 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIAR: Diffusion-model-guided Implicit Q-learning with Adaptive Revaluation
Oct 15, 2024



We propose a novel offline reinforcement learning (offline RL) approach, introducing the Diffusion-model-guided Implicit Q-learning with Adaptive Revaluation (DIAR) framework. We address two key challenges in offline RL: out-of-distribution samples and long-horizon problems. We leverage diffusion models to learn state-action sequence distributions and incorporate value functions for more balanced and adaptive decision-making. DIAR introduces an Adaptive Revaluation mechanism that dynamically adjusts decision lengths by comparing current and future state values, enabling flexible long-term decision-making. Furthermore, we address Q-value overestimation by combining Q-network learning with a value function guided by a diffusion model. The diffusion model generates diverse latent trajectories, enhancing policy robustness and generalization. As demonstrated in tasks like Maze2D, AntMaze, and Kitchen, DIAR consistently outperforms state-of-the-art algorithms in long-horizon, sparse-reward environments.
Diffusion-Based Offline RL for Improved Decision-Making in Augmented ARC Task
Oct 15, 2024



Effective long-term strategies enable AI systems to navigate complex environments by making sequential decisions over extended horizons. Similarly, reinforcement learning (RL) agents optimize decisions across sequences to maximize rewards, even without immediate feedback. To verify that Latent Diffusion-Constrained Q-learning (LDCQ), a prominent diffusion-based offline RL method, demonstrates strong reasoning abilities in multi-step decision-making, we aimed to evaluate its performance on the Abstraction and Reasoning Corpus (ARC). However, applying offline RL methodologies to enhance strategic reasoning in AI for solving tasks in ARC is challenging due to the lack of sufficient experience data in the ARC training set. To address this limitation, we introduce an augmented offline RL dataset for ARC, called Synthesized Offline Learning Data for Abstraction and Reasoning (SOLAR), along with the SOLAR-Generator, which generates diverse trajectory data based on predefined rules. SOLAR enables the application of offline RL methods by offering sufficient experience data. We synthesized SOLAR for a simple task and used it to train an agent with the LDCQ method. Our experiments demonstrate the effectiveness of the offline RL approach on a simple ARC task, showing the agent's ability to make multi-step sequential decisions and correctly identify answer states. These results highlight the potential of the offline RL approach to enhance AI's strategic reasoning capabilities.
A Simple Baseline with Single-encoder for Referring Image Segmentation
Aug 28, 2024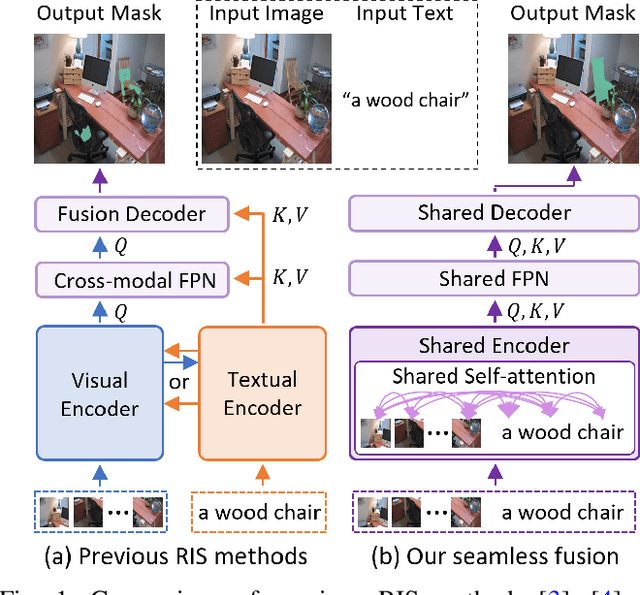
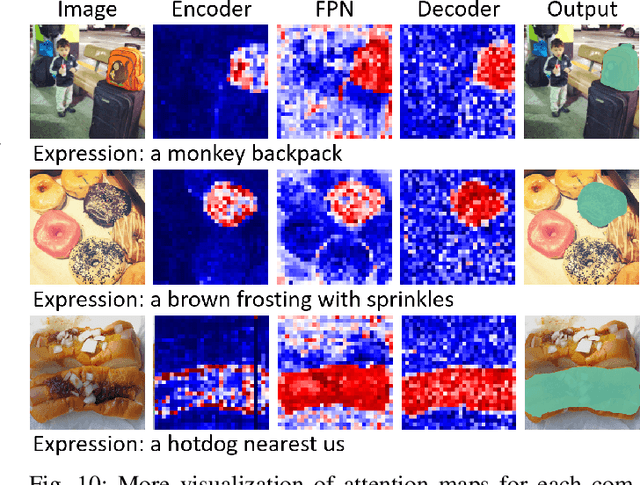


Referring image segmentation (RIS) requires dense vision-language interactions between visual pixels and textual words to segment objects based on a given description. However, commonly adapted dual-encoders in RIS, e.g., Swin transformer and BERT (uni-modal encoders) or CLIP (a multi-modal dual-encoder), lack dense multi-modal interactions during pre-training, leading to a gap with a pixel-level RIS task. To bridge this gap, existing RIS methods often rely on multi-modal fusion modules that interact two encoders, but this approach leads to high computational costs. In this paper, we present a novel RIS method with a single-encoder, i.e., BEiT-3, maximizing the potential of shared self-attention across all framework components. This enables seamless interactions of two modalities from input to final prediction, producing granularly aligned multi-modal features. Furthermore, we propose lightweight yet effective decoder modules, a Shared FPN and a Shared Mask Decoder, which contribute to the high efficiency of our model. Our simple baseline with a single encoder achieves outstanding performances on the RIS benchmark datasets while maintaining computational efficiency, compared to the most recent SoTA methods based on dual-encoders.
Learning Semantic Traversability with Egocentric Video and Automated Annotation Strategy
Jun 05, 2024For reliable autonomous robot navigation in urban settings, the robot must have the ability to identify semantically traversable terrains in the image based on the semantic understanding of the scene. This reasoning ability is based on semantic traversability, which is frequently achieved using semantic segmentation models fine-tuned on the testing domain. This fine-tuning process often involves manual data collection with the target robot and annotation by human labelers which is prohibitively expensive and unscalable. In this work, we present an effective methodology for training a semantic traversability estimator using egocentric videos and an automated annotation process. Egocentric videos are collected from a camera mounted on a pedestrian's chest. The dataset for training the semantic traversability estimator is then automatically generated by extracting semantically traversable regions in each video frame using a recent foundation model in image segmentation and its prompting technique. Extensive experiments with videos taken across several countries and cities, covering diverse urban scenarios, demonstrate the high scalability and generalizability of the proposed annotation method. Furthermore, performance analysis and real-world deployment for autonomous robot navigation showcase that the trained semantic traversability estimator is highly accurate, able to handle diverse camera viewpoints, computationally light, and real-world applicable. The summary video is available at https://youtu.be/EUVoH-wA-lA.
Improved weight initialization for deep and narrow feedforward neural network
Nov 07, 2023



Appropriate weight initialization settings, along with the ReLU activation function, have been a cornerstone of modern deep learning, making it possible to train and deploy highly effective and efficient neural network models across diverse artificial intelligence. The problem of dying ReLU, where ReLU neurons become inactive and yield zero output, presents a significant challenge in the training of deep neural networks with ReLU activation function. Theoretical research and various methods have been introduced to address the problem. However, even with these methods and research, training remains challenging for extremely deep and narrow feedforward networks with ReLU activation function. In this paper, we propose a new weight initialization method to address this issue. We prove the properties of the proposed initial weight matrix and demonstrate how these properties facilitate the effective propagation of signal vectors. Through a series of experiments and comparisons with existing methods, we demonstrate the effectiveness of the new initialization method.
Not Only Rewards But Also Constraints: Applications on Legged Robot Locomotion
Aug 24, 2023



Several earlier studies have shown impressive control performance in complex robotic systems by designing the controller using a neural network and training it with model-free reinforcement learning. However, these outstanding controllers with natural motion style and high task performance are developed through extensive reward engineering, which is a highly laborious and time-consuming process of designing numerous reward terms and determining suitable reward coefficients. In this work, we propose a novel reinforcement learning framework for training neural network controllers for complex robotic systems consisting of both rewards and constraints. To let the engineers appropriately reflect their intent to constraints and handle them with minimal computation overhead, two constraint types and an efficient policy optimization algorithm are suggested. The learning framework is applied to train locomotion controllers for several legged robots with different morphology and physical attributes to traverse challenging terrains. Extensive simulation and real-world experiments demonstrate that performant controllers can be trained with significantly less reward engineering, by tuning only a single reward coefficient. Furthermore, a more straightforward and intuitive engineering process can be utilized, thanks to the interpretability and generalizability of constraints. The summary video is available at https://youtu.be/KAlm3yskhvM.
DiffFace: Diffusion-based Face Swapping with Facial Guidance
Dec 27, 2022



In this paper, we propose a diffusion-based face swapping framework for the first time, called DiffFace, composed of training ID conditional DDPM, sampling with facial guidance, and a target-preserving blending. In specific, in the training process, the ID conditional DDPM is trained to generate face images with the desired identity. In the sampling process, we use the off-the-shelf facial expert models to make the model transfer source identity while preserving target attributes faithfully. During this process, to preserve the background of the target image and obtain the desired face swapping result, we additionally propose a target-preserving blending strategy. It helps our model to keep the attributes of the target face from noise while transferring the source facial identity. In addition, without any re-training, our model can flexibly apply additional facial guidance and adaptively control the ID-attributes trade-off to achieve the desired results. To the best of our knowledge, this is the first approach that applies the diffusion model in face swapping task. Compared with previous GAN-based approaches, by taking advantage of the diffusion model for the face swapping task, DiffFace achieves better benefits such as training stability, high fidelity, diversity of the samples, and controllability. Extensive experiments show that our DiffFace is comparable or superior to the state-of-the-art methods on several standard face swapping benchmarks.
Learning Forward Dynamics Model and Informed Trajectory Sampler for Safe Quadruped Navigation
Apr 21, 2022
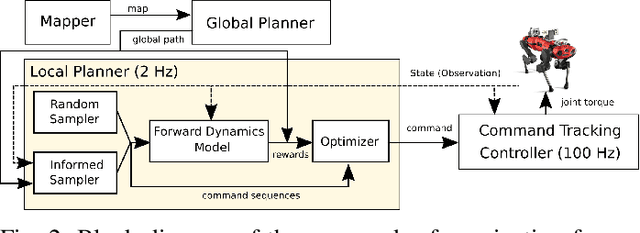

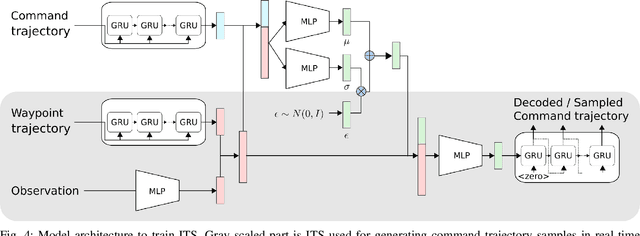
For autonomous quadruped robot navigation in various complex environments, a typical SOTA system is composed of four main modules -- mapper, global planner, local planner, and command-tracking controller -- in a hierarchical manner. In this paper, we build a robust and safe local planner which is designed to generate a velocity plan to track a coarsely planned path from the global planner. Previous works used waypoint-based methods (e.g. Proportional-Differential control and pure pursuit) which simplify the path tracking problem to local point-goal navigation. However, they suffer from frequent collisions in geometrically complex and narrow environments because of two reasons; the global planner uses a coarse and inaccurate model and the local planner is unable to track the global plan sufficiently well. Currently, deep learning methods are an appealing alternative because they can learn safety and path feasibility from experience more accurately. However, existing deep learning methods are not capable of planning for a long horizon. In this work, we propose a learning-based fully autonomous navigation framework composed of three innovative elements: a learned forward dynamics model (FDM), an online sampling-based model-predictive controller, and an informed trajectory sampler (ITS). Using our framework, a quadruped robot can autonomously navigate in various complex environments without a collision and generate a smoother command plan compared to the baseline method. Furthermore, our method can reactively handle unexpected obstacles on the planned path and avoid them. Project page https://awesomericky.github.io/projects/FDM_ITS_navigation/.
Learning multiple gaits of quadruped robot using hierarchical reinforcement learning
Dec 09, 2021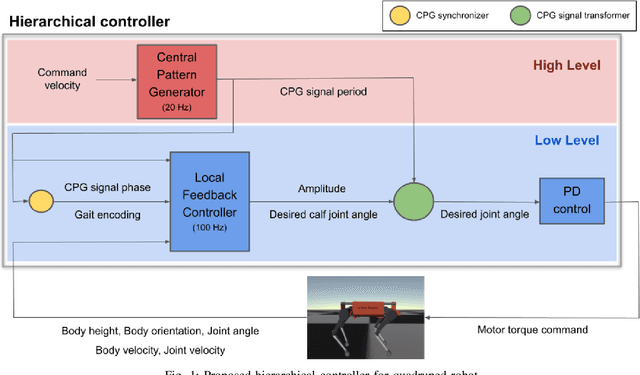
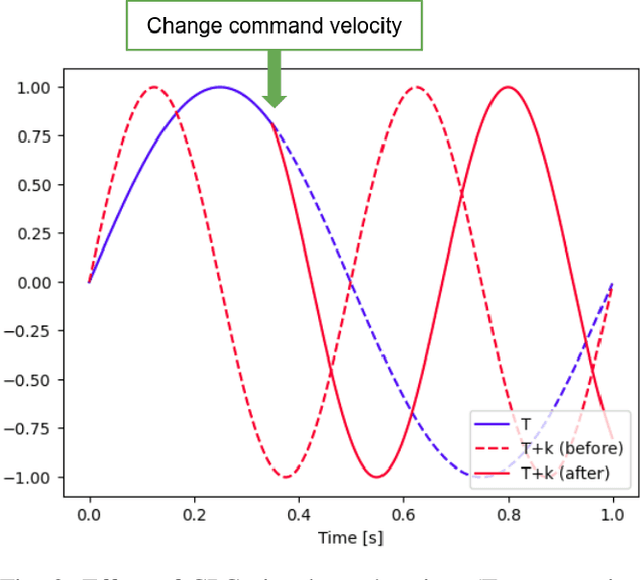

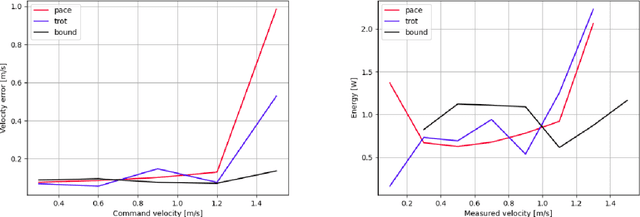
There is a growing interest in learning a velocity command tracking controller of quadruped robot using reinforcement learning due to its robustness and scalability. However, a single policy, trained end-to-end, usually shows a single gait regardless of the command velocity. This could be a suboptimal solution considering the existence of optimal gait according to the velocity for quadruped animals. In this work, we propose a hierarchical controller for quadruped robot that could generate multiple gaits (i.e. pace, trot, bound) while tracking velocity command. Our controller is composed of two policies, each working as a central pattern generator and local feedback controller, and trained with hierarchical reinforcement learning. Experiment results show 1) the existence of optimal gait for specific velocity range 2) the efficiency of our hierarchical controller compared to a controller composed of a single policy, which usually shows a single gait. Codes are publicly available.