 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViKey: Enhancing Temporal Understanding in Videos via Visual Prompting
Mar 24, 2026Recent advancements in Video Large Language Models (VideoLLMs) have enabled strong performance across diverse multimodal video tasks. To reduce the high computational cost of processing dense video frames, efficiency-oriented methods such as frame selection have been widely adopted. While effective at minimizing redundancy, these methods often cause notable performance drops on tasks requiring temporal reasoning. Unlike humans, who can infer event progression from sparse visual cues, VideoLLMs frequently misinterpret temporal relations when intermediate frames are omitted. To address this limitation, we explore visual prompting (VP) as a lightweight yet effective way to enhance temporal understanding in VideoLLMs. Our analysis reveals that simply annotating each frame with explicit ordinal information helps the model perceive temporal continuity. This visual cue also supports frame-level referencing and mitigates positional ambiguity within a sparsely sampled sequence. Building on these insights, we introduce ViKey, a training-free framework that combines VP with a lightweight Keyword-Frame Mapping (KFM) module. KFM leverages frame indices as dictionary-like keys to link textual cues to the most relevant frames, providing explicit temporal anchors during inference. Despite its simplicity, our approach substantially improves temporal reasoning and, on some datasets, preserves dense-frame baseline performance with as few as 20% of frames.
Pathology-Aware Adaptive Watermarking for Text-Driven Medical Image Synthesis
Mar 11, 2025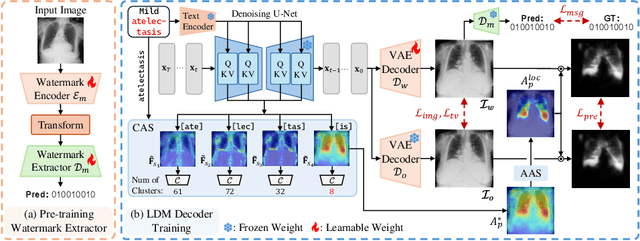
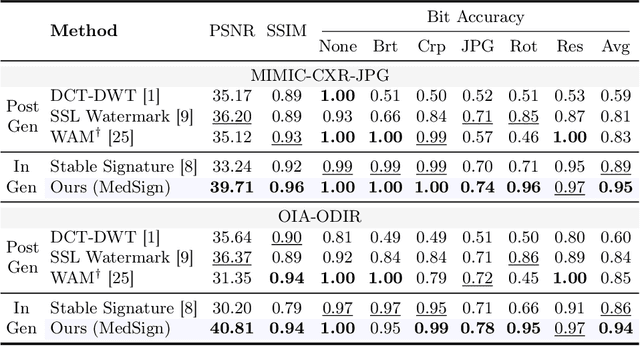
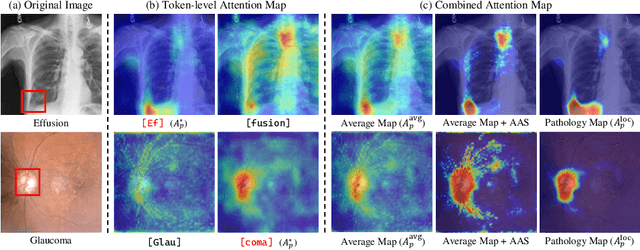
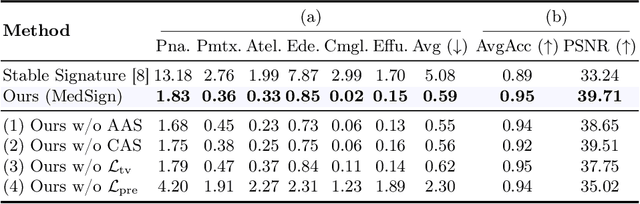
As recent text-conditioned diffusion models have enabled the generation of high-quality images, concerns over their potential misuse have also grown. This issue is critical in the medical domain, where text-conditioned generated medical images could enable insurance fraud or falsified records, highlighting the urgent need for reliable safeguards against unethical use. While watermarking techniques have emerged as a promising solution in general image domains, their direct application to medical imaging presents significant challenges. A key challenge is preserving fine-grained disease manifestations, as even minor distortions from a watermark may lead to clinical misinterpretation, which compromises diagnostic integrity. To overcome this gap, we present MedSign, a deep learning-based watermarking framework specifically designed for text-to-medical image synthesis, which preserves pathologically significant regions by adaptively adjusting watermark strength. Specifically, we generate a pathology localization map using cross-attention between medical text tokens and the diffusion denoising network, aggregating token-wise attention across layers, heads, and time steps. Leveraging this map, we optimize the LDM decoder to incorporate watermarking during image synthesis, ensuring cohesive integration while minimizing interference in diagnostically critical regions. Experimental results show that our MedSign preserves diagnostic integrity while ensuring watermark robustness, achieving state-of-the-art performance in image quality and detection accuracy on MIMIC-CXR and OIA-ODIR datasets.
Distilling Spectral Graph for Object-Context Aware Open-Vocabulary Semantic Segmentation
Nov 26, 2024Open-Vocabulary Semantic Segmentation (OVSS) has advanced with recent vision-language models (VLMs), enabling segmentation beyond predefined categories through various learning schemes. Notably, training-free methods offer scalable, easily deployable solutions for handling unseen data, a key goal of OVSS. Yet, a critical issue persists: lack of object-level context consideration when segmenting complex objects in the challenging environment of OVSS based on arbitrary query prompts. This oversight limits models' ability to group semantically consistent elements within object and map them precisely to user-defined arbitrary classes. In this work, we introduce a novel approach that overcomes this limitation by incorporating object-level contextual knowledge within images. Specifically, our model enhances intra-object consistency by distilling spectral-driven features from vision foundation models into the attention mechanism of the visual encoder, enabling semantically coherent components to form a single object mask. Additionally, we refine the text embeddings with zero-shot object presence likelihood to ensure accurate alignment with the specific objects represented in the images. By leveraging object-level contextual knowledge, our proposed approach achieves state-of-the-art performance with strong generalizability across diverse datasets.
Advancing Text-Driven Chest X-Ray Generation with Policy-Based Reinforcement Learning
Mar 11, 2024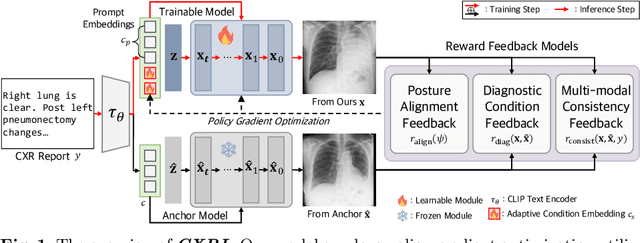

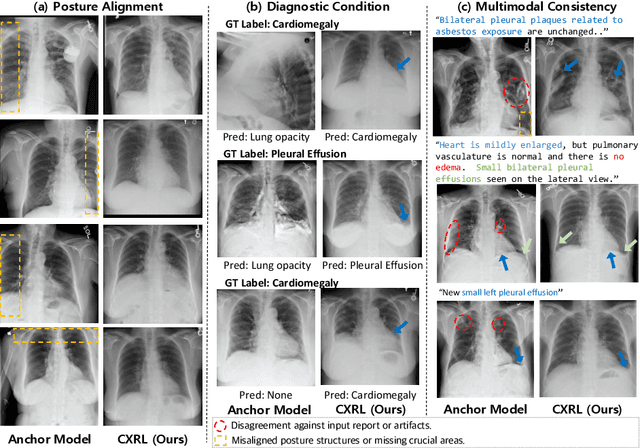

Recent advances in text-conditioned image generation diffusion models have begun paving the way for new opportunities in modern medical domain, in particular, generating Chest X-rays (CXRs) from diagnostic reports. Nonetheless, to further drive the diffusion models to generate CXRs that faithfully reflect the complexity and diversity of real data, it has become evident that a nontrivial learning approach is needed. In light of this, we propose CXRL, a framework motivated by the potential of reinforcement learning (RL). Specifically, we integrate a policy gradient RL approach with well-designed multiple distinctive CXR-domain specific reward models. This approach guides the diffusion denoising trajectory, achieving precise CXR posture and pathological details. Here, considering the complex medical image environment, we present "RL with Comparative Feedback" (RLCF) for the reward mechanism, a human-like comparative evaluation that is known to be more effective and reliable in complex scenarios compared to direct evaluation. Our CXRL framework includes jointly optimizing learnable adaptive condition embeddings (ACE) and the image generator, enabling the model to produce more accurate and higher perceptual CXR quality. Our extensive evaluation of the MIMIC-CXR-JPG dataset demonstrates the effectiveness of our RL-based tuning approach. Consequently, our CXRL generates pathologically realistic CXRs, establishing a new standard for generating CXRs with high fidelity to real-world clinical scenarios.
EAGLE: Eigen Aggregation Learning for Object-Centric Unsupervised Semantic Segmentation
Mar 03, 2024
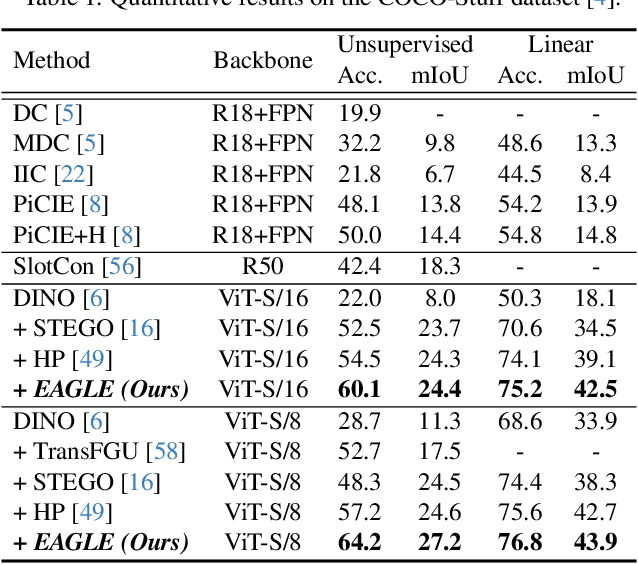


Semantic segmentation has innately relied on extensive pixel-level labeled annotated data, leading to the emergence of unsupervised methodologies. Among them, leveraging self-supervised Vision Transformers for unsupervised semantic segmentation (USS) has been making steady progress with expressive deep features. Yet, for semantically segmenting images with complex objects, a predominant challenge remains: the lack of explicit object-level semantic encoding in patch-level features. This technical limitation often leads to inadequate segmentation of complex objects with diverse structures. To address this gap, we present a novel approach, EAGLE, which emphasizes object-centric representation learning for unsupervised semantic segmentation. Specifically, we introduce EiCue, a spectral technique providing semantic and structural cues through an eigenbasis derived from the semantic similarity matrix of deep image features and color affinity from an image. Further, by incorporating our object-centric contrastive loss with EiCue, we guide our model to learn object-level representations with intra- and inter-image object-feature consistency, thereby enhancing semantic accuracy. Extensive experiments on COCO-Stuff, Cityscapes, and Potsdam-3 datasets demonstrate the state-of-the-art USS results of EAGLE with accurate and consistent semantic segmentation across complex scenes.