 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHide to See: Reasoning-prefix Masking for Visual-anchored Thinking in VLM Distillation
May 13, 2026Recent think-answer approaches in VLMs, such as Qwen3-VL-Thinking, boost reasoning performance by leveraging intermediate thinking steps before the final answer, but their high computational cost limits real-world deployment. To distill such capabilities into compact think-answer VLMs, a primary objective is to improve the student's ability to utilize visual evidence throughout its reasoning trace. To this end, we introduce a novel think-answer distillation framework that encourages the student to anchor its thinking on visual information by masking the student's salient reasoning prefixes. To compensate for such masked textual cues, the student is encouraged to rely more on visual evidence as an alternative source of information during distillation. Our masking strategies include: 1) token-wise salient reasoning-prefix masking, which masks high-influence reasoning prefixes selectively for each next-token prediction, and 2) self-paced masking budget scheduling, which gradually increases the masking scale according to distillation difficulty, {measured by discrepancy between teacher--student distributions. In the distillation phase, the student is guided by our salient reasoning-prefix mask, which blocks both future tokens and salient reasoning cues, in place of the standard causal mask used for auto-regressive language modeling. Experimental results show that our approach outperforms recent open-source VLMs, VLM distillation, and self-distillation methods on multimodal reasoning benchmarks, while further analyses confirm enhanced visual utilization along the student thinking process.
Single-Teacher View Augmentation: Boosting Knowledge Distillation via Angular Diversity
Oct 26, 2025Knowledge Distillation (KD) aims to train a lightweight student model by transferring knowledge from a large, high-capacity teacher. Recent studies have shown that leveraging diverse teacher perspectives can significantly improve distillation performance; however, achieving such diversity typically requires multiple teacher networks, leading to high computational costs. In this work, we propose a novel cost-efficient knowledge augmentation method for KD that generates diverse multi-views by attaching multiple branches to a single teacher. To ensure meaningful semantic variation across multi-views, we introduce two angular diversity objectives: 1) constrained inter-angle diversify loss, which maximizes angles between augmented views while preserving proximity to the original teacher output, and 2) intra-angle diversify loss, which encourages an even distribution of views around the original output. The ensembled knowledge from these angularly diverse views, along with the original teacher, is distilled into the student. We further theoretically demonstrate that our objectives increase the diversity among ensemble members and thereby reduce the upper bound of the ensemble's expected loss, leading to more effective distillation. Experimental results show that our method surpasses an existing knowledge augmentation method across diverse configurations. Moreover, the proposed method is compatible with other KD frameworks in a plug-and-play fashion, providing consistent improvements in generalization performance.
Latent Expression Generation for Referring Image Segmentation and Grounding
Aug 07, 2025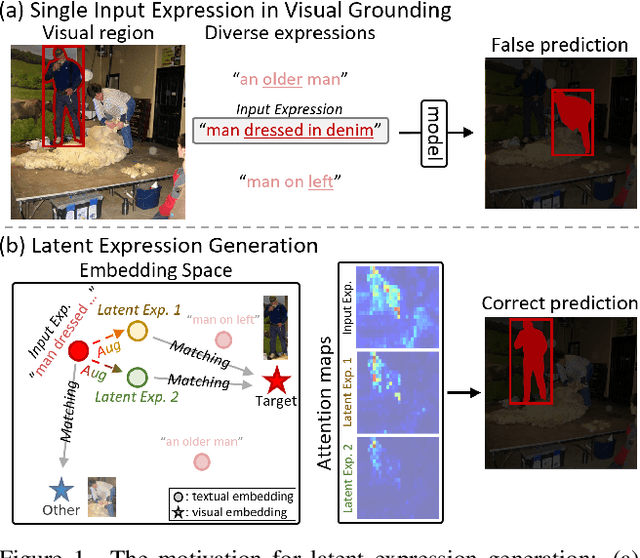
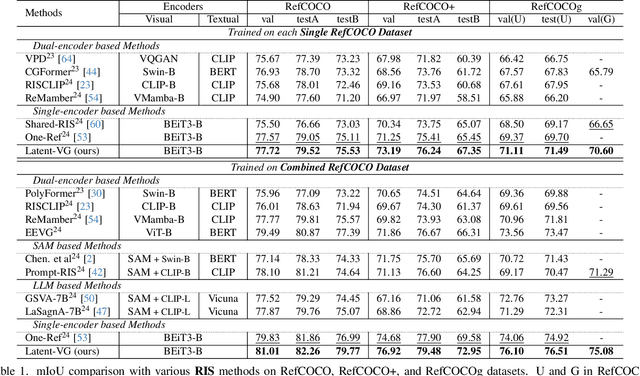
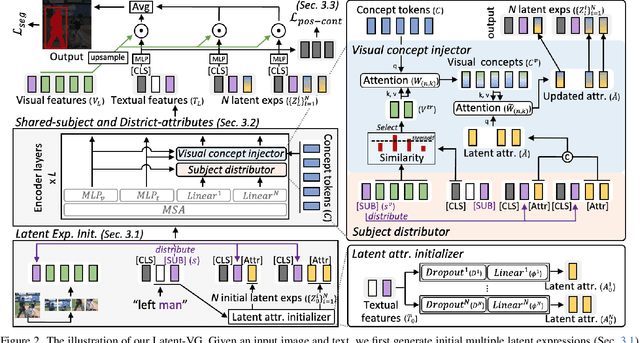
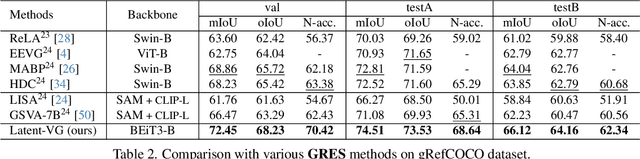
Visual grounding tasks, such as referring image segmentation (RIS) and referring expression comprehension (REC), aim to localize a target object based on a given textual description. The target object in an image can be described in multiple ways, reflecting diverse attributes such as color, position, and more. However, most existing methods rely on a single textual input, which captures only a fraction of the rich information available in the visual domain. This mismatch between rich visual details and sparse textual cues can lead to the misidentification of similar objects. To address this, we propose a novel visual grounding framework that leverages multiple latent expressions generated from a single textual input by incorporating complementary visual details absent from the original description. Specifically, we introduce subject distributor and visual concept injector modules to embed both shared-subject and distinct-attributes concepts into the latent representations, thereby capturing unique and target-specific visual cues. We also propose a positive-margin contrastive learning strategy to align all latent expressions with the original text while preserving subtle variations. Experimental results show that our method not only outperforms state-of-the-art RIS and REC approaches on multiple benchmarks but also achieves outstanding performance on the generalized referring expression segmentation (GRES) benchmark.
A Simple Baseline with Single-encoder for Referring Image Segmentation
Aug 28, 2024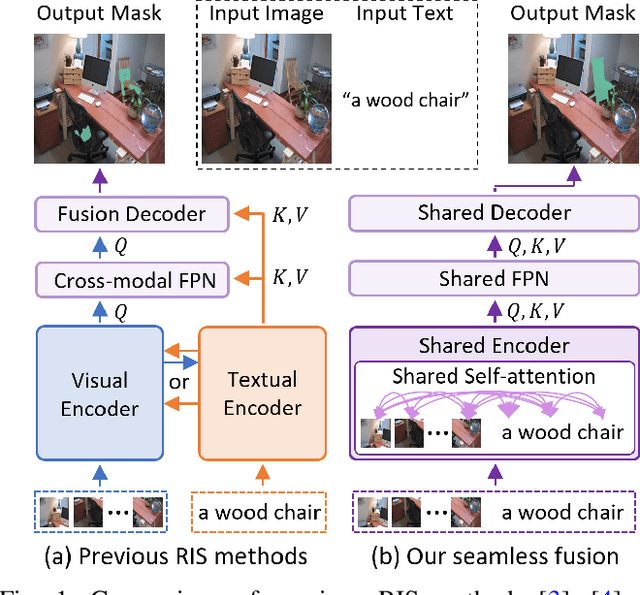
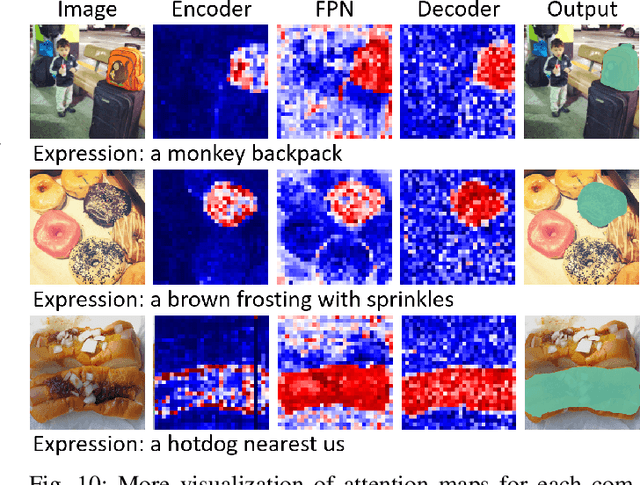


Referring image segmentation (RIS) requires dense vision-language interactions between visual pixels and textual words to segment objects based on a given description. However, commonly adapted dual-encoders in RIS, e.g., Swin transformer and BERT (uni-modal encoders) or CLIP (a multi-modal dual-encoder), lack dense multi-modal interactions during pre-training, leading to a gap with a pixel-level RIS task. To bridge this gap, existing RIS methods often rely on multi-modal fusion modules that interact two encoders, but this approach leads to high computational costs. In this paper, we present a novel RIS method with a single-encoder, i.e., BEiT-3, maximizing the potential of shared self-attention across all framework components. This enables seamless interactions of two modalities from input to final prediction, producing granularly aligned multi-modal features. Furthermore, we propose lightweight yet effective decoder modules, a Shared FPN and a Shared Mask Decoder, which contribute to the high efficiency of our model. Our simple baseline with a single encoder achieves outstanding performances on the RIS benchmark datasets while maintaining computational efficiency, compared to the most recent SoTA methods based on dual-encoders.
Pseudo-RIS: Distinctive Pseudo-supervision Generation for Referring Image Segmentation
Jul 10, 2024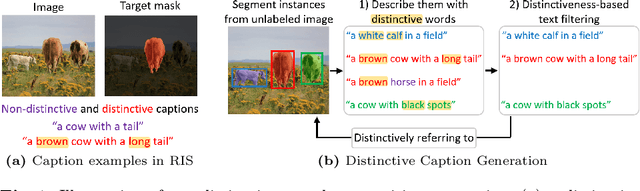
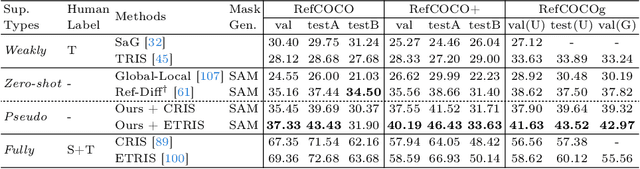
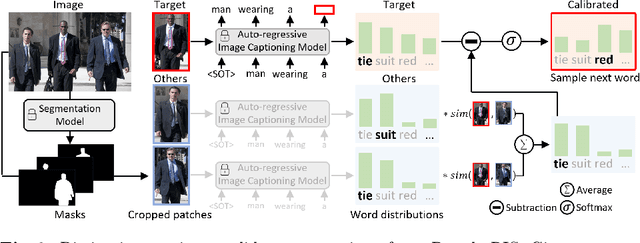
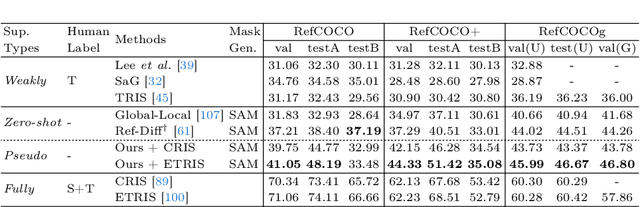
We propose a new framework that automatically generates high-quality segmentation masks with their referring expressions as pseudo supervisions for referring image segmentation (RIS). These pseudo supervisions allow the training of any supervised RIS methods without the cost of manual labeling. To achieve this, we incorporate existing segmentation and image captioning foundation models, leveraging their broad generalization capabilities. However, the naive incorporation of these models may generate non-distinctive expressions that do not distinctively refer to the target masks. To address this challenge, we propose two-fold strategies that generate distinctive captions: 1) 'distinctive caption sampling', a new decoding method for the captioning model, to generate multiple expression candidates with detailed words focusing on the target. 2) 'distinctiveness-based text filtering' to further validate the candidates and filter out those with a low level of distinctiveness. These two strategies ensure that the generated text supervisions can distinguish the target from other objects, making them appropriate for the RIS annotations. Our method significantly outperforms both weakly and zero-shot SoTA methods on the RIS benchmark datasets. It also surpasses fully supervised methods in unseen domains, proving its capability to tackle the open-world challenge within RIS. Furthermore, integrating our method with human annotations yields further improvements, highlighting its potential in semi-supervised learning applications.
Zero-shot Referring Image Segmentation with Global-Local Context Features
Apr 03, 2023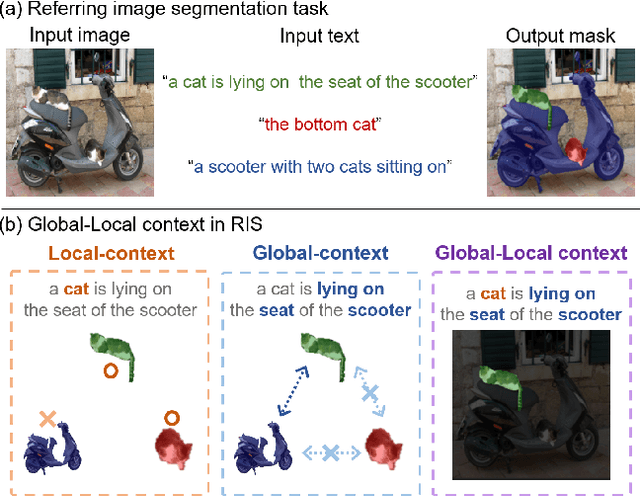
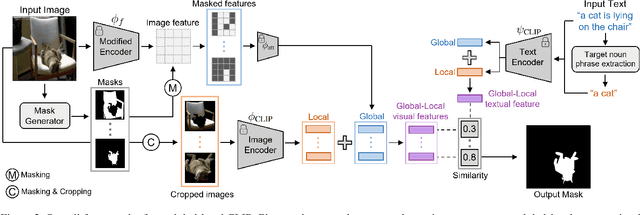
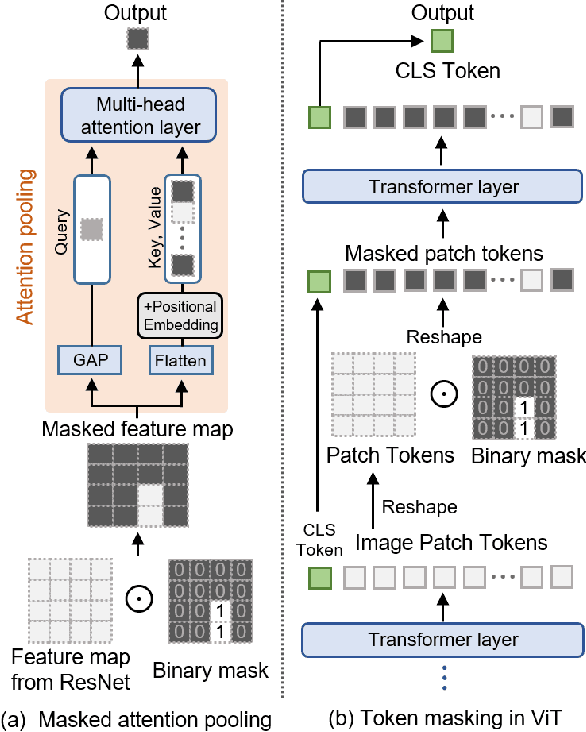
Referring image segmentation (RIS) aims to find a segmentation mask given a referring expression grounded to a region of the input image. Collecting labelled datasets for this task, however, is notoriously costly and labor-intensive. To overcome this issue, we propose a simple yet effective zero-shot referring image segmentation method by leveraging the pre-trained cross-modal knowledge from CLIP. In order to obtain segmentation masks grounded to the input text, we propose a mask-guided visual encoder that captures global and local contextual information of an input image. By utilizing instance masks obtained from off-the-shelf mask proposal techniques, our method is able to segment fine-detailed Istance-level groundings. We also introduce a global-local text encoder where the global feature captures complex sentence-level semantics of the entire input expression while the local feature focuses on the target noun phrase extracted by a dependency parser. In our experiments, the proposed method outperforms several zero-shot baselines of the task and even the weakly supervised referring expression segmentation method with substantial margins. Our code is available at https://github.com/Seonghoon-Yu/Zero-shot-RIS.