 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCMNet: Uncertainty-Aware Context Memory Network for Under-Display Camera Image Restoration
Apr 01, 2026Under-display cameras (UDCs) allow for full-screen designs by positioning the imaging sensor underneath the display. Nonetheless, light diffraction and scattering through the various display layers result in spatially varying and complex degradations, which significantly reduce high-frequency details. Current PSF-based physical modeling techniques and frequency-separation networks are effective at reconstructing low-frequency structures and maintaining overall color consistency. However, they still face challenges in recovering fine details when dealing with complex, spatially varying degradation. To solve this problem, we propose a lightweight \textbf{U}ncertainty-aware \textbf{C}ontext-\textbf{M}emory \textbf{Network} (\textbf{UCMNet}), for UDC image restoration. Unlike previous methods that apply uniform restoration, UCMNet performs uncertainty-aware adaptive processing to restore high-frequency details in regions with varying degradations. The estimated uncertainty maps, learned through an uncertainty-driven loss, quantify spatial uncertainty induced by diffraction and scattering, and guide the Memory Bank to retrieve region-adaptive context from the Context Bank. This process enables effective modeling of the non-uniform degradation characteristics inherent to UDC imaging. Leveraging this uncertainty as a prior, UCMNet achieves state-of-the-art performance on multiple benchmarks with 30\% fewer parameters than previous models. Project page: \href{https://kdhrick2222.github.io/projects/UCMNet/}{https://kdhrick2222.github.io/projects/UCMNet}.
ViKey: Enhancing Temporal Understanding in Videos via Visual Prompting
Mar 24, 2026Recent advancements in Video Large Language Models (VideoLLMs) have enabled strong performance across diverse multimodal video tasks. To reduce the high computational cost of processing dense video frames, efficiency-oriented methods such as frame selection have been widely adopted. While effective at minimizing redundancy, these methods often cause notable performance drops on tasks requiring temporal reasoning. Unlike humans, who can infer event progression from sparse visual cues, VideoLLMs frequently misinterpret temporal relations when intermediate frames are omitted. To address this limitation, we explore visual prompting (VP) as a lightweight yet effective way to enhance temporal understanding in VideoLLMs. Our analysis reveals that simply annotating each frame with explicit ordinal information helps the model perceive temporal continuity. This visual cue also supports frame-level referencing and mitigates positional ambiguity within a sparsely sampled sequence. Building on these insights, we introduce ViKey, a training-free framework that combines VP with a lightweight Keyword-Frame Mapping (KFM) module. KFM leverages frame indices as dictionary-like keys to link textual cues to the most relevant frames, providing explicit temporal anchors during inference. Despite its simplicity, our approach substantially improves temporal reasoning and, on some datasets, preserves dense-frame baseline performance with as few as 20% of frames.
DMD-augmented Unpaired Neural Schrödinger Bridge for Ultra-Low Field MRI Enhancement
Mar 05, 2026Ultra Low Field (64 mT) brain MRI improves accessibility but suffers from reduced image quality compared to 3 T. As paired 64 mT - 3 T scans are scarce, we propose an unpaired 64 mT $\rightarrow$ 3 T translation framework that enhances realism while preserving anatomy. Our method builds upon the Unpaired Neural Schrödinge Bridge (UNSB) with multi-step refinement. To strengthen target distribution alignment, we augment the adversarial objective with DMD2-style diffusion-guided distribution matching using a frozen 3T diffusion teacher. To explicitly constrain global structure beyond patch-level correspondence, we combine PatchNCE with an Anatomical Structure Preservation (ASP) regularizer that enforces soft foreground background consistency and boundary aware constraints. Evaluated on two disjoint cohorts, the proposed framework achieves an improved realism structure trade-off, enhancing distribution level realism on unpaired benchmarks while increasing structural fidelity on the paired cohort compared to unpaired baselines.
RaBiT: Residual-Aware Binarization Training for Accurate and Efficient LLMs
Feb 05, 2026Efficient deployment of large language models (LLMs) requires extreme quantization, forcing a critical trade-off between low-bit efficiency and performance. Residual binarization enables hardware-friendly, matmul-free inference by stacking binary ($\pm$1) layers, but is plagued by pathological feature co-adaptation. We identify a key failure mode, which we term inter-path adaptation: during quantization-aware training (QAT), parallel residual binary paths learn redundant features, degrading the error-compensation structure and limiting the expressive capacity of the model. While prior work relies on heuristic workarounds (e.g., path freezing) that constrain the solution space, we propose RaBiT, a novel quantization framework that resolves co-adaptation by algorithmically enforcing a residual hierarchy. Its core mechanism sequentially derives each binary path from a single shared full-precision weight, which ensures that every path corrects the error of the preceding one. This process is stabilized by a robust initialization that prioritizes functional preservation over mere weight approximation. RaBiT redefines the 2-bit accuracy-efficiency frontier: it achieves state-of-the-art performance, rivals even hardware-intensive Vector Quantization (VQ) methods, and delivers a $4.49\times$ inference speed-up over full-precision models on an RTX 4090.
MAVL: A Multilingual Audio-Video Lyrics Dataset for Animated Song Translation
May 24, 2025Lyrics translation requires both accurate semantic transfer and preservation of musical rhythm, syllabic structure, and poetic style. In animated musicals, the challenge intensifies due to alignment with visual and auditory cues. We introduce Multilingual Audio-Video Lyrics Benchmark for Animated Song Translation (MAVL), the first multilingual, multimodal benchmark for singable lyrics translation. By integrating text, audio, and video, MAVL enables richer and more expressive translations than text-only approaches. Building on this, we propose Syllable-Constrained Audio-Video LLM with Chain-of-Thought SylAVL-CoT, which leverages audio-video cues and enforces syllabic constraints to produce natural-sounding lyrics. Experimental results demonstrate that SylAVL-CoT significantly outperforms text-based models in singability and contextual accuracy, emphasizing the value of multimodal, multilingual approaches for lyrics translation.
Scalp Diagnostic System With Label-Free Segmentation and Training-Free Image Translation
Jun 26, 2024Scalp diseases and alopecia affect millions of people around the world, underscoring the urgent need for early diagnosis and management of the disease. However, the development of a comprehensive AI-based diagnosis system encompassing these conditions remains an underexplored domain due to the challenges associated with data imbalance and the costly nature of labeling. To address these issues, we propose ScalpVision, an AI-driven system for the holistic diagnosis of scalp diseases and alopecia. In ScalpVision, effective hair segmentation is achieved using pseudo image-label pairs and an innovative prompting method in the absence of traditional hair masking labels. This approach is crucial for extracting key features such as hair thickness and count, which are then used to assess alopecia severity. Additionally, ScalpVision introduces DiffuseIT-M, a generative model adept at dataset augmentation while maintaining hair information, facilitating improved predictions of scalp disease severity. Our experimental results affirm ScalpVision's efficiency in diagnosing a variety of scalp conditions and alopecia, showcasing its potential as a valuable tool in dermatological care.
Automatic Question-Answer Generation for Long-Tail Knowledge
Mar 03, 2024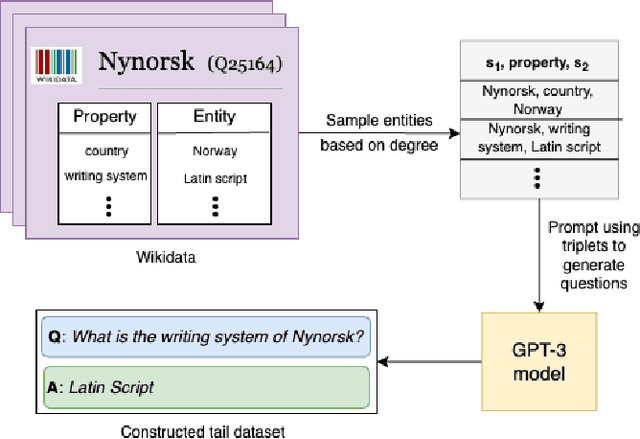

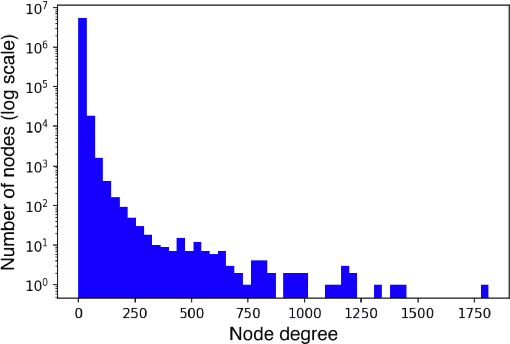
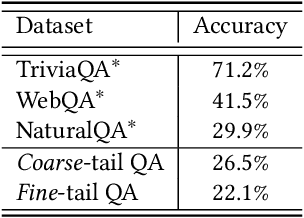
Pretrained Large Language Models (LLMs) have gained significant attention for addressing open-domain Question Answering (QA). While they exhibit high accuracy in answering questions related to common knowledge, LLMs encounter difficulties in learning about uncommon long-tail knowledge (tail entities). Since manually constructing QA datasets demands substantial human resources, the types of existing QA datasets are limited, leaving us with a scarcity of datasets to study the performance of LLMs on tail entities. In this paper, we propose an automatic approach to generate specialized QA datasets for tail entities and present the associated research challenges. We conduct extensive experiments by employing pretrained LLMs on our newly generated long-tail QA datasets, comparing their performance with and without external resources including Wikipedia and Wikidata knowledge graphs.
Keypoint based Sign Language Translation without Glosses
Apr 22, 2022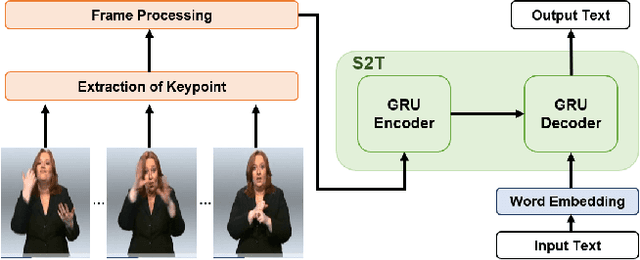
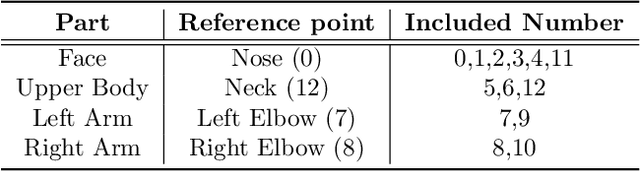
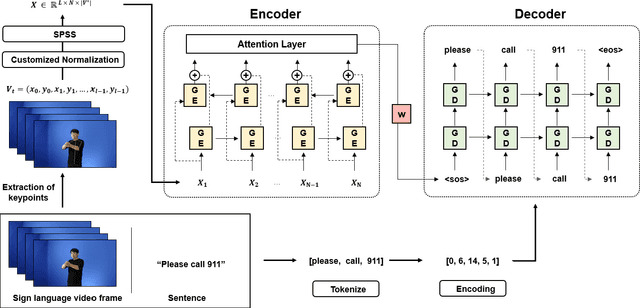
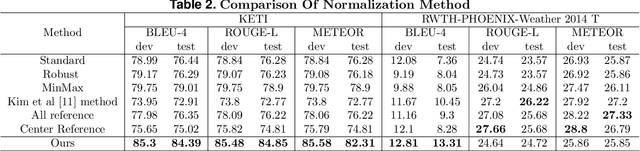
Sign Language Translation (SLT) is a task that has not been studied relatively much compared to the study of Sign Language Recognition (SLR). However, the SLR is a study that recognizes the unique grammar of sign language, which is different from the spoken language and has a problem that non-disabled people cannot easily interpret. So, we're going to solve the problem of translating directly spoken language in sign language video. To this end, we propose a new keypoint normalization method for performing translation based on the skeleton point of the signer and robustly normalizing these points in sign language translation. It contributed to performance improvement by a customized normalization method depending on the body parts. In addition, we propose a stochastic frame selection method that enables frame augmentation and sampling at the same time. Finally, it is translated into the spoken language through an Attention-based translation model. Our method can be applied to various datasets in a way that can be applied to datasets without glosses. In addition, quantitative experimental evaluation proved the excellence of our method.
Are Evolutionary Algorithms Safe Optimizers?
Mar 24, 2022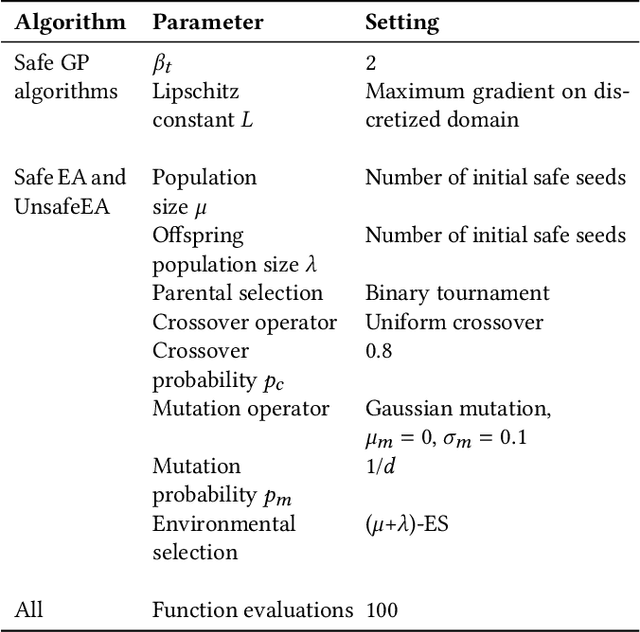
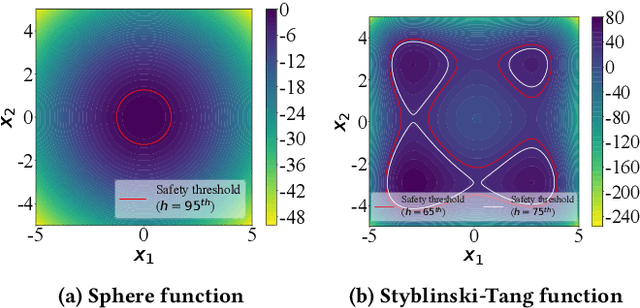
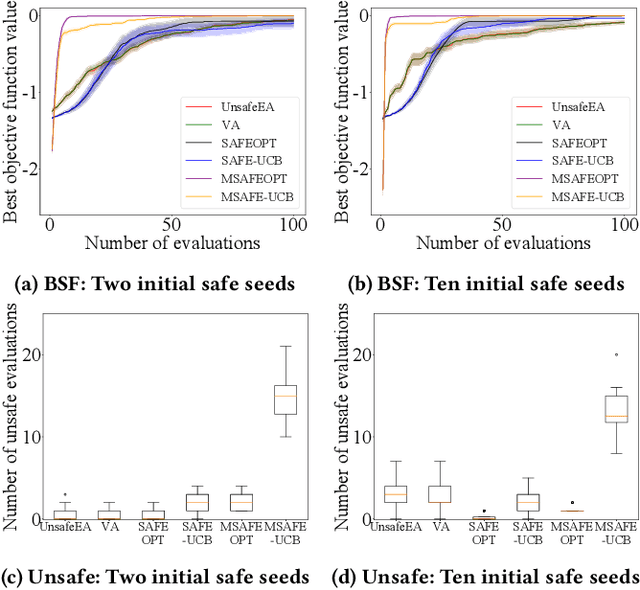
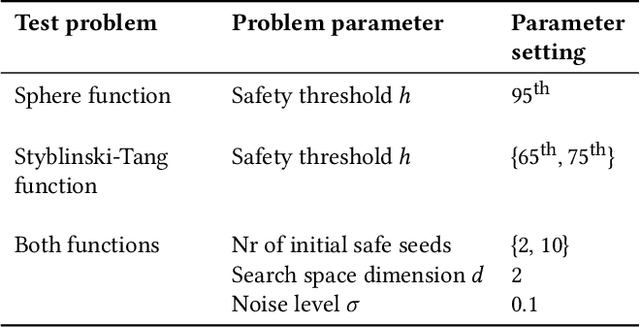
We consider a type of constrained optimization problem, where the violation of a constraint leads to an irrevocable loss, such as breakage of a valuable experimental resource/platform or loss of human life. Such problems are referred to as safe optimization problems (SafeOPs). While SafeOPs have received attention in the machine learning community in recent years, there was little interest in the evolutionary computation (EC) community despite some early attempts between 2009 and 2011. Moreover, there is a lack of acceptable guidelines on how to benchmark different algorithms for SafeOPs, an area where the EC community has significant experience in. Driven by the need for more efficient algorithms and benchmark guidelines for SafeOPs, the objective of this paper is to reignite the interest of this problem class in the EC community. To achieve this we (i) provide a formal definition of SafeOPs and contrast it to other types of optimization problems that the EC community is familiar with, (ii) investigate the impact of key SafeOP parameters on the performance of selected safe optimization algorithms, (iii) benchmark EC against state-of-the-art safe optimization algorithms from the machine learning community, and (iv) provide an open-source Python framework to replicate and extend our work.
Safe Learning and Optimization Techniques: Towards a Survey of the State of the Art
Feb 18, 2021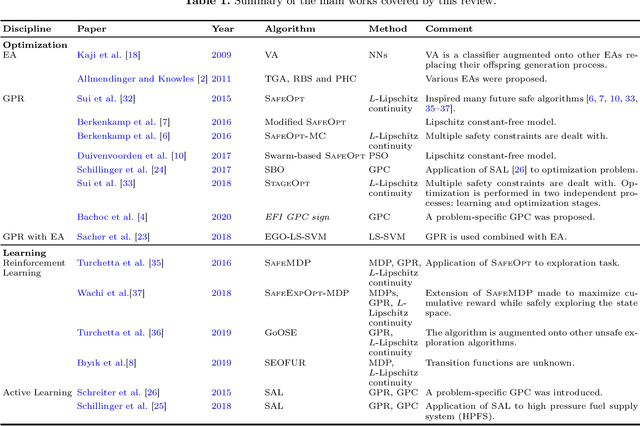
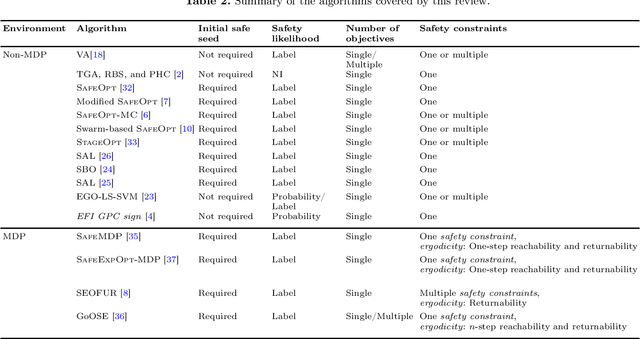
Safe learning and optimization deals with learning and optimization problems that avoid, as much as possible, the evaluation of non-safe input points, which are solutions, policies, or strategies that cause an irrecoverable loss (e.g., breakage of a machine or equipment, or life threat). Although a comprehensive survey of safe reinforcement learning algorithms was published in 2015, a number of new algorithms have been proposed thereafter, and related works in active learning and in optimization were not considered. This paper reviews those algorithms from a number of domains including reinforcement learning, Gaussian process regression and classification, evolutionary algorithms, and active learning. We provide the fundamental concepts on which the reviewed algorithms are based and a characterization of the individual algorithms. We conclude by explaining how the algorithms are connected and suggestions for future research.