 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMono-Modalizing Extremely Heterogeneous Multi-Modal Medical Image Registration
Jun 18, 2025In clinical practice, imaging modalities with functional characteristics, such as positron emission tomography (PET) and fractional anisotropy (FA), are often aligned with a structural reference (e.g., MRI, CT) for accurate interpretation or group analysis, necessitating multi-modal deformable image registration (DIR). However, due to the extreme heterogeneity of these modalities compared to standard structural scans, conventional unsupervised DIR methods struggle to learn reliable spatial mappings and often distort images. We find that the similarity metrics guiding these models fail to capture alignment between highly disparate modalities. To address this, we propose M2M-Reg (Multi-to-Mono Registration), a novel framework that trains multi-modal DIR models using only mono-modal similarity while preserving the established architectural paradigm for seamless integration into existing models. We also introduce GradCyCon, a regularizer that leverages M2M-Reg's cyclic training scheme to promote diffeomorphism. Furthermore, our framework naturally extends to a semi-supervised setting, integrating pre-aligned and unaligned pairs only, without requiring ground-truth transformations or segmentation masks. Experiments on the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset demonstrate that M2M-Reg achieves up to 2x higher DSC than prior methods for PET-MRI and FA-MRI registration, highlighting its effectiveness in handling highly heterogeneous multi-modal DIR. Our code is available at https://github.com/MICV-yonsei/M2M-Reg.
Pathology-Aware Adaptive Watermarking for Text-Driven Medical Image Synthesis
Mar 11, 2025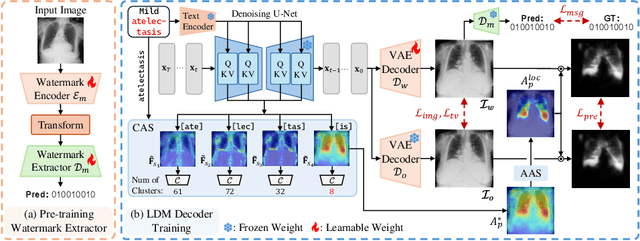
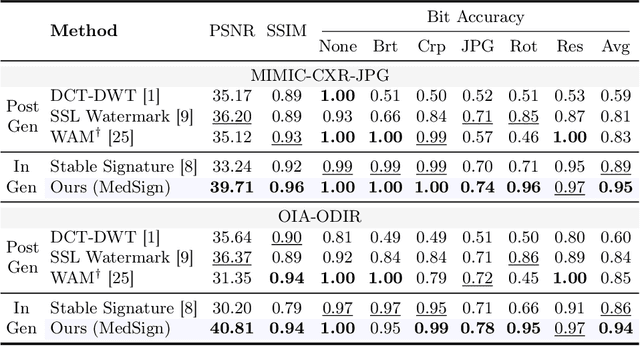
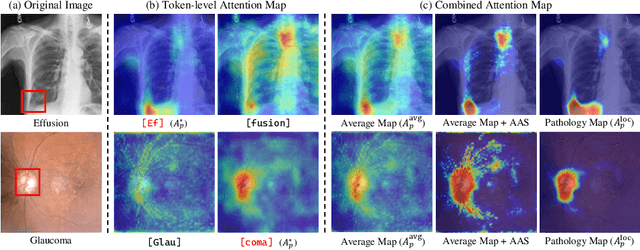
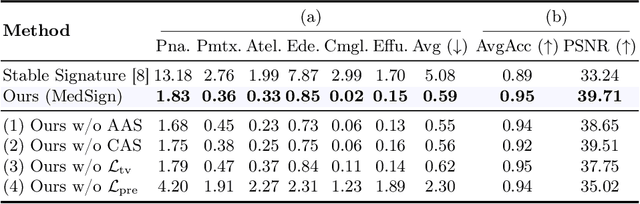
As recent text-conditioned diffusion models have enabled the generation of high-quality images, concerns over their potential misuse have also grown. This issue is critical in the medical domain, where text-conditioned generated medical images could enable insurance fraud or falsified records, highlighting the urgent need for reliable safeguards against unethical use. While watermarking techniques have emerged as a promising solution in general image domains, their direct application to medical imaging presents significant challenges. A key challenge is preserving fine-grained disease manifestations, as even minor distortions from a watermark may lead to clinical misinterpretation, which compromises diagnostic integrity. To overcome this gap, we present MedSign, a deep learning-based watermarking framework specifically designed for text-to-medical image synthesis, which preserves pathologically significant regions by adaptively adjusting watermark strength. Specifically, we generate a pathology localization map using cross-attention between medical text tokens and the diffusion denoising network, aggregating token-wise attention across layers, heads, and time steps. Leveraging this map, we optimize the LDM decoder to incorporate watermarking during image synthesis, ensuring cohesive integration while minimizing interference in diagnostically critical regions. Experimental results show that our MedSign preserves diagnostic integrity while ensuring watermark robustness, achieving state-of-the-art performance in image quality and detection accuracy on MIMIC-CXR and OIA-ODIR datasets.
Your Large Vision-Language Model Only Needs A Few Attention Heads For Visual Grounding
Mar 08, 2025Visual grounding seeks to localize the image region corresponding to a free-form text description. Recently, the strong multimodal capabilities of Large Vision-Language Models (LVLMs) have driven substantial improvements in visual grounding, though they inevitably require fine-tuning and additional model components to explicitly generate bounding boxes or segmentation masks. However, we discover that a few attention heads in frozen LVLMs demonstrate strong visual grounding capabilities. We refer to these heads, which consistently capture object locations related to text semantics, as localization heads. Using localization heads, we introduce a straightforward and effective training-free visual grounding framework that utilizes text-to-image attention maps from localization heads to identify the target objects. Surprisingly, only three out of thousands of attention heads are sufficient to achieve competitive localization performance compared to existing LVLM-based visual grounding methods that require fine-tuning. Our findings suggest that LVLMs can innately ground objects based on a deep comprehension of the text-image relationship, as they implicitly focus on relevant image regions to generate informative text outputs. All the source codes will be made available to the public.
See What You Are Told: Visual Attention Sink in Large Multimodal Models
Mar 05, 2025Large multimodal models (LMMs) "see" images by leveraging the attention mechanism between text and visual tokens in the transformer decoder. Ideally, these models should focus on key visual information relevant to the text token. However, recent findings indicate that LMMs have an extraordinary tendency to consistently allocate high attention weights to specific visual tokens, even when these tokens are irrelevant to the corresponding text. In this study, we investigate the property behind the appearance of these irrelevant visual tokens and examine their characteristics. Our findings show that this behavior arises due to the massive activation of certain hidden state dimensions, which resembles the attention sink found in language models. Hence, we refer to this phenomenon as the visual attention sink. In particular, our analysis reveals that removing the irrelevant visual sink tokens does not impact model performance, despite receiving high attention weights. Consequently, we recycle the attention to these tokens as surplus resources, redistributing the attention budget to enhance focus on the image. To achieve this, we introduce Visual Attention Redistribution (VAR), a method that redistributes attention in image-centric heads, which we identify as innately focusing on visual information. VAR can be seamlessly applied across different LMMs to improve performance on a wide range of tasks, including general vision-language tasks, visual hallucination tasks, and vision-centric tasks, all without the need for additional training, models, or inference steps. Experimental results demonstrate that VAR enables LMMs to process visual information more effectively by adjusting their internal attention mechanisms, offering a new direction to enhancing the multimodal capabilities of LMMs.