 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Noisy Poses Break Inverse Dynamics: Analysis and Mitigation for Video-Based Joint Torque Estimation
May 23, 2026Recent advances in monocular 3D human pose estimation enable accurate body tracking from video. However, translating these kinematic estimates into physical quantities, such as joint torques, remains challenging due to noise amplification through inverse dynamics. In this work, we provide a systematic analysis of how pose estimation noise propagates through the inverse dynamics pipeline. We present three key findings: (1) pose noise is amplified by approximately 1,000x when computing joint torques via numerical differentiation, (2) proximal joints (spine, hips) are up to 10x more sensitive to noise than distal joints (wrists, hands), and (3) low-pass filtering before differentiation substantially reduces this amplification. To enable this analysis, we develop SMPL-Dynamics, a fully differentiable inverse dynamics module for the SMPL body model that requires no external physics simulators. Our module supports end-to-end gradient computation, and we demonstrate this through differentiable pose refinement, which reduces torque error by 93% with negligible change in pose.
Towards Continuous Sign Language Conversation from Isolated Signs
May 14, 2026Sign language is the primary language for many Deaf and Hard-of-Hearing (DHH) signers, yet most conversational AI systems still mediate interaction through spoken or written language. This spoken-language-centered interface can limit access for signers for whom spoken or written language is not the most accessible medium, motivating direct sign-to-sign conversational modeling. However, sentence-level sign video data are expensive to collect and annotate, leaving existing sign translation and production models with limited vocabulary coverage and weak open-domain generalization. We address this bottleneck by constructing continuous sign conversations from isolated signs: large-scale labeled isolated clips are collected as lexically grounded motion primitives and recomposed into sign-language-ordered utterances derived from existing dialogue corpora. We introduce SignaVox-W, which provides, to our knowledge, the largest labeled isolated-sign vocabulary to date, and SignaVox-U, a continuous 3D sign conversation dataset built from SignaVox-W. To bridge structural mismatch between spoken and signed languages, we use a retrieval-guided spoken-to-gloss translator; to bridge independently collected isolated clips, we propose BRAID, a diffusion Transformer that performs duration alignment and co-articulatory boundary inpainting. With the resulting data, we train SignaVox, a direct sign-to-sign conversational model that generates 3D body, hand, and facial motion responses from prior signing context without spoken-language text or externally provided glosses at inference time. Quantitative and qualitative evaluations show improved isolated-to-continuous motion quality, stronger response-level semantic alignment, and scalable signer-centered interaction that better supports visual-spatial articulation.
WarmPrior: Straightening Flow-Matching Policies with Temporal Priors
May 13, 2026Generative policies based on diffusion and flow matching have become a dominant paradigm for visuomotor robotic control. We show that replacing the standard Gaussian source distribution with WarmPrior, a simple temporally grounded prior constructed from readily available recent action history, consistently improves success rates on robotic manipulation tasks. We trace this gain to markedly straighter probability paths, echoing the effect of optimal-transport couplings in Rectified Flow. Beyond standard behavior cloning, WarmPrior also reshapes the exploration distribution in prior-space reinforcement learning, improving both sample efficiency and final performance. Collectively, these results identify the source distribution as an important and underexplored design axis in generative robot control.
Rethinking Graph Convolution for 2D-to-3D Hand Pose Lifting
May 13, 2026Graph convolutional networks (GCNs) are widely used for 3D hand pose estimation, where the hand skeleton is encoded as a fixed adjacency graph. We revisit whether this is the most effective way to incorporate hand topology in 2D-to-3D lifting. In this paper, we perform controlled, parameter-matched ablations on the FPHA benchmark and show that standard multi-head self-attention consistently outperforms GCN baselines. Even when the GCN is strengthened with multi-hop adjacency and matched parameter count, self-attention reduces MPJPE from 12.36 mm to 10.09 mm. A skeleton-constrained graph attention network recovers most of this gap, indicating that input-dependent aggregation is a major source of improvement, while fully connected attention yields additional gains. We further show that hand topology is most effective when introduced as a soft structural prior through graph-distance positional encoding, rather than as a hard adjacency constraint. These results suggest that, for hand pose lifting, adaptive spatial attention is a more effective inductive bias than fixed graph convolution.
Delaunay Canopy: Building Wireframe Reconstruction from Airborne LiDAR Point Clouds via Delaunay Graph
Apr 02, 2026Reconstructing building wireframe from airborne LiDAR point clouds yields a compact, topology-centric representation that enables structural understanding beyond dense meshes. Yet a key limitation persists: conventional methods have failed to achieve accurate wireframe reconstruction in regions afflicted by significant noise, sparsity, or internal corners. This failure stems from the inability to establish an adaptive search space to effectively leverage the rich 3D geometry of large, sparse building point clouds. In this work, we address this challenge with Delaunay Canopy, which utilizes the Delaunay graph as a geometric prior to define a geometrically adaptive search space. Central to our approach is Delaunay Graph Scoring, which not only reconstructs the underlying geometric manifold but also yields region-wise curvature signatures to robustly guide the reconstruction. Built on this foundation, our corner and wire selection modules leverage the Delaunay-induced prior to focus on highly probable elements, thereby shaping the search space and enabling accurate prediction even in previously intractable regions. Extensive experiments on the Building3D Tallinn city and entry-level datasets demonstrate state-of-the-art wireframe reconstruction, delivering accurate predictions across diverse and complex building geometries.
LIBERO-Para: A Diagnostic Benchmark and Metrics for Paraphrase Robustness in VLA Models
Mar 30, 2026Vision-Language-Action (VLA) models achieve strong performance in robotic manipulation by leveraging pre-trained vision-language backbones. However, in downstream robotic settings, they are typically fine-tuned with limited data, leading to overfitting to specific instruction formulations and leaving robustness to paraphrased instructions underexplored. To study this gap, we introduce LIBERO-Para, a controlled benchmark that independently varies action expressions and object references for fine-grained analysis of linguistic generalization. Across seven VLA configurations (0.6B-7.5B), we observe consistent performance degradation of 22-52 pp under paraphrasing. This degradation is primarily driven by object-level lexical variation: even simple synonym substitutions cause large drops, indicating reliance on surface-level matching rather than semantic grounding. Moreover, 80-96% of failures arise from planning-level trajectory divergence rather than execution errors, showing that paraphrasing disrupts task identification. Binary success rate treats all paraphrases equally, obscuring whether models perform consistently across difficulty levels or rely on easier cases. To address this, we propose PRIDE, a metric that quantifies paraphrase difficulty using semantic and syntactic factors. Our benchmark and corresponding code are available at: https://github.com/cau-hai-lab/LIBERO-Para
FEAST: Fully Connected Expressive Attention for Spatial Transcriptomics
Mar 26, 2026Spatial Transcriptomics (ST) provides spatially-resolved gene expression, offering crucial insights into tissue architecture and complex diseases. However, its prohibitive cost limits widespread adoption, leading to significant attention on inferring spatial gene expression from readily available whole slide images. While graph neural networks have been proposed to model interactions between tissue regions, their reliance on pre-defined sparse graphs prevents them from considering potentially interacting spot pairs, resulting in a structural limitation in capturing complex biological relationships. To address this, we propose FEAST (Fully connected Expressive Attention for Spatial Transcriptomics), an attention-based framework that models the tissue as a fully connected graph, enabling the consideration of all pairwise interactions. To better reflect biological interactions, we introduce negative-aware attention, which models both excitatory and inhibitory interactions, capturing essential negative relationships that standard attention often overlooks. Furthermore, to mitigate the information loss from truncated or ignored context in standard spot image extraction, we introduce an off-grid sampling strategy that gathers additional images from intermediate regions, allowing the model to capture a richer morphological context. Experiments on public ST datasets show that FEAST surpasses state-of-the-art methods in gene expression prediction while providing biologically plausible attention maps that clarify positive and negative interactions. Our code is available at https://github.com/starforTJ/ FEAST.
State Your Intention to Steer Your Attention: An AI Assistant for Intentional Digital Living
Oct 16, 2025When working on digital devices, people often face distractions that can lead to a decline in productivity and efficiency, as well as negative psychological and emotional impacts. To address this challenge, we introduce a novel Artificial Intelligence (AI) assistant that elicits a user's intention, assesses whether ongoing activities are in line with that intention, and provides gentle nudges when deviations occur. The system leverages a large language model to analyze screenshots, application titles, and URLs, issuing notifications when behavior diverges from the stated goal. Its detection accuracy is refined through initial clarification dialogues and continuous user feedback. In a three-week, within-subjects field deployment with 22 participants, we compared our assistant to both a rule-based intent reminder system and a passive baseline that only logged activity. Results indicate that our AI assistant effectively supports users in maintaining focus and aligning their digital behavior with their intentions. Our source code is publicly available at this url https://intentassistant.github.io
Spatial Transport Optimization by Repositioning Attention Map for Training-Free Text-to-Image Synthesis
Mar 28, 2025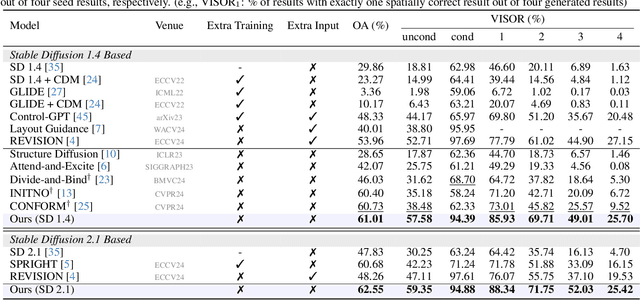

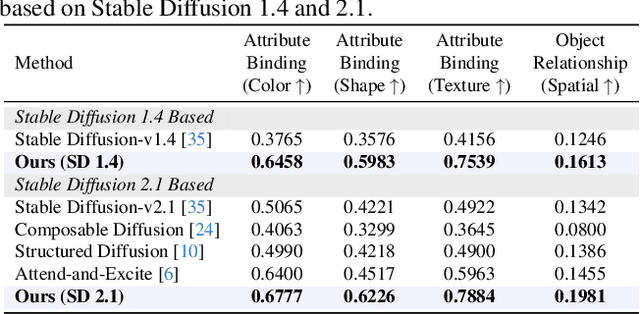
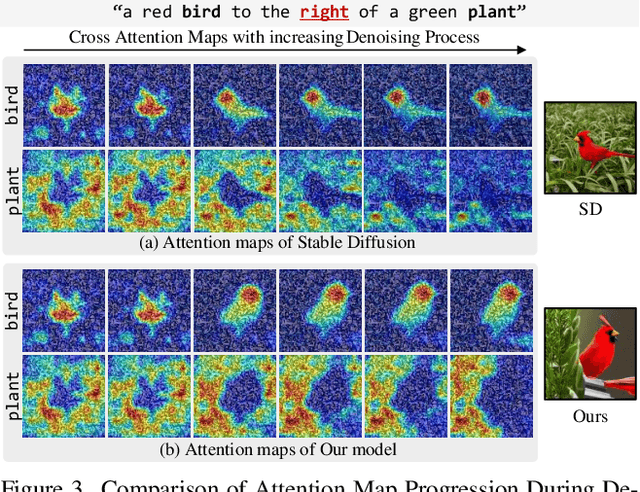
Diffusion-based text-to-image (T2I) models have recently excelled in high-quality image generation, particularly in a training-free manner, enabling cost-effective adaptability and generalization across diverse tasks. However, while the existing methods have been continuously focusing on several challenges, such as "missing objects" and "mismatched attributes," another critical issue of "mislocated objects" remains where generated spatial positions fail to align with text prompts. Surprisingly, ensuring such seemingly basic functionality remains challenging in popular T2I models due to the inherent difficulty of imposing explicit spatial guidance via text forms. To address this, we propose STORM (Spatial Transport Optimization by Repositioning Attention Map), a novel training-free approach for spatially coherent T2I synthesis. STORM employs Spatial Transport Optimization (STO), rooted in optimal transport theory, to dynamically adjust object attention maps for precise spatial adherence, supported by a Spatial Transport (ST) Cost function that enhances spatial understanding. Our analysis shows that integrating spatial awareness is most effective in the early denoising stages, while later phases refine details. Extensive experiments demonstrate that STORM surpasses existing methods, effectively mitigating mislocated objects while improving missing and mismatched attributes, setting a new benchmark for spatial alignment in T2I synthesis.
Fourier Decomposition for Explicit Representation of 3D Point Cloud Attributes
Mar 13, 2025While 3D point clouds are widely utilized across various vision applications, their irregular and sparse nature make them challenging to handle. In response, numerous encoding approaches have been proposed to capture the rich semantic information of point clouds. Yet, a critical limitation persists: a lack of consideration for colored point clouds which are more capable 3D representations as they contain diverse attributes: color and geometry. While existing methods handle these attributes separately on a per-point basis, this leads to a limited receptive field and restricted ability to capture relationships across multiple points. To address this, we pioneer a point cloud encoding methodology that leverages 3D Fourier decomposition to disentangle color and geometric features while extending the receptive field through spectral-domain operations. Our analysis confirms that this encoding approach effectively separates feature components, where the amplitude uniquely captures color attributes and the phase encodes geometric structure, thereby enabling independent learning and utilization of both attributes. Furthermore, the spectral-domain properties of these components naturally aggregate local features while considering multiple points' information. We validate our point cloud encoding approach on point cloud classification and style transfer tasks, achieving state-of-the-art results on the DensePoint dataset with improvements via a proposed amplitude-based data augmentation strategy.