 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Question-Answer Generation for Long-Tail Knowledge
Mar 03, 2024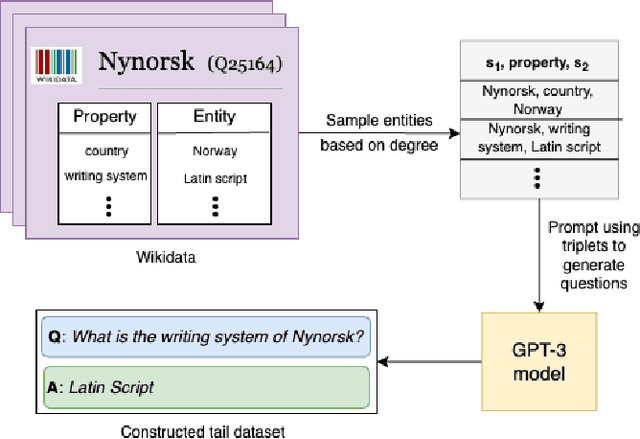

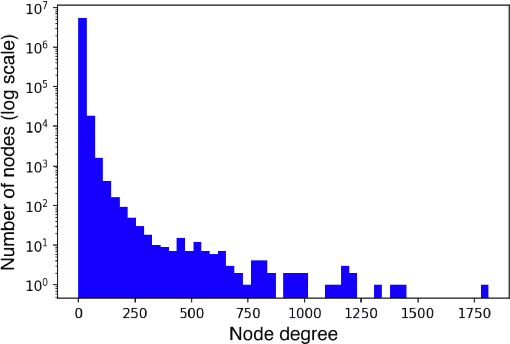
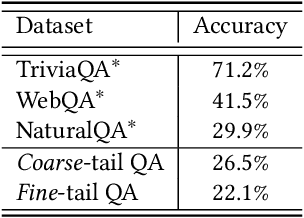
Pretrained Large Language Models (LLMs) have gained significant attention for addressing open-domain Question Answering (QA). While they exhibit high accuracy in answering questions related to common knowledge, LLMs encounter difficulties in learning about uncommon long-tail knowledge (tail entities). Since manually constructing QA datasets demands substantial human resources, the types of existing QA datasets are limited, leaving us with a scarcity of datasets to study the performance of LLMs on tail entities. In this paper, we propose an automatic approach to generate specialized QA datasets for tail entities and present the associated research challenges. We conduct extensive experiments by employing pretrained LLMs on our newly generated long-tail QA datasets, comparing their performance with and without external resources including Wikipedia and Wikidata knowledge graphs.
SEMQA: Semi-Extractive Multi-Source Question Answering
Nov 08, 2023Recently proposed long-form question answering (QA) systems, supported by large language models (LLMs), have shown promising capabilities. Yet, attributing and verifying their generated abstractive answers can be difficult, and automatically evaluating their accuracy remains an ongoing challenge. In this work, we introduce a new QA task for answering multi-answer questions by summarizing multiple diverse sources in a semi-extractive fashion. Specifically, Semi-extractive Multi-source QA (SEMQA) requires models to output a comprehensive answer, while mixing factual quoted spans -- copied verbatim from given input sources -- and non-factual free-text connectors that glue these spans together into a single cohesive passage. This setting bridges the gap between the outputs of well-grounded but constrained extractive QA systems and more fluent but harder to attribute fully abstractive answers. Particularly, it enables a new mode for language models that leverages their advanced language generation capabilities, while also producing fine in-line attributions by-design that are easy to verify, interpret, and evaluate. To study this task, we create the first dataset of this kind, QuoteSum, with human-written semi-extractive answers to natural and generated questions, and define text-based evaluation metrics. Experimenting with several LLMs in various settings, we find this task to be surprisingly challenging, demonstrating the importance of QuoteSum for developing and studying such consolidation capabilities.
Answering Ambiguous Questions with a Database of Questions, Answers, and Revisions
Aug 16, 2023Many open-domain questions are under-specified and thus have multiple possible answers, each of which is correct under a different interpretation of the question. Answering such ambiguous questions is challenging, as it requires retrieving and then reasoning about diverse information from multiple passages. We present a new state-of-the-art for answering ambiguous questions that exploits a database of unambiguous questions generated from Wikipedia. On the challenging ASQA benchmark, which requires generating long-form answers that summarize the multiple answers to an ambiguous question, our method improves performance by 15% (relative improvement) on recall measures and 10% on measures which evaluate disambiguating questions from predicted outputs. Retrieving from the database of generated questions also gives large improvements in diverse passage retrieval (by matching user questions q to passages p indirectly, via questions q' generated from p).
Can Pre-trained Vision and Language Models Answer Visual Information-Seeking Questions?
Feb 24, 2023

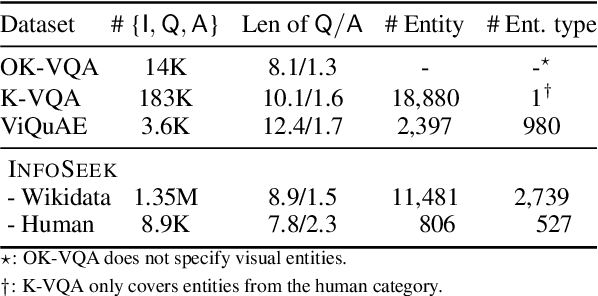

Large language models have demonstrated an emergent capability in answering knowledge intensive questions. With recent progress on web-scale visual and language pre-training, do these models also understand how to answer visual information seeking questions? To answer this question, we present InfoSeek, a Visual Question Answering dataset that focuses on asking information-seeking questions, where the information can not be answered by common sense knowledge. We perform a multi-stage human annotation to collect a natural distribution of high-quality visual information seeking question-answer pairs. We also construct a large-scale, automatically collected dataset by combining existing visual entity recognition datasets and Wikidata, which provides over one million examples for model fine-tuning and validation. Based on InfoSeek, we analyzed various pre-trained Visual QA systems to gain insights into the characteristics of different pre-trained models. Our analysis shows that it is challenging for the state-of-the-art multi-modal pre-trained models to answer visual information seeking questions, but this capability is improved through fine-tuning on the automated InfoSeek dataset. We hope our analysis paves the way to understand and develop the next generation of multi-modal pre-training.
Reasoning over Logically Interacted Conditions for Question Answering
May 25, 2022

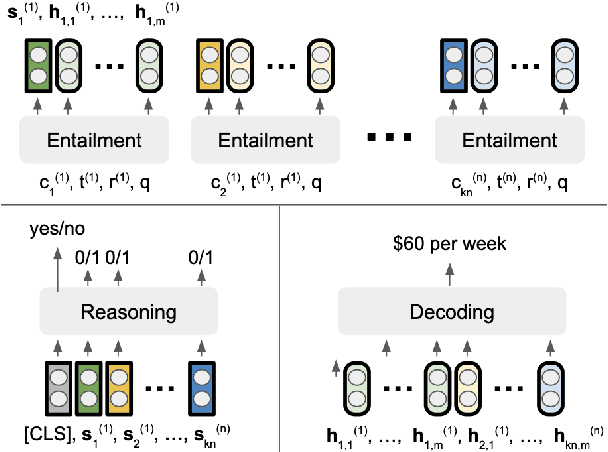
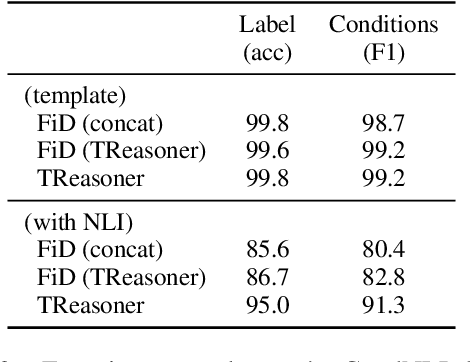
Some questions have multiple answers that are not equally correct, i.e. answers are different under different conditions. Conditions are used to distinguish answers as well as to provide additional information to support them. In this paper, we study a more challenging task where answers are constrained by a list of conditions that logically interact, which requires performing logical reasoning over the conditions to determine the correctness of the answers. Even more challenging, we only provide evidences for a subset of the conditions, so some questions may not have deterministic answers. In such cases, models are asked to find probable answers and identify conditions that need to be satisfied to make the answers correct. We propose a new model, TReasoner, for this challenging reasoning task. TReasoner consists of an entailment module, a reasoning module, and a generation module (if the answers are free-form text spans). TReasoner achieves state-of-the-art performance on two benchmark conditional QA datasets, outperforming the previous state-of-the-art by 3-10 points.
ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers
Oct 13, 2021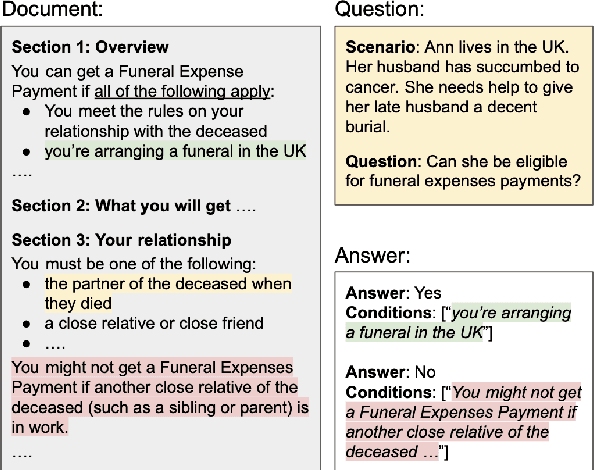
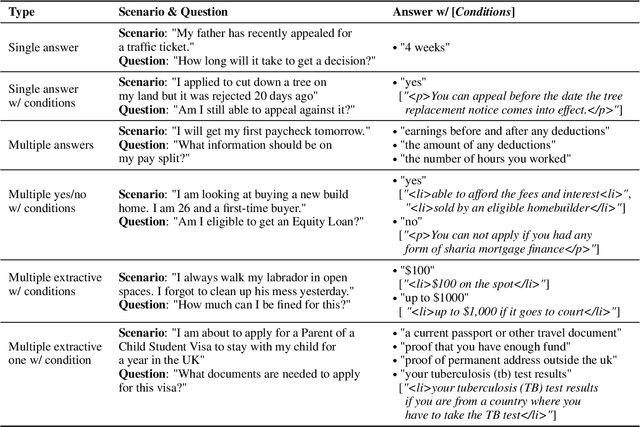
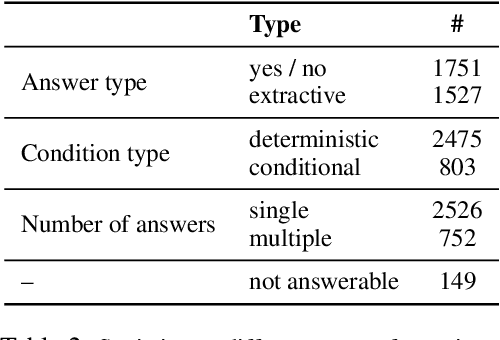
We describe a Question Answering (QA) dataset that contains complex questions with conditional answers, i.e. the answers are only applicable when certain conditions apply. We call this dataset ConditionalQA. In addition to conditional answers, the dataset also features: (1) long context documents with information that is related in logically complex ways; (2) multi-hop questions that require compositional logical reasoning; (3) a combination of extractive questions, yes/no questions, questions with multiple answers, and not-answerable questions; (4) questions asked without knowing the answers. We show that ConditionalQA is challenging for many of the existing QA models, especially in selecting answer conditions. We believe that this dataset will motivate further research in answering complex questions over long documents. Data and leaderboard are publicly available at \url{https://github.com/haitian-sun/ConditionalQA}.
End-to-End Multihop Retrieval for Compositional Question Answering over Long Documents
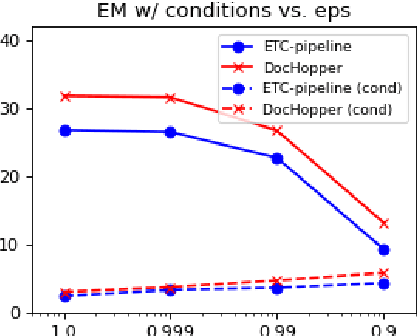
Jun 01, 2021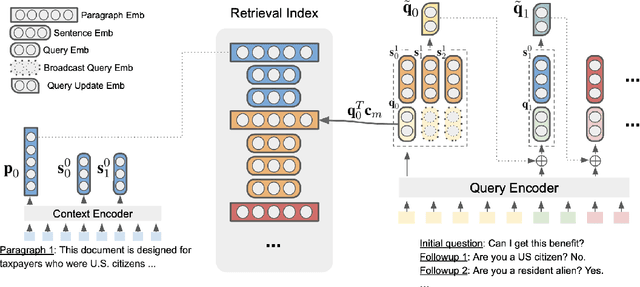
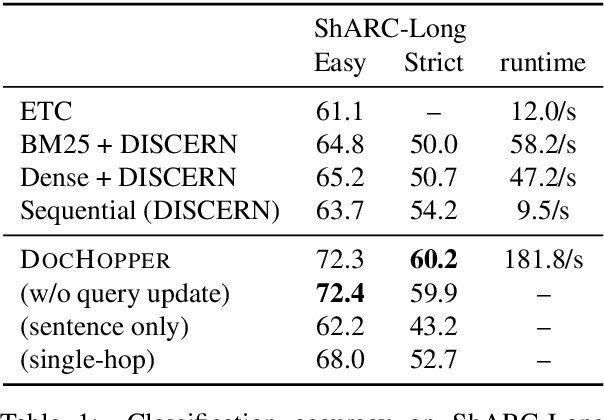
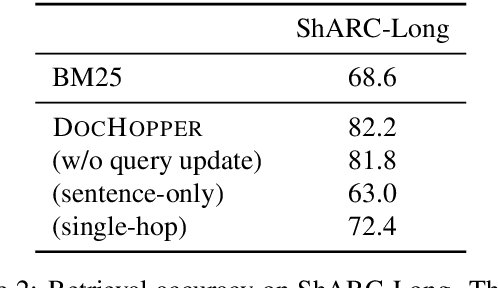
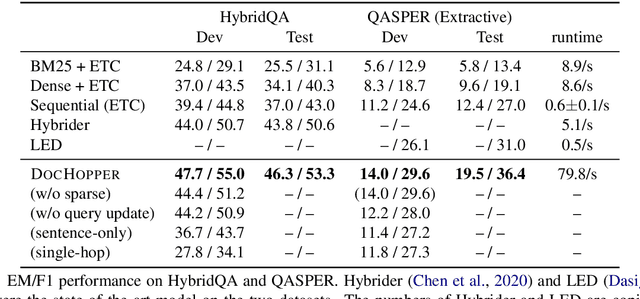
Answering complex questions from long documents requires aggregating multiple pieces of evidence and then predicting the answers. In this paper, we propose a multi-hop retrieval method, DocHopper, to answer compositional questions over long documents. At each step, DocHopper retrieves a paragraph or sentence embedding from the document, mixes the retrieved result with the query, and updates the query for the next step. In contrast to many other retrieval-based methods (e.g., RAG or REALM) the query is not augmented with a token sequence: instead, it is augmented by "numerically" combining it with another neural representation. This means that model is end-to-end differentiable. We demonstrate that utilizing document structure in this was can largely improve question-answering and retrieval performance on long documents. We experimented with DocHopper on three different QA tasks that require reading long documents to answer compositional questions: discourse entailment reasoning, factual QA with table and text, and information seeking QA from academic papers. DocHopper outperforms all baseline models and achieves state-of-the-art results on all datasets. Additionally, DocHopper is efficient at inference time, being 3~10 times faster than the baselines.
Reasoning Over Virtual Knowledge Bases With Open Predicate Relations
Feb 14, 2021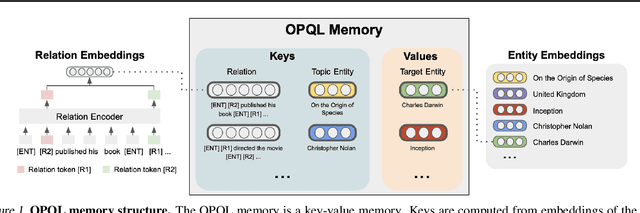
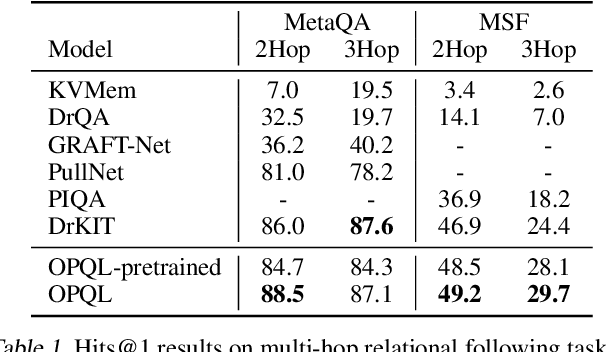
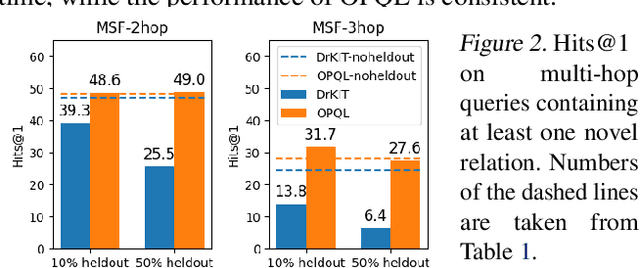
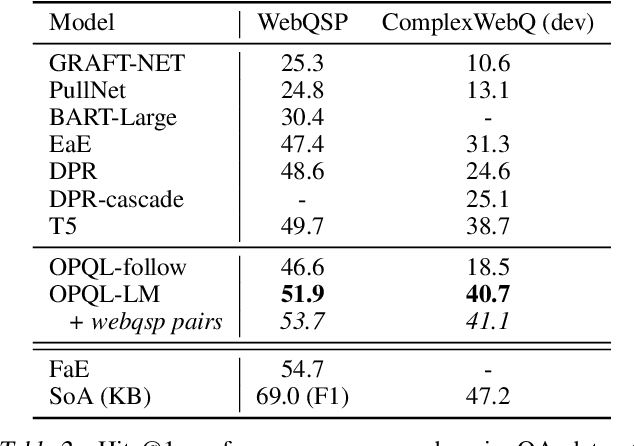
We present the Open Predicate Query Language (OPQL); a method for constructing a virtual KB (VKB) trained entirely from text. Large Knowledge Bases (KBs) are indispensable for a wide-range of industry applications such as question answering and recommendation. Typically, KBs encode world knowledge in a structured, readily accessible form derived from laborious human annotation efforts. Unfortunately, while they are extremely high precision, KBs are inevitably highly incomplete and automated methods for enriching them are far too inaccurate. Instead, OPQL constructs a VKB by encoding and indexing a set of relation mentions in a way that naturally enables reasoning and can be trained without any structured supervision. We demonstrate that OPQL outperforms prior VKB methods on two different KB reasoning tasks and, additionally, can be used as an external memory integrated into a language model (OPQL-LM) leading to improvements on two open-domain question answering tasks.
Differentiable Open-Ended Commonsense Reasoning
Oct 24, 2020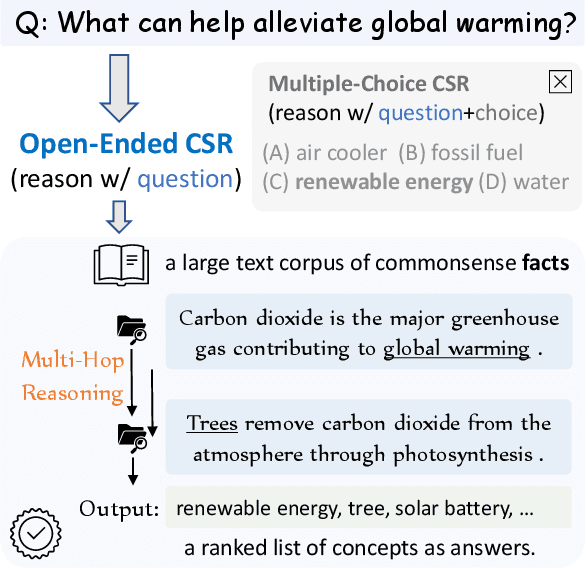
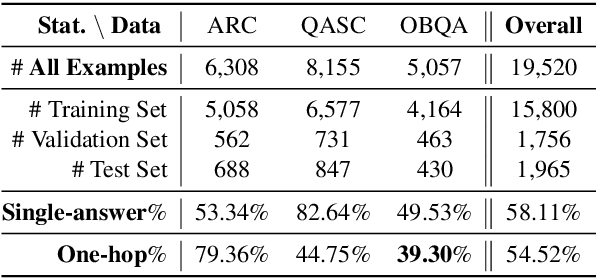

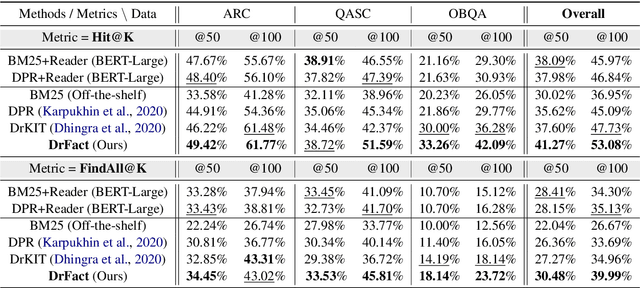
Current commonsense reasoning research mainly focuses on developing models that use commonsense knowledge to answer multiple-choice questions. However, systems designed to answer multiple-choice questions may not be useful in applications that do not provide a small list of possible candidate answers to choose from. As a step towards making commonsense reasoning research more realistic, we propose to study open-ended commonsense reasoning (OpenCSR) -- the task of answering a commonsense question without any pre-defined choices, using as a resource only a corpus of commonsense facts written in natural language. The task is challenging due to a much larger decision space, and because many commonsense questions require multi-hop reasoning. We propose an efficient differentiable model for multi-hop reasoning over knowledge facts, named DrFact. We evaluate our approach on a collection of re-formatted, open-ended versions of popular tests targeting commonsense reasoning, and show that our approach outperforms strong baseline methods by a large margin.
Facts as Experts: Adaptable and Interpretable Neural Memory over Symbolic Knowledge
Jul 02, 2020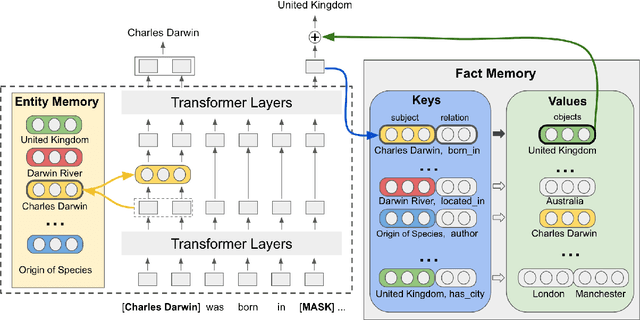
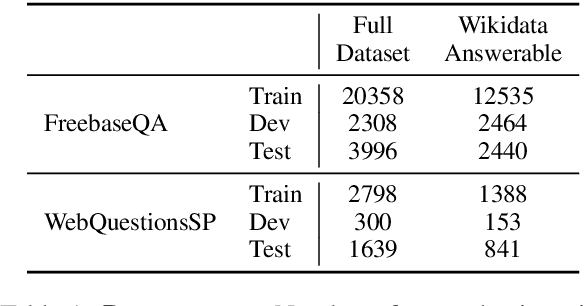
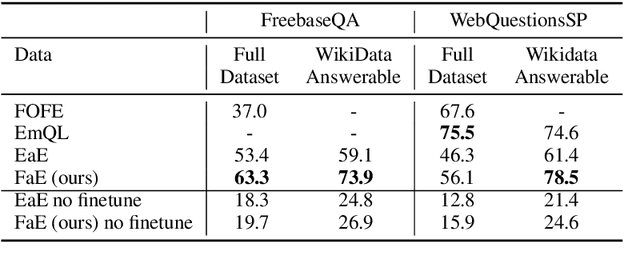

Massive language models are the core of modern NLP modeling and have been shown to encode impressive amounts of commonsense and factual information. However, that knowledge exists only within the latent parameters of the model, inaccessible to inspection and interpretation, and even worse, factual information memorized from the training corpora is likely to become stale as the world changes. Knowledge stored as parameters will also inevitably exhibit all of the biases inherent in the source materials. To address these problems, we develop a neural language model that includes an explicit interface between symbolically interpretable factual information and subsymbolic neural knowledge. We show that this model dramatically improves performance on two knowledge-intensive question-answering tasks. More interestingly, the model can be updated without re-training by manipulating its symbolic representations. In particular this model allows us to add new facts and overwrite existing ones in ways that are not possible for earlier models.