployment, thereby impeding the scalability and the overall application potential of the system. In this paper, we tackle this problem by proposing a set of learnable identity codes to expand the capability of the framework for multi-identity free-viewpoint rendering, and an effective pose-conditioned code query mechanism to finely model the pose-dependent non-rigid motions. YOTO optimizes neural radiance fields (NeRF) by utilizing designed identity codes to condition the model for learning various canonical T-pose appearances in a single shared volumetric representation. Besides, our joint learning of multiple identities within a unified model incidentally enables flexible motion transfer in high-quality photo-realistic renderings for all learned appearances. This capability expands its potential use in important applications, including Virtual Reality. We present extensive experimental results on ZJU-MoCap and PeopleSnapshot to clearly demonstrate the effectiveness of our proposed model. YOTO shows state-of-the-art performance on all evaluation metrics while showing significant benefits in training and inference efficiency as well as rendering quality. The code and model will be made publicly available soon.