 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Baseline with Single-encoder for Referring Image Segmentation
Paper and Code
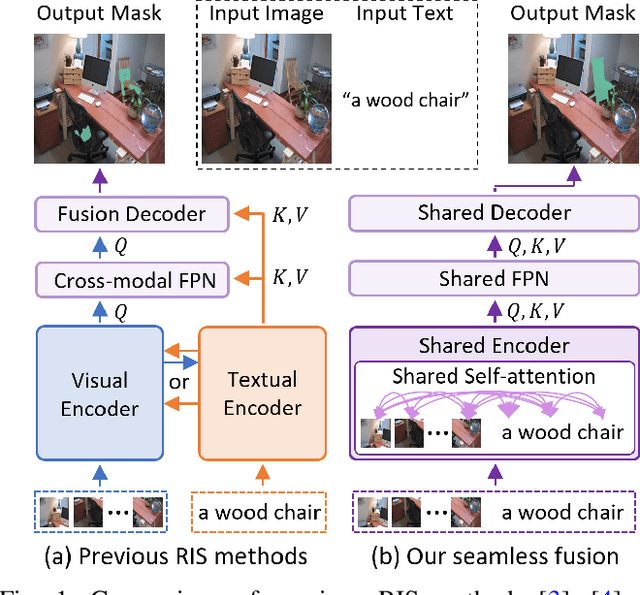


Referring image segmentation (RIS) requires dense vision-language interactions between visual pixels and textual words to segment objects based on a given description. However, commonly adapted dual-encoders in RIS, e.g., Swin transformer and BERT (uni-modal encoders) or CLIP (a multi-modal dual-encoder), lack dense multi-modal interactions during pre-training, leading to a gap with a pixel-level RIS task. To bridge this gap, existing RIS methods often rely on multi-modal fusion modules that interact two encoders, but this approach leads to high computational costs. In this paper, we present a novel RIS method with a single-encoder, i.e., BEiT-3, maximizing the potential of shared self-attention across all framework components. This enables seamless interactions of two modalities from input to final prediction, producing granularly aligned multi-modal features. Furthermore, we propose lightweight yet effective decoder modules, a Shared FPN and a Shared Mask Decoder, which contribute to the high efficiency of our model. Our simple baseline with a single encoder achieves outstanding performances on the RIS benchmark datasets while maintaining computational efficiency, compared to the most recent SoTA methods based on dual-encoders.